Command Palette
Search for a command to run...
STEP3-VL-10B Technical Report
STEP3-VL-10B Technical Report
Abstract
We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10imes-20imes larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
One-sentence Summary
The authors from StepFun present STEP3-VL-10B, a compact 10B-parameter multimodal foundation model that achieves state-of-the-art performance through a unified pre-training strategy with a language-aligned perception encoder and Qwen3-8B decoder, combined with a scaled post-training pipeline and Parallel Coordinated Reasoning (PaCoRe) for scalable test-time compute, enabling it to outperform models 10–20× larger on benchmarks like MM-Bench, MMMU, AIME2025, and MathVision.
Key Contributions
- STEP3-VL-10B addresses the challenge of achieving frontier-level multimodal intelligence in a compact model by introducing a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens, integrating a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy.
- The model leverages a scaled post-training pipeline with over 1,000 iterations of reinforcement learning and introduces Parallel Coordinated Reasoning (PaCoRe) to dynamically allocate test-time compute for exploring and synthesizing diverse visual hypotheses, enabling efficient perceptual reasoning.
- Despite its 10B parameter size, STEP3-VL-10B achieves state-of-the-art performance on key benchmarks—92.2% on MM-Bench, 80.11% on MMMU, 94.43% on AIME2025, and 75.95% on MathVision—surpassing models 10×–20× larger and top proprietary systems like Gemini 2.5 Pro and Seed-1.5-VL.
Introduction
The authors leverage a compact 10B-parameter architecture to challenge the prevailing assumption that high-performing multimodal reasoning requires massive model scale. While prior lightweight models sacrifice reasoning and perception capabilities, and larger models face deployment barriers due to computational demands, STEP3-VL-10B achieves frontier-level performance by combining a unified pre-training strategy on a 1.2T-token multimodal corpus with a sophisticated post-training pipeline. This includes two-stage supervised fine-tuning and over 1,000 iterations of reinforcement learning using verifiable rewards and human feedback, augmented by Parallel Coordinated Reasoning (PaCoRe) to enable multi-agent hypothesis generation and cross-checking during inference. The model surpasses significantly larger open and proprietary models on key benchmarks, demonstrating that efficient, high-capacity multimodal intelligence is attainable through targeted architectural and training innovations.
Dataset

- The dataset is constructed from multiple high-quality, domain-specific sources to support fine-grained perception and complex reasoning in STEP3-VL-10B.
- Knowledge: Combines 15M education samples (K-12 to adult learning) with multimodal data from Common Crawl, StepCrawl, and keyword-based search results. Interleaved data is filtered to exclude pages with >90% image download failures, QR codes, or extreme aspect ratios. Image-text pairs are drawn from LAION, COYO, BLIP-CCS, Zero, and augmented via keyword retrieval, text extraction from surrounding content, and CLIP-based selection. Mosaic augmentation combines four images into one to boost spatial reasoning.
- Education: Includes 15M samples across K-12 (math, science, humanities), higher education (STEM, medicine, finance), and adult exams (driving, CPA, legal). Data comes from open datasets, synthetic generation via CoSyn, and real exam materials, with supporting content from textbooks and educational websites.
- OCR: Features 10M real-world and 30M synthetic image-to-text samples using PaddleOCR and SynthDog. Document-to-text includes 80M full-page documents annotated via PaddleOCR or MinerU 2.0.
- Visual-to-Code: Covers markup (Markdown, LaTeX, Matplotlib) with 10M+ open-source and 15M+ synthetic infographics, generated with strict rendering rules. Programmatic code (TikZ, Graphviz) includes 5M reconstruction tasks from diverse visuals.
- Document-to-Code: 4M tables and 100M formulas from arXiv, enriched with open-source datasets, with careful handling of references and hyperlinks during rendering.
- Grounding & Counting: 400M samples from OpenImages, COCO, Merlin, PixMo, and in-house detection tasks; counting data derived from detection annotations.
- VQA: 10M holistic image understanding samples from open-source datasets and automatically generated QA pairs; 20M OCR-focused VQA samples from open and synthetic sources.
- GUI: 23M samples from Android, iOS, Windows, Linux, macOS apps, with joint grounding and trajectory annotations. Includes 700K UI captions, 1M knowledge VQA pairs, 2M trajectory sequences (12 atomic actions), and 19M grounding samples. Web-based GUI data includes 30M crawled pages with precise text coordinates.
- The model uses this data in a two-stage supervised fine-tuning process:
- Stage 1 (text-dominant): 9:1 text-to-multimodal ratio, 190B tokens, focused on logical and linguistic reasoning.
- Stage 2 (multimodal integration): 1:1 ratio, 36B tokens, to balance visual and textual reasoning.
- Training uses a 128k sequence length, global batch size of 32, cosine learning rate with 200-step warmup (peak: 1e-4, final: 1e-5), and domain-specific sampling weights.
- Data is filtered via rule-based elimination of degenerate patterns and benchmark decontamination using exact and 64-gram matching.
- Mosaic augmentation increases input resolution and visual density, while synthetic data generation enforces rendering consistency.
- Metadata includes precise coordinates, action trajectories, and structured annotations to support grounding, layout understanding, and executable interaction modeling.
Method
The authors leverage a modular and scalable framework to develop STEP3-VL-10B, a compact yet high-performing multimodal foundation model. The overall architecture integrates a language-optimized Perception Encoder with a Qwen3-8B decoder, forming a unified vision-language backbone. The Perception Encoder, a 1.8B-parameter model, is selected for its pre-aligned linguistic features, which enhance convergence during training. This visual encoder is connected to the decoder through a projector that performs 16× spatial downsampling via two consecutive stride-2 layers, effectively compressing visual tokens while preserving critical information. To capture fine-grained details, the model employs a multi-crop strategy, decomposing input images into a 728×728 global view and multiple 504×504 local crops. This design exploits batch-dimension parallelism, avoiding the complexity of variable-length packing. Spatial structure is encoded by appending newline tokens to patch rows, and positional modeling is achieved using standard 1D RoPE, as advanced variants offered no significant gains in the authors' setup.
The pre-training phase is designed to establish a strong foundation by focusing on data quality and architectural synergy. The model is trained on a corpus of 1.2T multimodal tokens using a fully unfrozen strategy, enabling intrinsic vision-language synergy. Following pre-training, a scaled post-training pipeline is employed, featuring over 1k iterations of reinforcement learning. This pipeline is structured in three stages to progressively enhance the model's capabilities. The first stage, Reinforcement Learning with Verifiable Rewards (RLVR), focuses on establishing robust logical foundations on tasks with accessible ground truth. It leverages a diverse set of verifiable multimodal tasks from open-source datasets and internal educational resources. A multi-dimensional filtration pipeline ensures high-quality supervision: checkability is enforced by GPT-OSS-120B performing four independent verification passes, visual relevance is ensured by an early version of STEP3-VL-10B, and difficulty is controlled by identifying "some-accept" samples through 24 rollouts per prompt. This stage runs for 600 iterations with a maximum sequence length of 24k.
The second stage, Reinforcement Learning from Human Feedback (RLHF), aligns the model with human preferences on open-ended, uncheckable tasks. It uses curated prompts from open-source arena datasets and internal instruction pools, with high-quality reference responses generated by stronger internal models serving as anchors. This stage proceeds for 300 iterations with a maximum sequence length of 32k, refining conversational and alignment capabilities while preserving underlying reasoning strength.
The third stage, further scaling via Parallel Coordinated Reasoning (PaCoRe), allocates compute to explore diverse perceptual hypotheses in parallel and synthesize them into a unified conclusion. Training data for this stage is constructed by extending the difficulty filtration from the RLVR stage. The 24 rollouts from the difficulty tagging phase are repurposed as a message cache pool. A secondary Synthesis Filtration ensures coordinated solvability by simulating the parallel reasoning process, sampling 16–24 messages from the pool as a "synthesis context" to regenerate responses, and retaining only instances that remain categorized as some-accept. This prevents task trivialization and compels the model to perform multi-perspective self-verification. The model is optimized using PPO in a strict on-policy setting for 500 iterations, utilizing a maximum sequence length of 64k to accommodate the aggregated context.
The optimization algorithm for reinforcement learning is PPO combined with GAE, which effectively balances the bias-variance trade-off in policy gradient estimation. The policy parameters are updated by maximizing a clipped surrogate objective to maintain training stability, while the value function is updated to minimize the mean squared error between the estimated value and a target value. The entire RL phase runs for 1,400 iterations, updating only the decoder while keeping the encoder frozen. The reward system is bifurcated to support scalable training across heterogeneous modalities. For verifiable tasks, it prioritizes strict correctness and reasoning consistency through perception-based rewards (e.g., IoU, Euclidean distance) and model-based verification using GPT-OSS-120B, which provides robust, parse-invariant evaluation. For non-verifiable tasks, it relies on learned preference models and behavioral regularization, including language consistency penalties, citation verification, and epistemic calibration penalties, to guide alignment and enforce safety constraints.
Experiment
- Conducted a two-phase training recipe with 1.2T tokens, using AdamW optimizer and a scaled learning rate schedule, to balance representation learning and fine-grained perceptual/ reasoning capability consolidation.
- Implemented a two-stage post-training pipeline: Supervised Finetuning followed by Proximal Policy Optimization (PPO) with Generalized Advantage Estimation (GAE), enabling advanced reasoning and perception through a reward system.
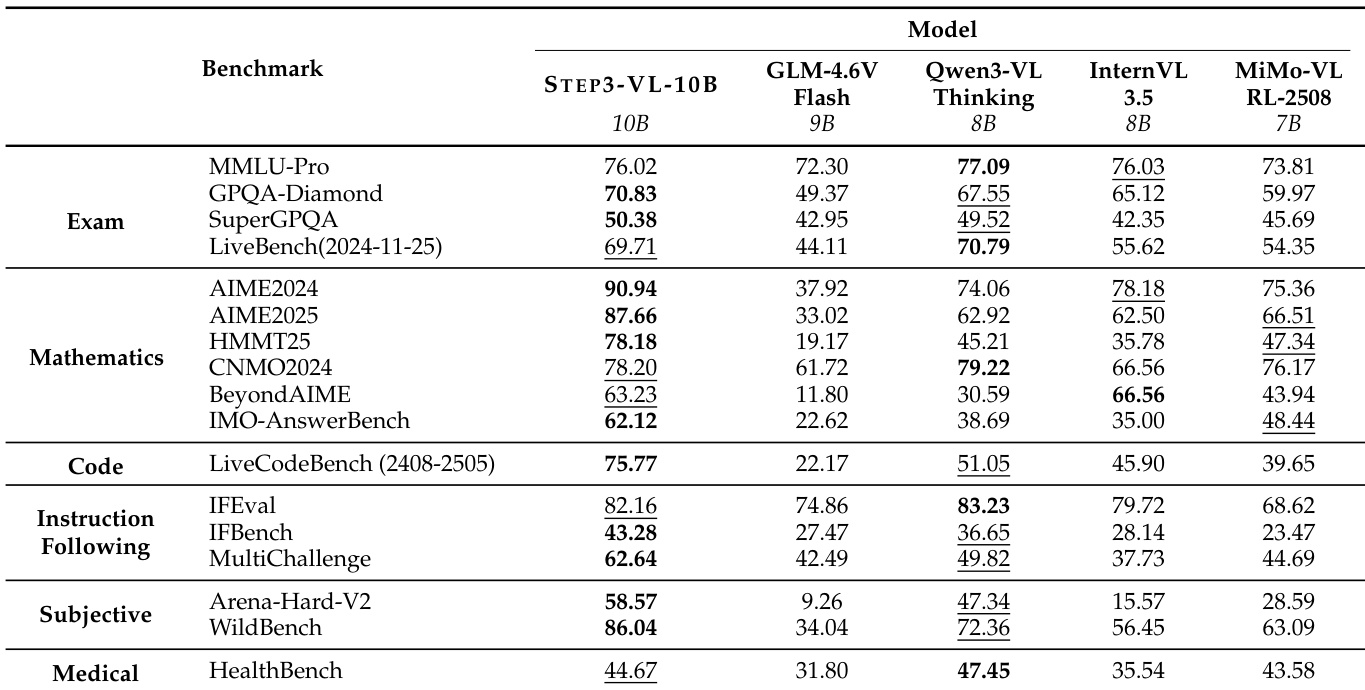
- Validated STEP3-VL-10B across over 60 multimodal and text-centric benchmarks, demonstrating state-of-the-art performance for a 10B-parameter model.
- On multimodal benchmarks, achieved 78.11% on MMMU (Standard), 92.05% on MMBench (EN), 86.75% on OCRBench, 92.61% on ScreenSpot-V2, and 89.35% on AI2D, outperforming 7–10B open-source models and rivaling larger proprietary systems.
- On text-centric benchmarks, attained 62.12% on IMO-AnswerBench, 75.77% on LiveCodeBench, and 94.43% on AIME 2025, showing strong reasoning and code generation capabilities.
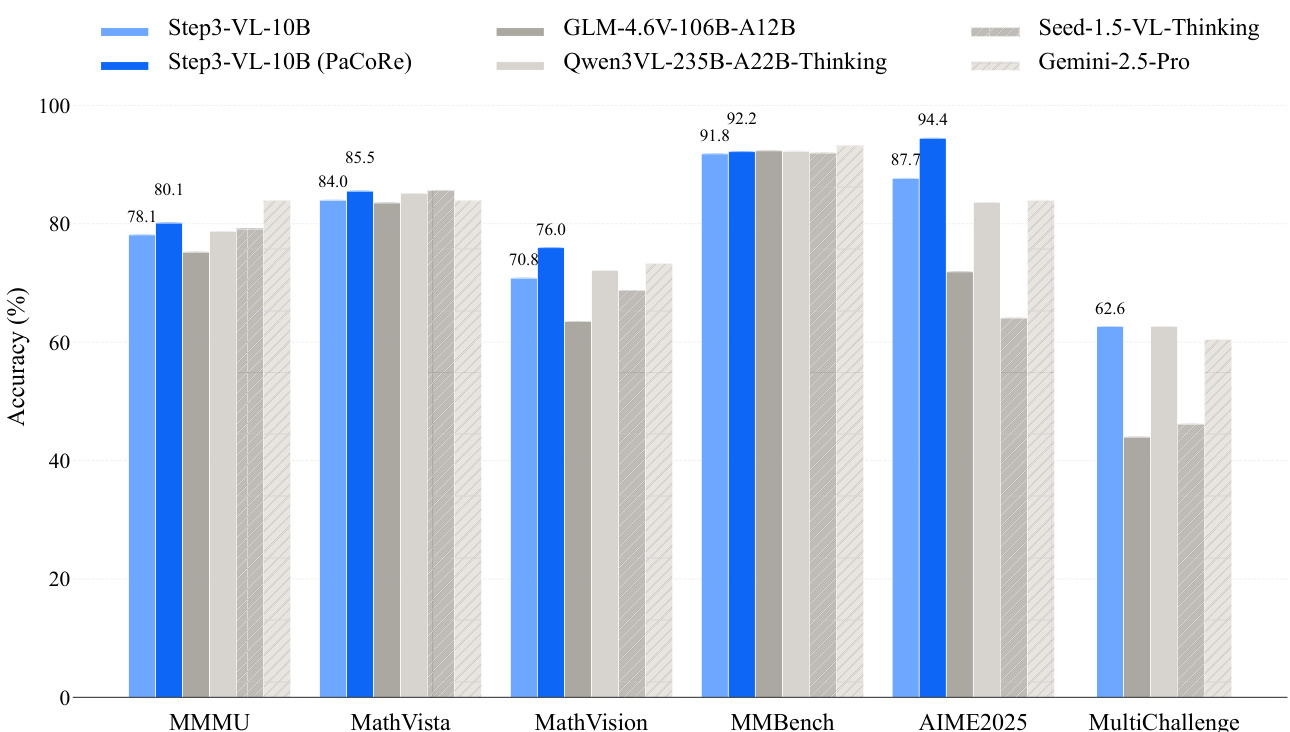
- With Parallel Coordinated Reasoning (PaCoRe), surpassed Sequential Reasoning (SeRe) mode, achieving 80.11% on MMMU, 85.50% on MathVista, 92.17% on MMBench (avg.), and 92.14% on HMMT25, demonstrating that model intelligence is not strictly limited by size.
- Ablation studies confirmed the superiority of the PE-lang vision encoder over DINOv3 and the effectiveness of AdamW over Muon, while Deepstack provided no downstream benefit despite faster convergence.
Results show that STEP3-VL-10B achieves top performance across multiple text-centric benchmarks, outperforming other open-source models in exams, mathematics, and code tasks. It demonstrates strong capabilities in high-level reasoning, particularly on AIME and IMO benchmarks, while maintaining competitive results in instruction following and subjective evaluation.
The authors compare the performance of Muon and AdamW optimizers on multimodal benchmarks, showing that AdamW achieves higher scores across most tasks, particularly in perception and general reasoning. While Muon yields improvements in some areas like SimpleVQA, AdamW demonstrates superior overall performance and training efficiency, leading to its selection as the final optimizer.

The authors compare the performance of STEP3-VL-10B with and without the DeepStack architecture, showing that removing DeepStack leads to a slight decrease in perception tasks like BLINK and OCRBench, while improving performance in general reasoning tasks such as MMSI-Bench and ReMI. The results indicate that DeepStack provides marginal benefits in perception but may hinder performance in certain reasoning domains.

The authors use a comprehensive set of multimodal and text-centric benchmarks to evaluate STEP3-VL-10B, demonstrating that it outperforms other open-source models in the 7B–10B parameter range across most domains. Results show that STEP3-VL-10B achieves top performance on key benchmarks such as MathVision and MMBench, and its parallel coordinated reasoning mode further enhances accuracy, surpassing larger models like Gemini-2.5-Pro and Seed-1.5-VL in several tasks.
The authors compare the performance of two vision encoders, DINOv3 and PE-lang, across multiple multimodal benchmarks. Results show that PE-lang outperforms DINOv3 on most tasks, particularly achieving a significant improvement of +12.50 points on OCRBench and +4.00 points on MMVP, indicating better alignment with language models for efficient vision-language modeling.
