Command Palette
Search for a command to run...
EpiCaR: Knowing What You Don't Know Matters for Better Reasoning in LLMs
EpiCaR: Knowing What You Don't Know Matters for Better Reasoning in LLMs
Jewon Yeom Jaewon Sok Seonghyeon Park Jeongjae Park Taesup Kim
Abstract
Improving the reasoning abilities of large language models (LLMs) has largely relied on iterative self-training with model-generated data. While effective at boosting accuracy, existing approaches primarily reinforce successful reasoning paths, incurring a substantial calibration cost: models become overconfident and lose the ability to represent uncertainty. This failure has been characterized as a form of model collapse in alignment, where predictive distributions degenerate toward low-variance point estimates. We address this issue by reframing reasoning training as an epistemic learning problem, in which models must learn not only how to reason, but also when their reasoning should be trusted. We propose epistemically-calibrated reasoning (EpiCaR) as a training objective that jointly optimizes reasoning performance and calibration, and instantiate it within an iterative supervised fine-tuning framework using explicit self-evaluation signals. Experiments on Llama-3 and Qwen-3 families demonstrate that our approach achieves Pareto-superiority over standard baselines in both accuracy and calibration, particularly in models with sufficient reasoning capacity (e.g., 3B+). This framework generalizes effectively to OOD mathematical reasoning (GSM8K) and code generation (MBPP). Ultimately, our approach enables a 3X reduction in inference compute, matching the K=30 performance of STaR with only K=10 samples in capable models.
One-sentence Summary
The authors from Seoul National University propose EpiCAR, a novel training framework that jointly optimizes reasoning accuracy and calibration by incorporating explicit self-evaluation signals, enabling models to assess their own confidence and reducing overconfidence-induced model collapse; this approach achieves Pareto-superior performance on Llama-3 and Qwen-3 models, enabling a 3× reduction in inference compute while matching higher-sample performance with only K=10, particularly effective for 3B+ models in out-of-distribution mathematical reasoning and code generation.
Key Contributions
- Existing iterative self-training methods for LLM reasoning, such as STaR, improve accuracy by reinforcing correct reasoning paths but induce a calibration cost, leading to overconfident, miscalibrated predictions that fail to represent uncertainty—a phenomenon akin to model collapse in alignment.
- The authors propose Epistemically-Calibrated Reasoning (EpiCAR), a novel training objective that jointly optimizes reasoning performance and calibration by incorporating explicit self-evaluation signals within an iterative supervised fine-tuning framework, reframing reasoning as an epistemic learning problem.
- Experiments on Llama-3 and Qwen-3 models (3B+) show EpiCAR achieves Pareto-superior performance over baselines in both accuracy and calibration, enabling a 3× reduction in inference compute—matching STaR’s K=30 performance with only K=10 samples—while generalizing to out-of-distribution tasks like GSM8K and MBPP.
Introduction
Large language models (LLMs) have made significant strides in complex reasoning tasks like math and code generation, largely through iterative self-training methods such as STaR, which refine models by reinforcing correct reasoning paths. However, these approaches often lead to overconfidence and poor calibration—models become highly certain about incorrect answers—due to a positive-only feedback loop that induces model collapse, where uncertainty representation degrades. This miscalibration undermines reliability in high-stakes applications where knowing when not to trust a model is as crucial as producing correct outputs. The authors propose EpiCAR, a training objective that reframes reasoning as an epistemic learning problem by jointly optimizing reasoning accuracy and calibration. By integrating explicit self-evaluation signals into an iterative supervised fine-tuning framework, EpiCAR enables models to learn when their reasoning is trustworthy, achieving Pareto-superior performance over baselines in both accuracy and calibration, particularly in models with sufficient capacity (3B+). This approach reduces inference compute by up to 3×, matching the performance of high-sample-count methods with far fewer generations, while generalizing effectively to out-of-distribution tasks like GSM8K and MBPP.
Dataset

- The dataset comprises three public benchmarks: MATH, GSM8K, and MBPP, each selected for alignment with their intended research purposes.
- MATH and GSM8K are released under the MIT License, while MBPP is distributed under the CC-BY 4.0 License.
- MATH contains challenging high-school competition-level math problems; GSM8K includes grade-school level math word problems with multi-step reasoning; MBPP consists of programming tasks requiring code generation.
- The authors use these datasets as part of a training mixture, combining them with other data sources to support model training.
- No specific cropping or metadata construction is described; the datasets are used in their original form, with standard preprocessing applied to ensure compatibility with the model’s input format.
Method
The authors propose EPICAR, a framework designed to address the calibration cost inherent in iterative self-training by reframing reasoning training as an epistemic learning task. The core of the framework lies in an iterative dual-loop process that alternates between generating reasoning traces and optimizing a unified objective that balances problem-solving accuracy and self-evaluation. This process is detailed in Algorithm 1, which outlines the three main phases: generation, mixing, and dual-objective training. During the generation phase, the model produces multiple reasoning paths for each input question. Each generated path is evaluated for correctness, and the corresponding instance is added to either the reasoning task dataset (if correct) or the self-evaluation dataset (if incorrect). This dual-task structure ensures that the model learns not only to generate correct answers but also to assess its own confidence in those answers.
The framework internalizes the evaluation task by utilizing both correct and incorrect generations as training signals. Unlike standard iterative methods such as STaR, which discard incorrect paths, EPICAR leverages them as negative signals for the self-evaluation task. This approach is motivated by findings that reasoning models encode correctness in their hidden states, and exposure to both correct and incorrect reasoning patterns is essential for developing robust internal evaluation capabilities. By explicitly training on "no" labels for erroneous paths, the framework mitigates the alignment-induced model collapse and the resulting calibration cost, where models converge toward low-variance point estimates and lose the ability to represent uncertainty.
To ensure the integrity of the training signal, the authors introduce Adaptive Injection Decoding (AID), a stateful logits processor that enforces format compliance during decoding. This mechanism prevents formatting failures, such as missing closing braces in boxed answers, from being mislabeled as logical errors. AID dynamically monitors the decoding process, injecting rigid completion strings when necessary and enforcing format constraints to ensure that valid reasoning paths are not penalized due to parsing errors. This de-noising filter is critical for maintaining the reliability of the self-evaluation supervision, as mislabeling valid logic as incorrect would provide a catastrophic training signal.
The training objective in EPICAR is minimalist, using the standard Causal Language Modeling (CLM) loss to train the model on both reasoning tokens and self-evaluation tokens as a single continuous sequence. This intrinsic curriculum is achieved through natural mixing of reasoning and self-evaluation samples, where the proportion of negative self-evaluation samples dominates in early iterations, forcing the model to prioritize uncertainty representation. As the model's reasoning capability improves, the proportion of positive reasoning samples naturally increases, stabilizing the learning trajectory without the need for manual intervention or auxiliary coefficients. This design ensures robustness and avoids the complexity of multi-task frameworks with tuned auxiliary weights.
Experiment
- Evaluated on MATH, GSM8K (OOD), and MBPP (cross-domain) datasets using Llama-3 and Qwen-3 families; EPICAR outperforms STaR in accuracy, AUROC, ECE, and Brier Score across scales, with significant gains in 3B and 8B variants.
- On MATH-500, EPICAR with Confidence-Informed Self-Consistency (CISC) achieves 25.40% accuracy (Llama-3-8B) and 59.80% (Qwen-3-8B) at K=30, matching STaR’s K=30 performance with only K=10, demonstrating 3× inference compute reduction.
- On GSM8K (zero-shot), EPICAR improves AUROC to 0.645 (Llama-3-1B) and 0.606 (Llama-3-3B), surpassing STaR’s degradation to 0.478 and 0.491, showing enhanced discriminative reliability in OOD settings.
- On MBPP, EPICAR achieves 15.02% pass rate (Llama-3-8B), lowest ECE (+TS) of 0.113, and Brier Score of 0.246, mitigating calibration cost of STaR (AUROC drops from 0.551 to 0.523).
- EPICAR enables stable inference-time scaling: while STaR suffers reliability collapse (AUROC drops from 0.7895 to 0.7387 at K=30), EPICAR sustains or improves AUROC, suppressing consensus-driven errors.
- Synergy with model merging: Ours + Merging achieves highest Llama-3-8B accuracy (15.02%) and near-perfect ECE (+TS) of 0.018 (Qwen-3-1.7B), confirming complementary reliability signals.
- Ablation shows Adaptive Injection Decoding is critical: removing it causes accuracy collapse to 2.56% (Llama-3-8B), due to formatting noise corrupting self-evaluation.
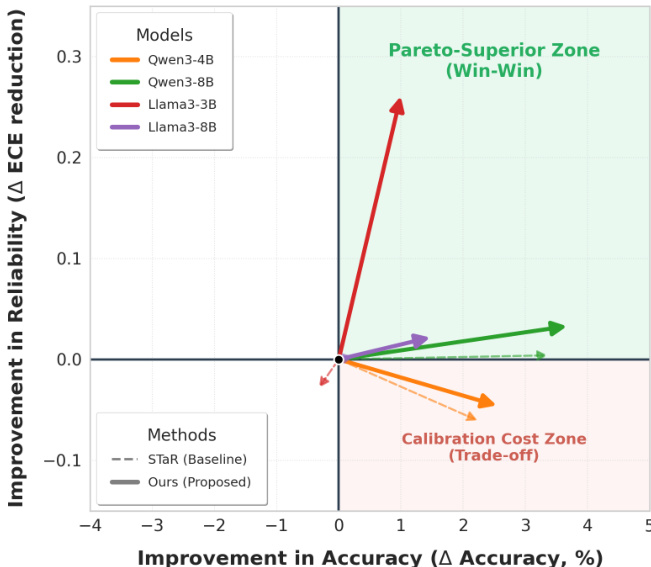
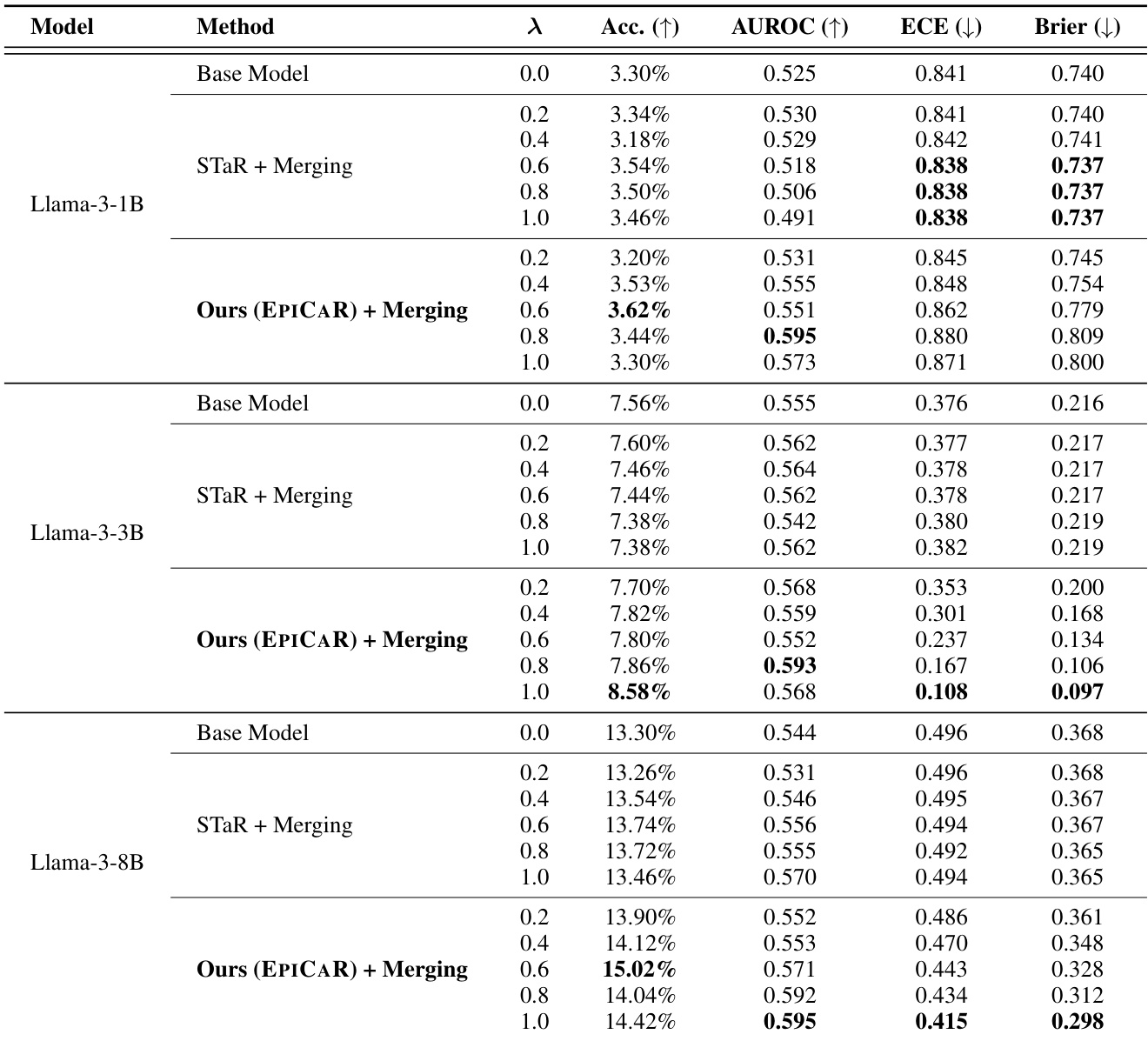
The authors use model merging to evaluate the impact of their EPICAR method on calibration and accuracy across different model scales. Results show that for Llama-3-8B, the Ours (EPICAR) + Merging approach achieves the highest accuracy (15.02%) and the lowest Brier Score (0.298), indicating superior calibration and predictive quality compared to STaR + Merging and the base model.
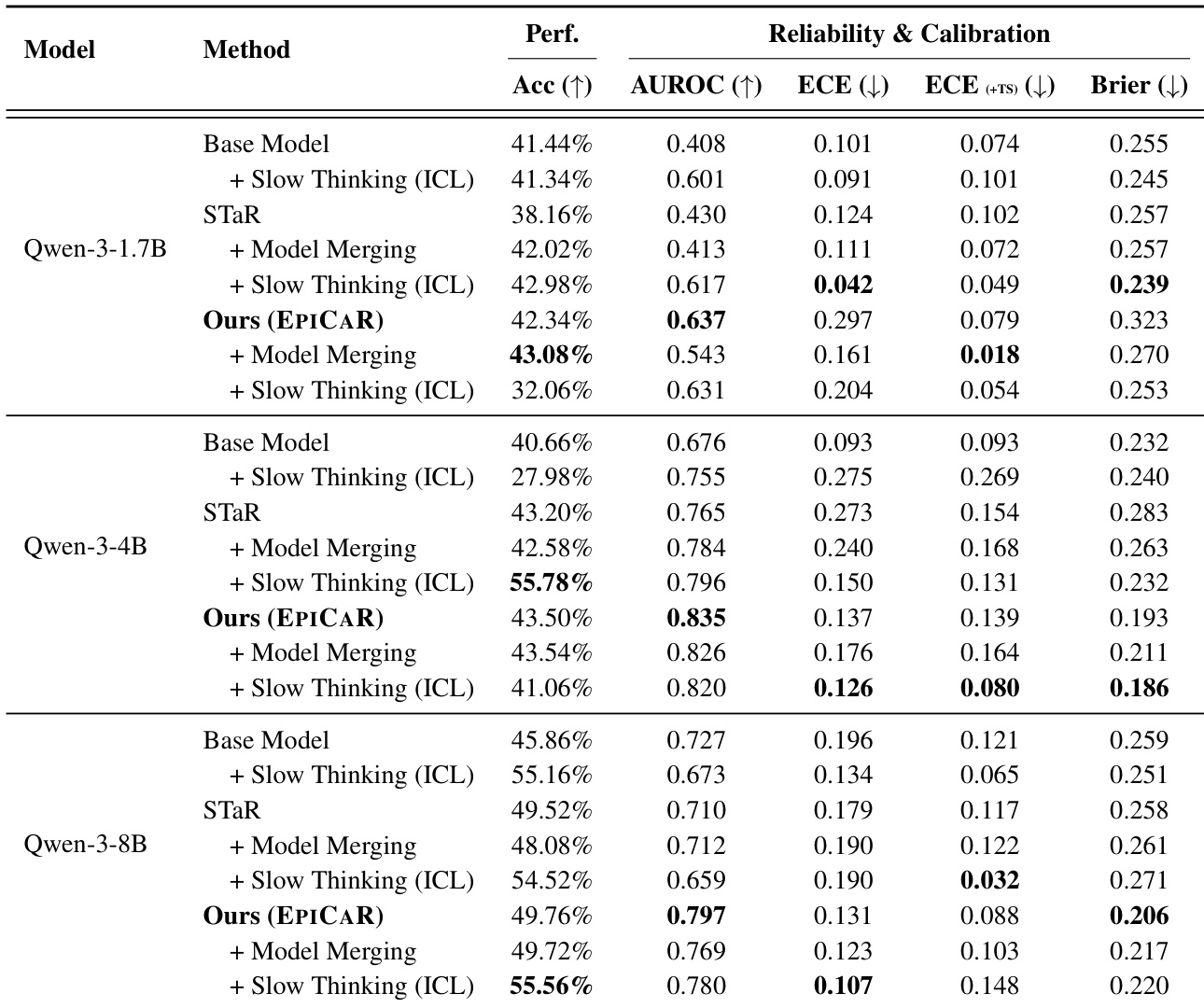
The authors use the Qwen-3 family of models to evaluate the performance and calibration of their EPICAR method against several baselines, including STaR and Slow Thinking. Results show that EPICAR consistently outperforms the baselines in both accuracy and calibration metrics, achieving the highest accuracy and AUROC across all model sizes, with the most significant improvements observed in the 4B and 8B variants.
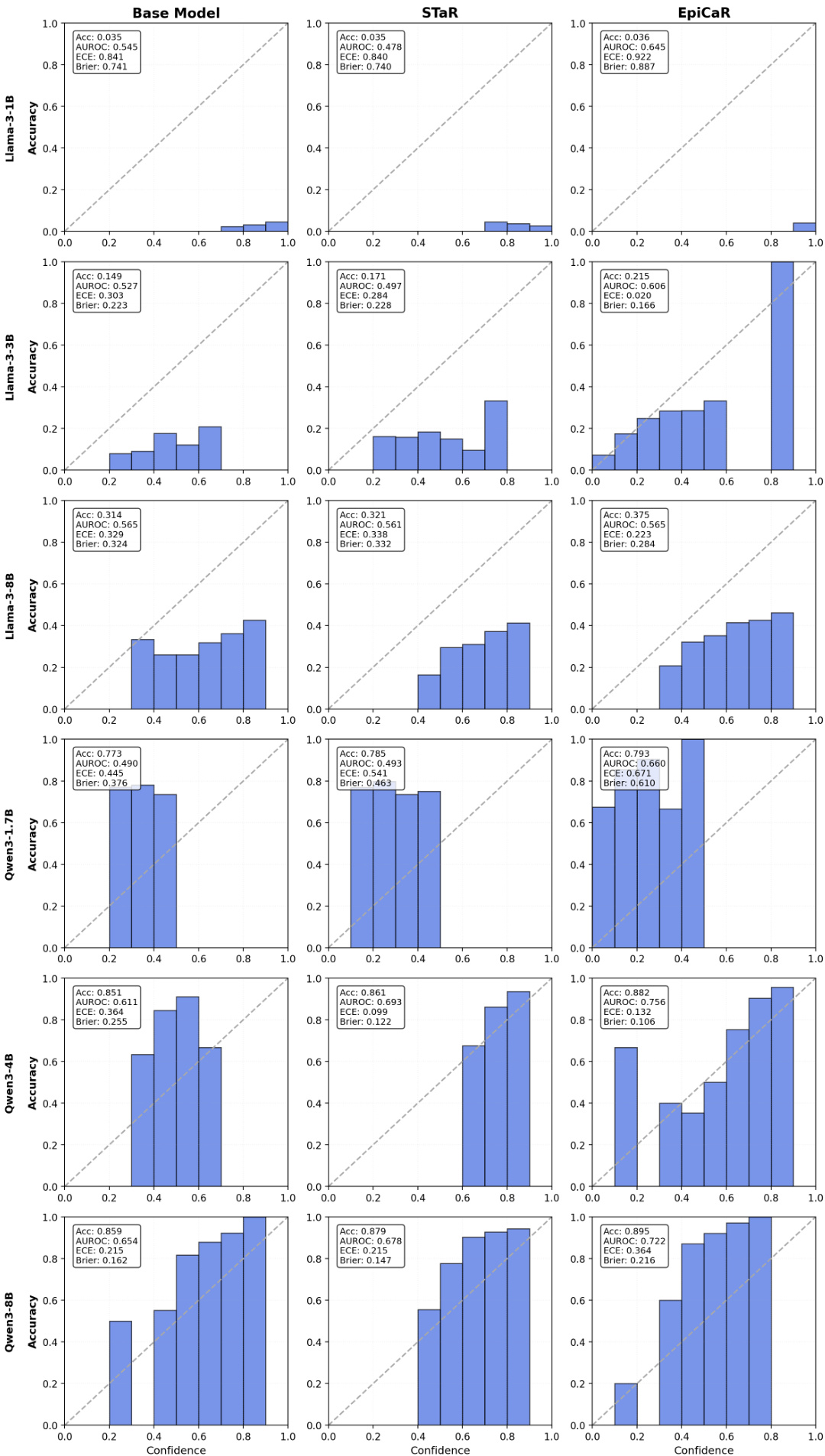
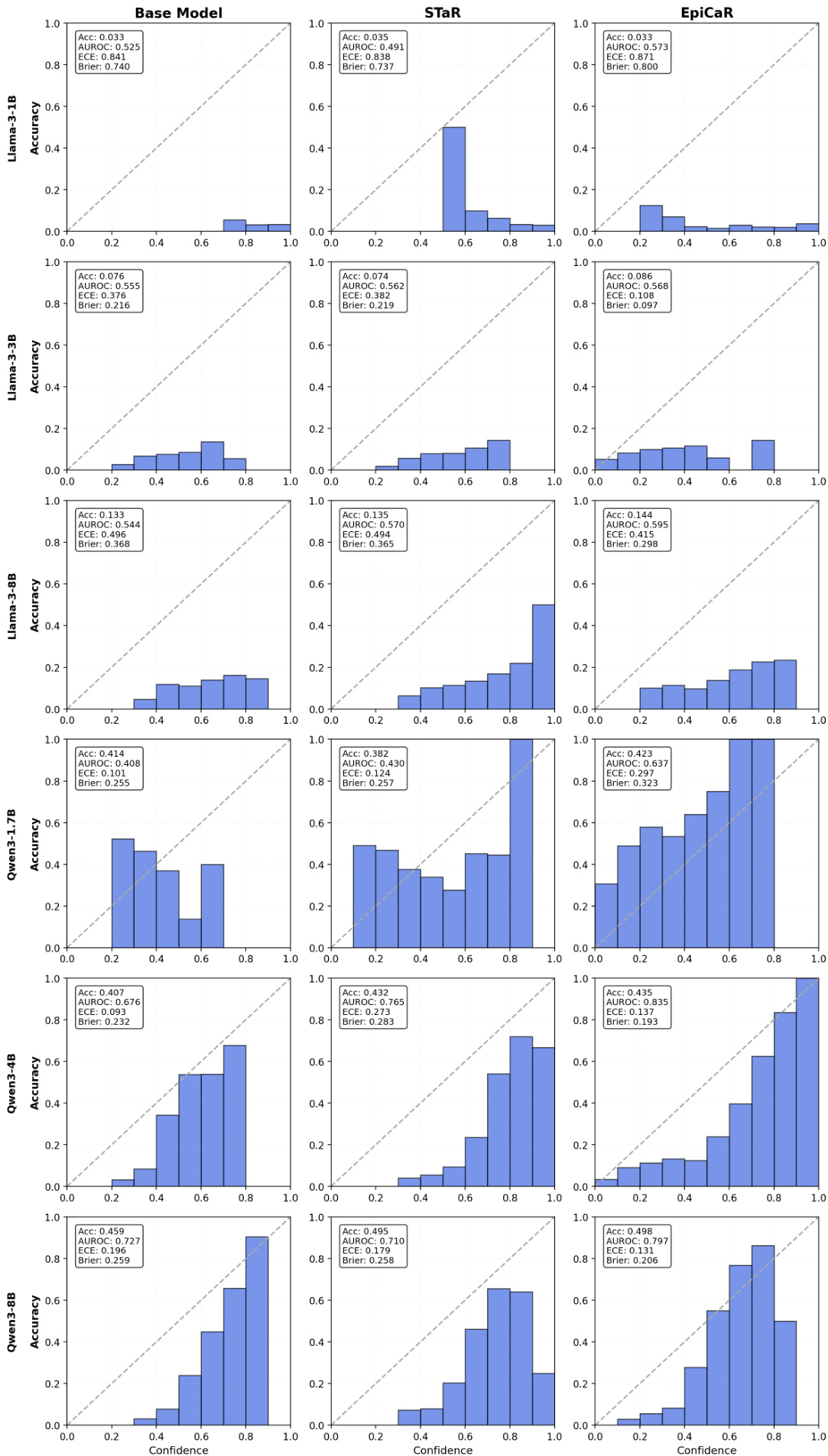
The authors use reliability diagrams to compare the calibration of the Base Model, STaR, and EpiCaR across multiple model sizes and families. Results show that EpiCaR achieves better alignment between confidence and accuracy, with lower Expected Calibration Error (ECE) and higher AUROC compared to STaR, particularly in larger models like Llama-3-8B and Qwen-3-8B.
The authors use AdamW as the optimizer with a learning rate of 1×10−5 and a cosine learning rate scheduler. The model is trained with a batch size of 32, a maximum sequence length of 2048, and LoRA parameters set to a rank of 16 and alpha of 32, with all linear layers targeted and bfloat16 precision used.
The authors use reliability diagrams to evaluate the calibration of Llama-3 and Qwen-3 models across different sizes and training methods. Results show that EpiCaR consistently improves calibration compared to the Base Model and STaR, with lower Expected Calibration Error (ECE) and higher Area Under the ROC Curve (AUROC), particularly in larger models like Qwen-3-8B. The method achieves better alignment between confidence and accuracy, reducing overconfidence and enhancing discriminative reliability.