Command Palette
Search for a command to run...
BabyVision: Visual Reasoning Beyond Language
BabyVision: Visual Reasoning Beyond Language
Abstract
While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
One-sentence Summary
The authors from UniPat AI, Peking University, Tsinghua University, and collaborating institutions propose BABYVISION, a benchmark assessing core visual abilities in multimodal LLMs independent of language, revealing that even top models like Gemini3-Pro-Preview lag behind 6-year-old humans; the work introduces BABYVISION-GEN and an automatic evaluation toolkit to advance visual reasoning in generation models, marking a step toward human-level visual perception.
Key Contributions
-
The paper introduces BABYVISION, a benchmark comprising 388 items across 22 subclasses in four domains—Fine-grained Discrimination, Visual Tracking, Spatial Perception, and Visual Pattern Recognition—designed to evaluate core visual abilities in multimodal LLMs independent of linguistic knowledge, revealing a significant performance gap between current models and human infants and children.
-
The study demonstrates that state-of-the-art MLLMs, including Gemini3-Pro-Preview, achieve only 49.7% accuracy on BABYVISION, far below human benchmarks (6-year-olds: ~70%, adults: 94.1%), exposing a critical deficiency in foundational visual primitives despite strong performance on language-heavy multimodal tasks.
-
To address the visual reasoning gap, the authors propose BABYVISION-GEN, a generative evaluation framework that assesses visual reasoning through image and video generation, paired with an automatic evaluation toolkit achieving 96% agreement with human judgments, and show that generative models can outperform MLLMs on certain visual tasks.
Introduction
Contemporary Multimodal Large Language Models (MLLMs) excel at high-level, knowledge-intensive tasks such as mathematical reasoning and expert-level question answering, yet they consistently fail on basic visual reasoning tasks that even 3-year-old children can solve without language. This gap highlights a critical limitation: current models lack foundational visual primitives—such as object tracking, spatial perception, and fine-grained discrimination—that emerge early in human development and are independent of linguistic knowledge. Prior benchmarks have largely focused on semantic or expert-level reasoning, failing to systematically evaluate these pre-linguistic visual abilities, which leads to an overestimation of model robustness in real-world perception.
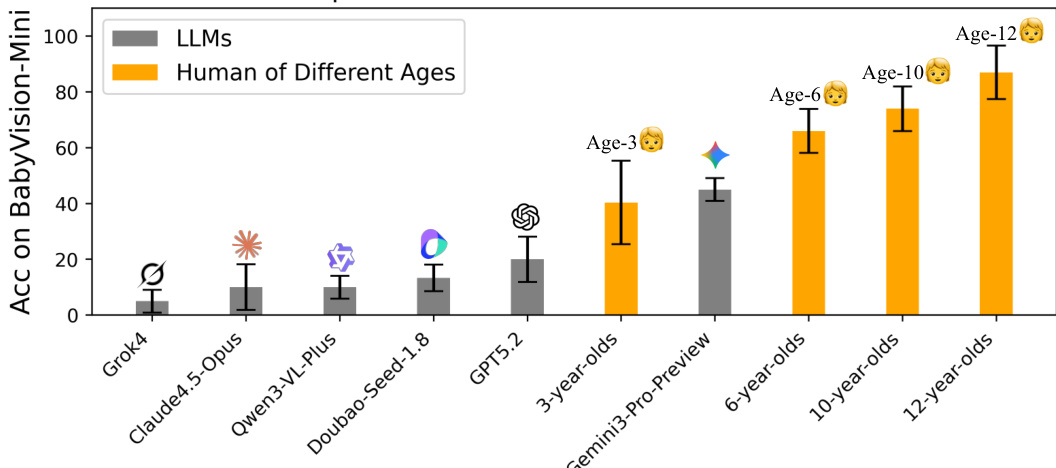
The authors introduce BABYVISION, a rigorous benchmark designed to assess core visual reasoning in MLLMs without relying on language. It comprises 388 tasks across four domains—Fine-grained Discrimination, Visual Tracking, Spatial Perception, and Visual Pattern Recognition—structured to mirror early human visual development. Evaluation reveals a stark performance gap: the best MLLM, Gemini3-Pro-Preview, scores only 49.7% compared to 94.1% for adult humans, with significant failures in tracking and spatial reasoning due to a "verbalization bottleneck" that discards non-verbalizable visual information.
To address this, the authors propose BABYVISION-GEN, a generative extension that evaluates visual reasoning through image or video output rather than text, enabling models to express solutions via visual means like tracing paths or completing patterns. They also develop an automatic evaluation toolkit with 96% agreement to human judgments. Experiments show that frontier generation models like Sora-2 and Nano-Banana-Pro demonstrate human-like visual thinking, suggesting that native multimodal architectures—those that reason directly in visual space—may be key to achieving truly grounded visual intelligence.
Dataset

- The BABYVISION benchmark consists of 388 carefully curated visual reasoning questions designed to evaluate foundational early-vision skills in Multimodal Large Language Models (MLLMs), grounded in developmental psychology and organized into four core categories: Fine-grained Discrimination (8 subtypes), Visual Tracking (5 subtypes), Spatial Perception (5 subtypes), and Visual Pattern Recognition (4 subtypes), totaling 22 subtypes.
- The dataset was constructed through a three-stage curation pipeline: (1) Taxonomy definition and seed selection, where 100 high-quality seed images were manually chosen to represent each subtype; (2) Data collection and filtering, using reverse image search and keyword-based retrieval to gather ~4,000 candidate images, with strict filtering for text, cultural knowledge, and inappropriate content; and (3) Annotation and quality assurance, where trained annotators created questions and detailed solution processes, followed by double-blind expert review to ensure answers are visually grounded and unambiguous.
- Final dataset composition includes 135 multiple-choice questions (34.8%) and 253 fill-in-the-blank questions (65.2%), with an average length of 25.9 words, balanced answer distributions, and strong visual grounding to prevent language-based shortcuts.
- A supplementary training set of 1,400 examples was created using the same pipeline but with broader data sourcing to study the impact of training on model performance on BABYVISION.
- BABYVISION-GEN, a generation-focused adaptation, includes 280 questions across 21 subtypes from the same four categories, excluding one subtype incompatible with visual generation. Each instance includes an original image, a generation prompt (avg. 22.9 words), and a reference solution image based on consensus from three human annotators.
- Questions are evaluated using strict criteria: for example, in "Find the Same," all marked elements must exactly match the ground truth; in "Maze," the path must follow the exact same route; in "Count Same Patterns," the count must match precisely.
- The authors use the BABYVISION dataset for evaluation, with a focus on testing visual reasoning capabilities, while BABYVISION-GEN is used to assess visual generation models’ ability to produce solutions through image synthesis rather than verbal answers.
Method
The authors leverage a structured three-phase framework for constructing the BABYVISION-GEN dataset, which emphasizes systematic taxonomy development, scalable data collection, and rigorous quality control. The process begins with taxonomy and seed collection, where the scope of early vision tasks is defined using textbooks and visual tests. This phase establishes four top-level categories and 22 subtypes, culminating in the manual selection of approximately 50 seed images that serve as foundational examples for subsequent data generation.
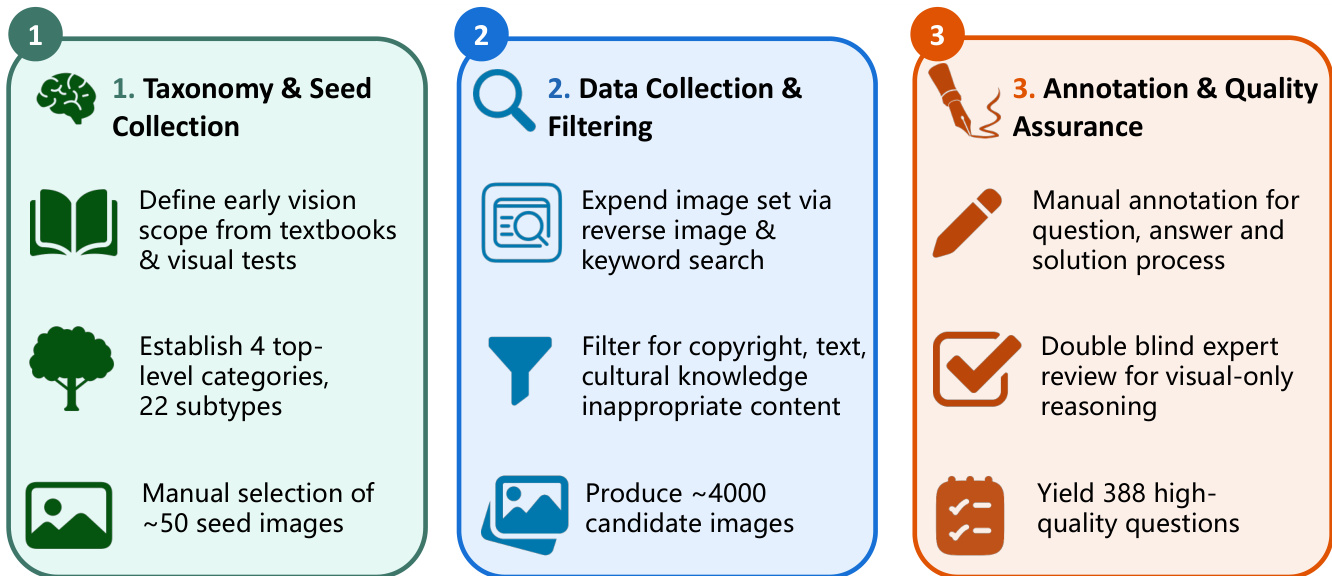
As shown in the figure below, the second phase focuses on data collection and filtering. The image set is expanded through reverse image search and keyword-based queries to generate a large pool of candidate images. This raw collection undergoes filtering to remove content that violates copyright, contains inappropriate text, or involves culturally sensitive material. The result is a curated set of approximately 4,000 candidate images suitable for downstream annotation.
The final phase, annotation and quality assurance, ensures the reliability and clarity of the dataset. Each question, answer, and solution process is manually annotated to preserve the original image context while adding only the necessary visual marks—such as circles, lines, arrows, or text labels—to indicate the solution. A double-blind expert review process is applied specifically to assess visual-only reasoning tasks, ensuring that annotations are accurate and minimal. This phase yields 388 high-quality questions, each accompanied by a precise visual solution.
Experiment
- Evaluated 11 frontier models (5 proprietary, 6 open-source) on BabyVision and BabyVision-GEN using standardized prompts and LLM-as-judge evaluation with Qwen3-Max and Gemini-3-Flash, achieving 100% consistency with human evaluators on BabyVision and 96.1% agreement on BabyVision-GEN.
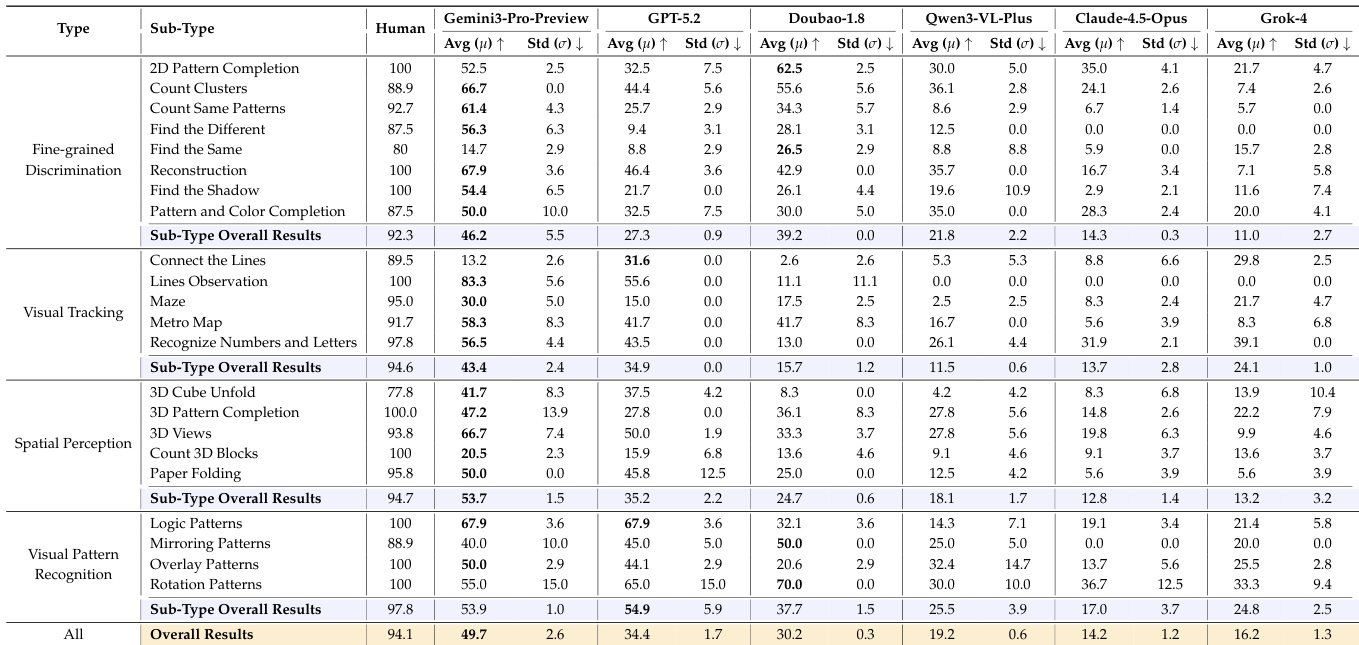
- On BabyVision, proprietary models achieved up to 49.7% Avg@3 (Gemini3-Pro-Preview), far below human baseline (94.1%), with persistent failures in fine-grained discrimination (best: 26.5% on Find the Same), visual tracking (near-zero on Lines Observation), and 3D spatial perception (best: 20.5% on Count 3D Blocks).
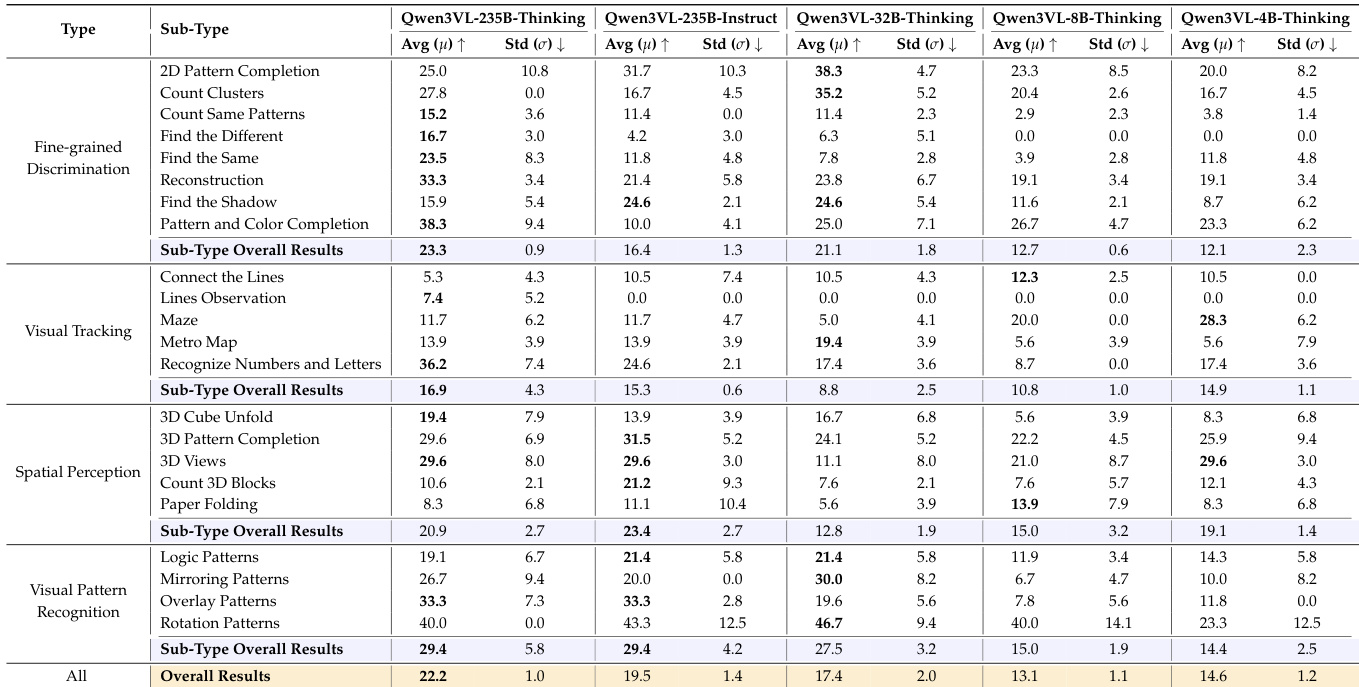
- Open-source models showed lower performance (best: 22.2% for Qwen3VL-235B-Thinking), with test-time thinking providing measurable gains over Instruct variants, but still significantly behind proprietary models.
- Model scaling improved performance in the Qwen3VL family (235B-Thinking: 22.2% vs. 4B-Thinking: 14.6%), though gains were non-monotonic, indicating limitations of scaling alone for early-vision tasks.
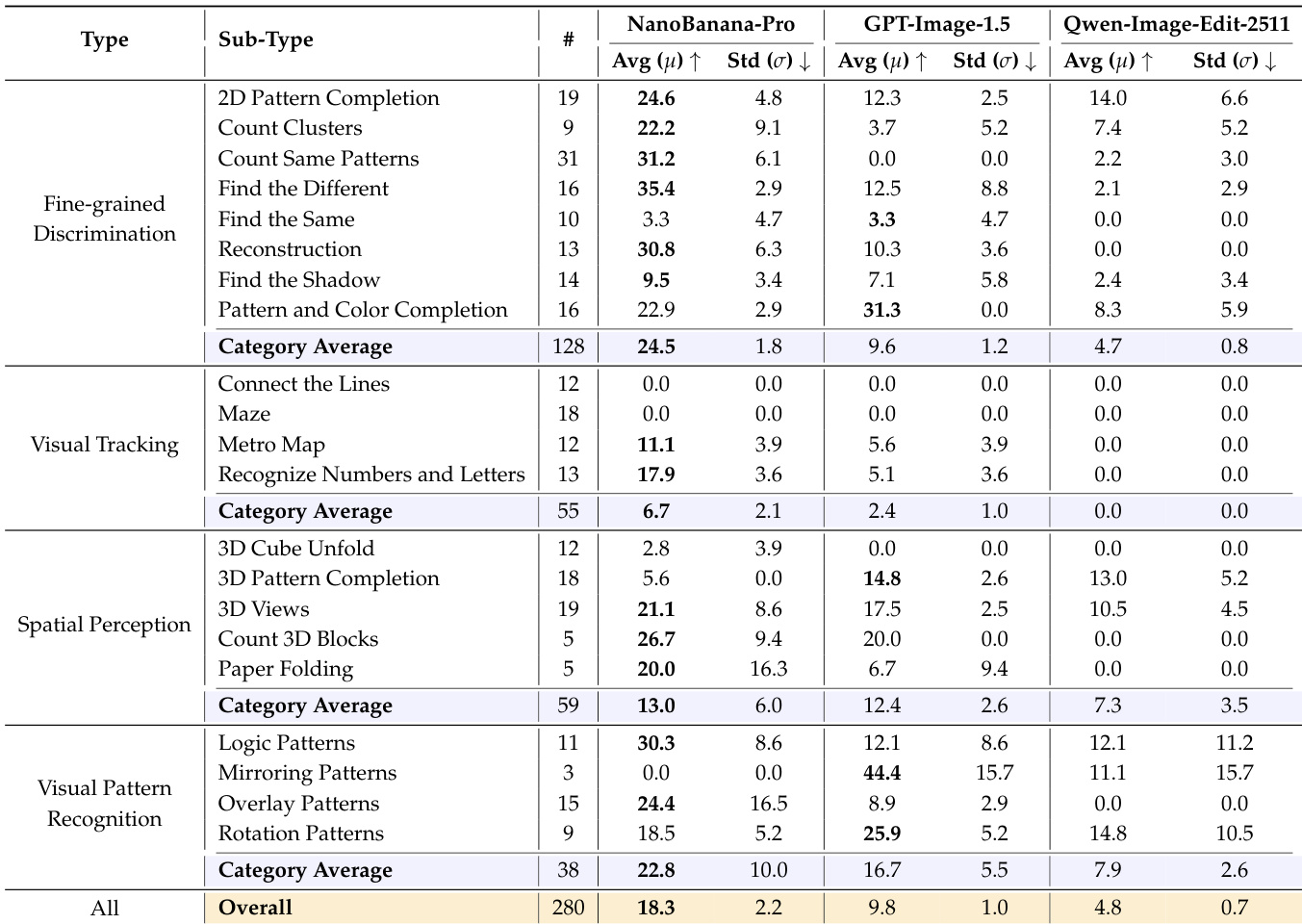
- On BabyVision-GEN, NanoBanana-Pro achieved 18.3% accuracy, outperforming GPT-Image-1.5 (9.8%) and Qwen-Image-Edit (4.8%), with strong results in Fine-grained Discrimination (24.5%) and Visual Pattern Recognition (22.8%), but near-zero accuracy on visual tracking tasks (Maze, Connect the Lines).
- RLVR fine-tuning of Qwen3-VL-8B-Thinking improved BabyVision accuracy by +4.8 points overall, with gains across most subtypes, though visual tracking showed little improvement, highlighting the challenge of continuous perceptual tracking in language-based reasoning.
- Qualitative analysis revealed a "verbalization bottleneck" where MLLMs fail on tasks requiring non-verbal, fine-grained visual perception, manifold identity tracking, 3D spatial imagination, and visual pattern induction due to lossy compression of visual information into language.
The authors evaluate three visual generation models on the BABYVISION-GEN benchmark, with NanoBanana-Pro achieving the highest overall accuracy at 18.3%, significantly outperforming GPT-Image-1.5 (9.8%) and Qwen-Image-Edit (4.8%). Results show that all models struggle with tasks requiring continuous spatial tracking, such as maze navigation and line tracing, where accuracy drops to 0%, while performance is stronger in fine-grained discrimination and visual pattern recognition subtypes.
The authors evaluate the reliability of their automatic evaluation method for BABYVISION-GEN by comparing it against human judgments. The results show that the automatic judge agrees with human evaluators on 96.1% of instances, with a high F1 score of 0.924, indicating strong consistency between the two evaluation approaches.

The authors use a unified prompt template and LLM-as-judge evaluation to assess model performance on the BabyVision benchmark, with results showing that proprietary models like Gemini3-Pro-Preview achieve the highest scores but still fall significantly below human performance. The table reveals that no model consistently outperforms humans across all subtypes, with the largest gaps observed in fine-grained discrimination and visual tracking tasks, indicating persistent challenges in foundational visual reasoning.
The authors use the table to compare the performance of different Qwen3VL models across various visual reasoning tasks, focusing on the impact of model size and reasoning mode. Results show that the Thinking variant consistently outperforms the Instruct variant at the same scale, and performance generally improves with model size, though the 4B-Thinking model slightly exceeds the 8B-Thinking model, indicating non-monotonic scaling effects.
The authors use a benchmark called BabyVision to evaluate visual reasoning capabilities of large language models (LLMs) and compare them to human performance across different age groups. Results show that even the best-performing LLM, Gemini3-Pro-Preview, achieves an accuracy of 44.1%, which is significantly below the performance of 6-year-old children and far from the 94.1% accuracy of 12-year-olds.