Command Palette
Search for a command to run...
Chaining the Evidence: Robust Reinforcement Learning for Deep Search Agents with Citation-Aware Rubric Rewards
Chaining the Evidence: Robust Reinforcement Learning for Deep Search Agents with Citation-Aware Rubric Rewards
Jiajie Zhang Xin Lv Ling Feng Lei Hou Juanzi Li
Abstract
Reinforcement learning (RL) has emerged as a critical technique for enhancing LLM-based deep search agents. However, existing approaches primarily rely on binary outcome rewards, which fail to capture the comprehensiveness and factuality of agents' reasoning process, and often lead to undesirable behaviors such as shortcut exploitation and hallucinations. To address these limitations, we propose Citation-aware Rubric Rewards (CaRR), a fine-grained reward framework for deep search agents that emphasizes reasoning comprehensiveness, factual grounding, and evidence connectivity. CaRR decomposes complex questions into verifiable single-hop rubrics and requires agents to satisfy these rubrics by explicitly identifying hidden entities, supporting them with correct citations, and constructing complete evidence chains that link to the predicted answer. We further introduce Citation-aware Group Relative Policy Optimization (C-GRPO), which combines CaRR and outcome rewards for training robust deep search agents. Experiments show that C-GRPO consistently outperforms standard outcome-based RL baselines across multiple deep search benchmarks. Our analysis also validates that C-GRPO effectively discourages shortcut exploitation, promotes comprehensive, evidence-grounded reasoning, and exhibits strong generalization to open-ended deep research tasks. Our code and data are available at https://github.com/THUDM/CaRR.
One-sentence Summary
The authors from Tsinghua University and Zhipu AI propose CaRR, a citation-aware reward framework that enhances deep search agents by enforcing comprehensive, factually grounded reasoning through verifiable rubrics and evidence chains, combined with C-GRPO for training, significantly reducing hallucinations and shortcut exploitation while improving performance across benchmarks.
Key Contributions
- Existing reinforcement learning approaches for deep search agents rely solely on binary outcome rewards, which fail to penalize shortcut exploitation and hallucinations, leading to brittle and factually unreliable reasoning despite correct final answers.
- The authors propose Citation-aware Rubric Rewards (CaRR), a fine-grained reward framework that decomposes complex questions into verifiable single-hop rubrics, requiring agents to identify hidden entities, support claims with correct citations, and form complete evidence chains linking to the final answer.
- Their method, Citation-aware Group Relative Policy Optimization (C-GRPO), combines CaRR with outcome rewards and demonstrates consistent improvements over baseline RL methods on multiple deep search benchmarks, reducing shortcut behaviors and enhancing generalization to open-ended research tasks.
Introduction
The authors leverage reinforcement learning (RL) to improve LLM-based deep search agents that navigate the web to solve complex, knowledge-intensive questions. While prior work relies on binary outcome rewards—indicating only whether the final answer is correct—this approach fails to assess reasoning quality, enabling agents to exploit shortcuts or hallucinate answers without penalty. To address this, the authors introduce Citation-aware Rubric Rewards (CaRR), a fine-grained reward framework that evaluates agents based on three criteria: identification of hidden entities, factual support via citations, and construction of a complete evidence chain linking to the answer. They further propose Citation-aware Group Relative Policy Optimization (C-GRPO), which combines CaRR with outcome rewards to train agents that are both accurate and robust. Experiments show C-GRPO outperforms outcome-only baselines across multiple benchmarks, reduces shortcut exploitation, and generalizes well to open-ended research tasks.
Dataset

- The dataset comprises publicly available, openly licensed models and data sources, ensuring transparency and compliance with ethical guidelines.
- It includes multiple subsets drawn from diverse domains, each selected for relevance and quality, with clear provenance and licensing information.
- Each subset is characterized by its size, source, and specific filtering rules—such as language constraints, content quality thresholds, and duplication removal—to ensure data integrity.
- The authors use the dataset to train their model, combining subsets in a carefully designed mixture ratio that balances coverage, diversity, and task relevance.
- Data is processed through standardized tokenization and cleaning, with a cropping strategy applied to limit sequence length while preserving contextual coherence.
- Metadata is constructed to track provenance, source distribution, and filtering steps, enabling reproducibility and auditability.
Method
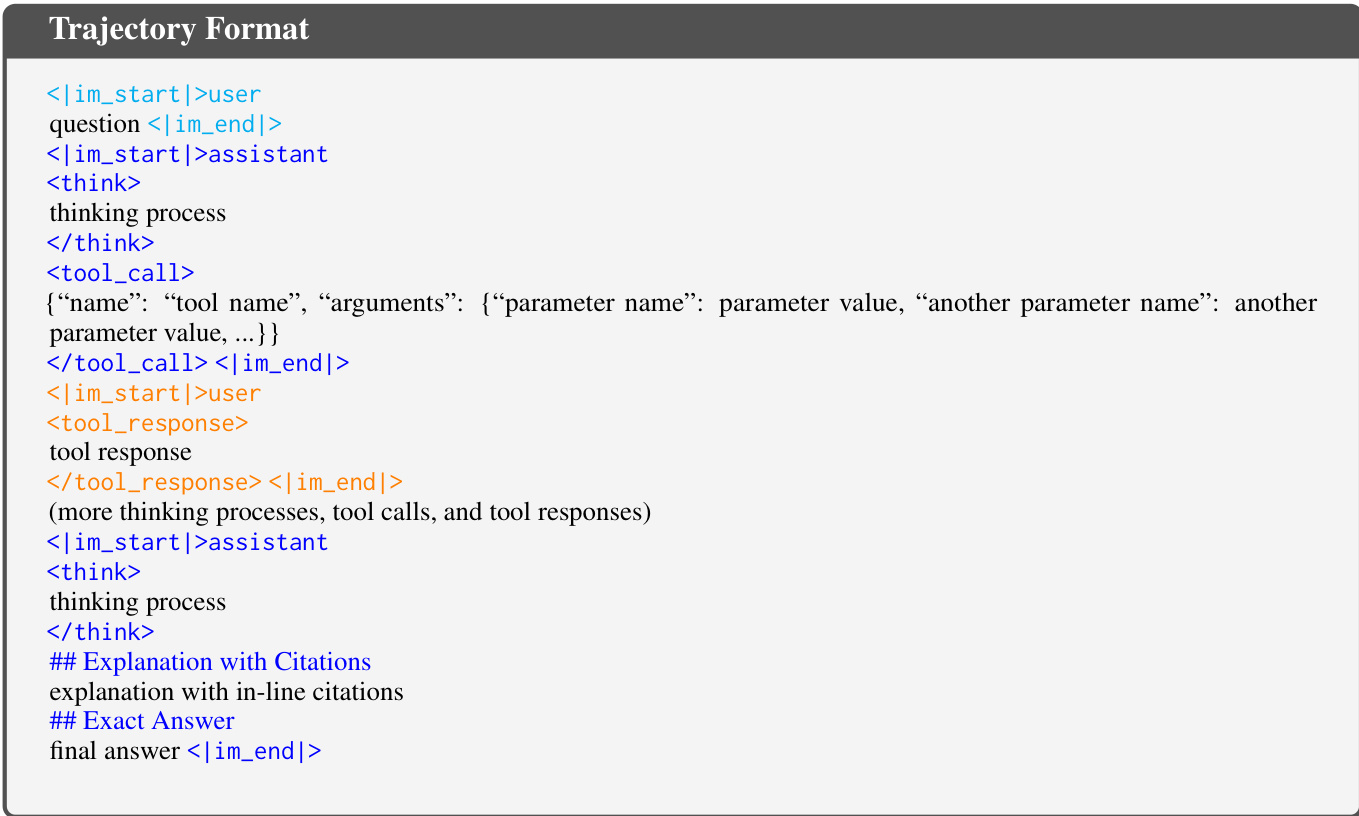
The authors leverage the ReAct paradigm for deep search agents, where an LLM-based agent iteratively performs thinking, action, and observation steps to solve a question. A complete trajectory H consists of a sequence of these steps, with the final action aT being the agent's response, which includes an explanation with citations and the final answer. The agent can perform three types of actions: a search tool to retrieve relevant webpages, an open tool to access a specific URL, and a find tool to extract content matching a keyword from an opened page. The trajectory format is defined with specific tags for user input, assistant thinking, tool calls, and the final response, which must include an explanation with citations and the exact answer.
The core of the proposed method is the Citation-aware Rubric Rewards (CaRR) framework, which provides fine-grained rewards based on reasoning comprehensiveness, factual grounding, and evidence connectivity. This framework operates in three main stages. First, during rubric initialization, a large language model (LLM) is prompted to decompose a complex multi-hop question into a list of atomic factual statements, each involving hidden entities that must be found to solve the question. These statements serve as verifiable rubrics. The hidden entities are denoted by placeholders like , and the final answer is . This process is illustrated in the figure below, where a question is decomposed into a set of rubrics, each representing a necessary fact to be discovered.
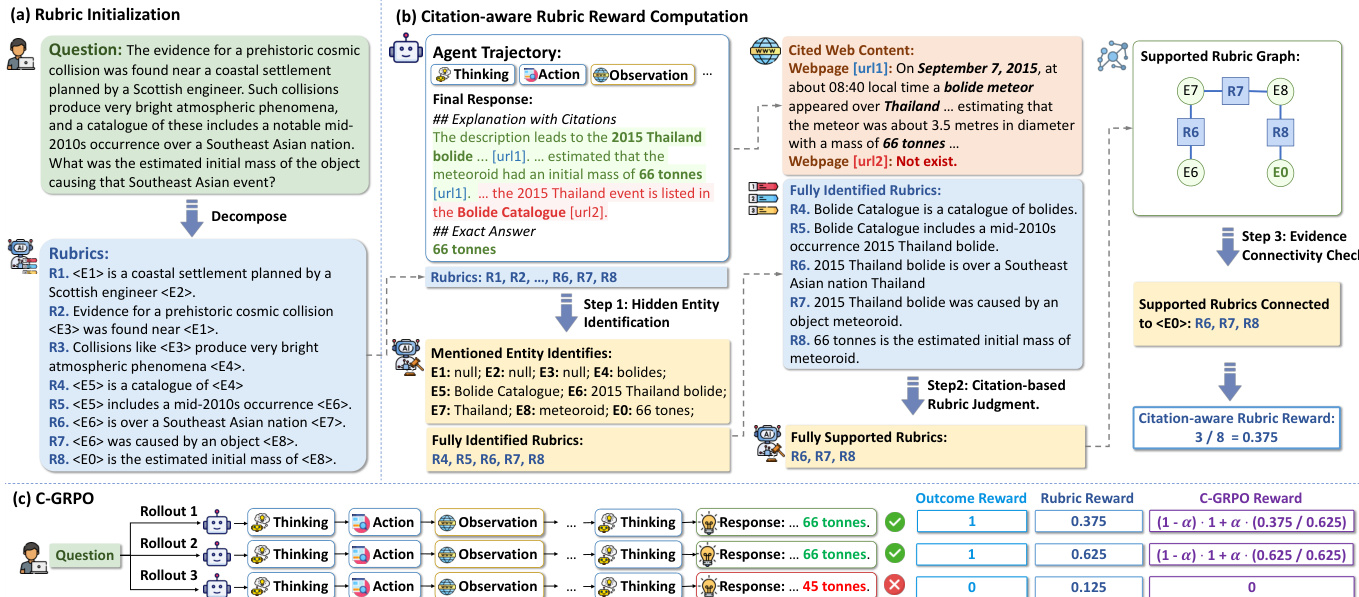
Second, the reward computation process evaluates an agent's trajectory against these pre-defined rubrics. This involves a three-step procedure using a judge LLM. Step 1, hidden entity identification, checks if the agent's final response explicitly identifies the name of each hidden entity. Step 2, citation-based rubric judgment, verifies that each identified rubric is supported by cited web content extracted from the trajectory. Step 3, evidence connectivity check, ensures that the supported rubrics form a connected evidence chain that logically links to the predicted answer entity. This is achieved by constructing a bipartite graph of identified entities and supported rubrics and performing a breadth-first search from the answer entity to determine which rubrics are reachable. The final rubric reward is the proportion of rubrics that are fully identified, supported, and connected.

Finally, the authors introduce the Citation-aware Group Relative Policy Optimization (C-GRPO) algorithm, which combines the CaRR framework with outcome rewards. C-GRPO uses a mixed reward for each trajectory, which is a weighted sum of the outcome reward (1 if the answer is correct, 0 otherwise) and the normalized rubric reward. This approach preserves the primary objective of finding the correct answer while encouraging the agent to produce more comprehensive and evidence-grounded reasoning. The agent policy is optimized by maximizing a multi-turn GRPO objective that incorporates token-level loss, importance sampling ratios, and advantages calculated from the mixed rewards.
Experiment
- C-GRPO with context-aware rubric rewards significantly outperforms GRPO and E-GRPO baselines on all benchmarks, achieving average improvements of 5.1/8.0 (4B) and 2.6/6.0 (30B) under 64k/128k context budgets.
- On BrowseComp, C-GRPO increases cited webpages and rubric satisfaction compared to SFT and GRPO, demonstrating enhanced comprehensiveness and factuality.
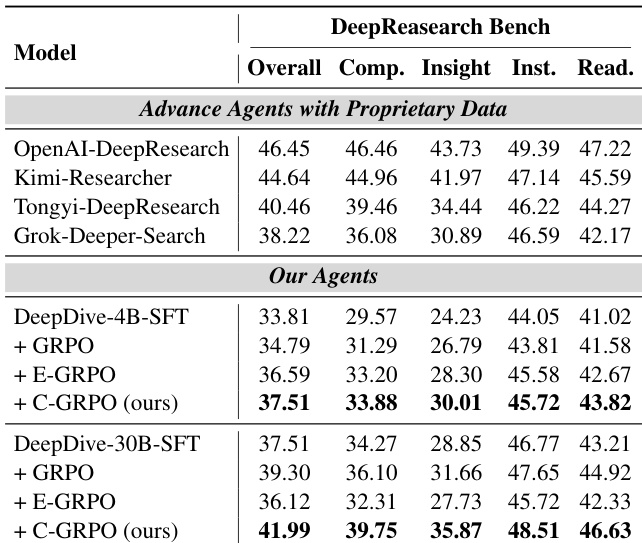
- C-GRPO achieves state-of-the-art performance among open-source agents on DeepResearch Bench, outperforming SFT models and surpassing several proprietary-data agents across comprehensiveness, insight, instruction following, and readability.
- Training dynamics show GRPO declines in tool call steps, indicating shortcut exploitation, while C-GRPO maintains increasing tool calls, reflecting more thorough evidence gathering.
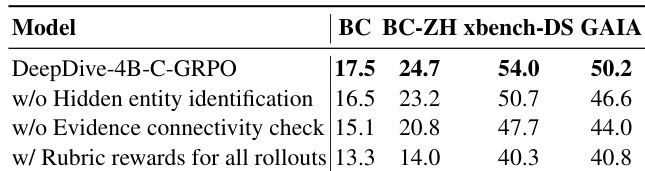
- Ablation studies confirm that hidden entity identification, evidence connectivity check, and selective rubric rewards for correct rollouts are critical for optimal performance.
- The judge LLM in CaRR shows high reliability with 97.7% accuracy in hidden entity identification and 95.1% in rubric evaluation, validated by human verification.
The authors use ablation studies to evaluate the impact of key components in the C-GRPO framework. Results show that removing hidden entity identification or evidence connectivity check significantly reduces performance across all benchmarks, indicating their importance in ensuring robust and accurate reasoning. Additionally, applying rubric rewards to all rollouts instead of only correct ones leads to a notable drop in performance, suggesting that such a change introduces misleading signals during training.
The authors use C-GRPO to train deep search agents and show that it significantly outperforms GRPO and E-GRPO baselines across all benchmarks. Results show that C-GRPO achieves the highest scores in all evaluation dimensions, with the 30B model surpassing several advanced agents that use proprietary data.
The authors use the table to compare the performance of different models on rubric satisfaction metrics, showing that C-GRPO improves upon the SFT baseline in identifying and supporting rubrics. Results show that C-GRPO achieves higher scores in rubric identification and support while maintaining performance in connectivity, indicating more thorough evidence gathering and verification.

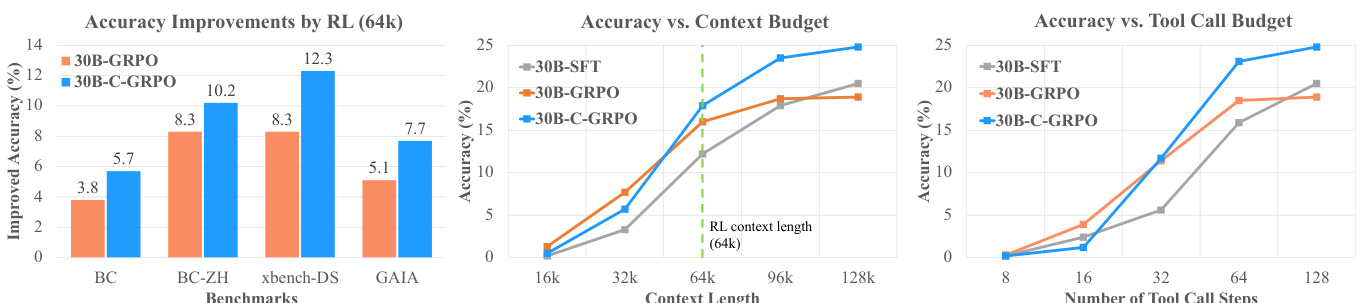
The authors use C-GRPO, a reward mechanism incorporating context-aware rubric rewards, to train deep search agents and show that it significantly outperforms GRPO and E-GRPO baselines across all benchmarks. Results show that C-GRPO achieves higher accuracy than GRPO at both 64k and 128k context lengths, with consistent improvements in accuracy as the context and tool call budgets increase, indicating better scalability and robustness.
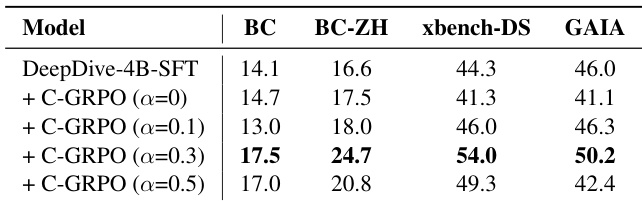
The authors use C-GRPO with varying rubric reward weights to train a 4B model, showing that performance improves as the weight increases from 0 to 0.3, peaking at 0.3, but declines at 0.5, indicating that a moderate balance between outcome and rubric rewards is optimal. Results show that C-GRPO with α=0.3 achieves the best performance across all benchmarks, outperforming both the SFT baseline and other C-GRPO variants.