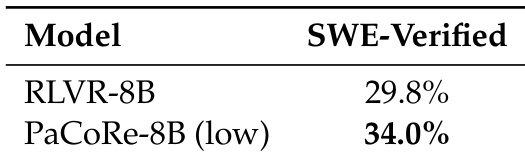Command Palette
Search for a command to run...
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Abstract
We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
One-sentence Summary
The authors from StepFun, Tsinghua University, and Peking University propose PaCoRe, a parallel coordinated reasoning framework that enables massive test-time compute scaling via message-passing across multiple rounds of parallel reasoning trajectories, outperforming GPT-5 on HMMT 2025 (94.5% vs. 93.2%) by effectively synthesizing multi-million-token reasoning within fixed context limits, with open-sourced model and data to advance scalable reasoning systems.
Key Contributions
- PaCoRe introduces a novel framework that decouples test-time compute (TTC) scaling from fixed context window limitations by enabling massive parallel reasoning trajectories coordinated through iterative message passing, allowing effective TTC to scale to multi-million tokens within standard context bounds.
- The method relies on large-scale, outcome-based reinforcement learning to train models in Reasoning Synthesis—critically enabling them to reconcile conflicting insights across parallel branches, overcoming the "Reasoning Solipsism" problem that plagues naive aggregation approaches.
- On the HMMT 2025 mathematics benchmark, PaCoRe-8B achieves 94.5% accuracy, surpassing GPT-5’s 93.3% by leveraging up to two million effective tokens of TTC, with full resources including model checkpoints, training data, and inference code open-sourced for community use.
Introduction
The authors address the challenge of scaling test-time compute (TTC) in large language models for long-horizon reasoning tasks, where traditional sequential reasoning is constrained by fixed context windows. Prior approaches either saturate context limits through deep chains of thought or rely on task-specific coordination mechanisms that lack generalization. To overcome these limitations, the authors introduce PaCoRe, a framework that decouples reasoning volume from context capacity by enabling parallel, coordinated reasoning across multiple trajectories. In each round, parallel reasoning paths generate intermediate solutions, which are compressed into compact messages and synthesized within the model’s context to guide the next iteration. This iterative process allows effective TTC to scale into the millions of tokens while operating within standard context limits. A key innovation is the use of large-scale, outcome-based reinforcement learning to train the model in Reasoning Synthesis—critically, the ability to reconcile conflicting evidence across parallel branches rather than defaulting to naive aggregation. The approach demonstrates state-of-the-art performance on math benchmarks, outperforming even proprietary models like GPT-5, and is accompanied by open-sourced models, data, and code to advance community research.
Dataset

- The dataset combines math problems from open-source repositories and historical math competitions, including AIME, HMMT, SMT, CMIMC, BRUMO, BMT, CHMMC, DMM, MNYMO, PUMAC, and Math Prize for Girls, sourced from their official archives.
- Open-source math datasets are drawn from references [40, 10, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50], while competition problems are collected from official online archives [51–61].
- AIME 2024/2025, HMMT Feb 2025, BRUMO 2025, SMT 2025, CMIMC 2025, and HMMT Nov 2025 are excluded from training to avoid overlap with the MathArena benchmark [62].
- 13,000 synthetic large-integer arithmetic problems are generated using hand-written templates, with integers A and B sampled uniformly between 10¹¹ and 10¹³, and operations including addition, subtraction, multiplication, or modular exponentiation modulo a fixed large prime.
- Each synthetic problem is designed to have a single, unambiguous integer answer, computed exactly and used as the ground-truth label.
- Data quality control involves multiple stages: deterministic rule-based filtering removes problems with images, external links, multi-part questions, or open-ended prompts; in-house experts annotate 100 samples to identify common issues like incorrect solutions or ambiguous wording.
- A fine-tuned LLM-based judge (gpt-oss-120b) is used in a 4-pass unanimity scheme to classify QA pairs as valid or invalid, with the prompt iteratively refined until F1 score saturates, ensuring only well-posed, verifiable problems are retained.
- The filtered open-source and competition problems are merged with the synthetic arithmetic set, and an additional accuracy-based filter is applied using a strong proposer model to select non-trivial, non-degenerate problems as part of curriculum design.
- For competitive coding data, approximately 29,000 problems are collected from sources like TACO [63], USACO, and recent open-source datasets such as am-thinking-v1 [64] and deepcoder [65].
- Each problem undergoes format validation, test case verification, and full judging using the testlib library, with modifications to support 64-bit integer comparisons and custom checkers generated via LLMs when needed.
- A generator-validation pipeline inspired by CodeContests+ [66] produces new test cases using LLMs, which are validated against ground-truth and incorrect submissions to ensure correctness.
- The final code dataset includes about 5,000 curated problems from CodeForces [64], selected based on test case quality and performance in RL experiments, where fine-grained test case pass rate rewards outperform binary rewards.
Method
The authors introduce Parallel Coordinated Reasoning (PaCoRe), a framework designed to scale test-time compute (TTC) beyond the constraints of fixed context windows by leveraging parallel exploration and coordinated message passing across multiple rounds. The core of the framework lies in its iterative inference pipeline, which operates through a sequence of coordinated reasoning rounds. At each round r, the system receives a set of compact messages Mr−1 from the prior round, which serve as a synthesized summary of previous reasoning efforts. These messages, combined with the original problem instance x, form the input context for the current round. The model then generates Kr independent reasoning trajectories in parallel, each representing a full chain of reasoning culminating in a final conclusion. This parallel generation constitutes the primary mechanism for scaling effective TTC, as the aggregate token count across all trajectories grows significantly while the input context per round remains bounded by the fixed context window.
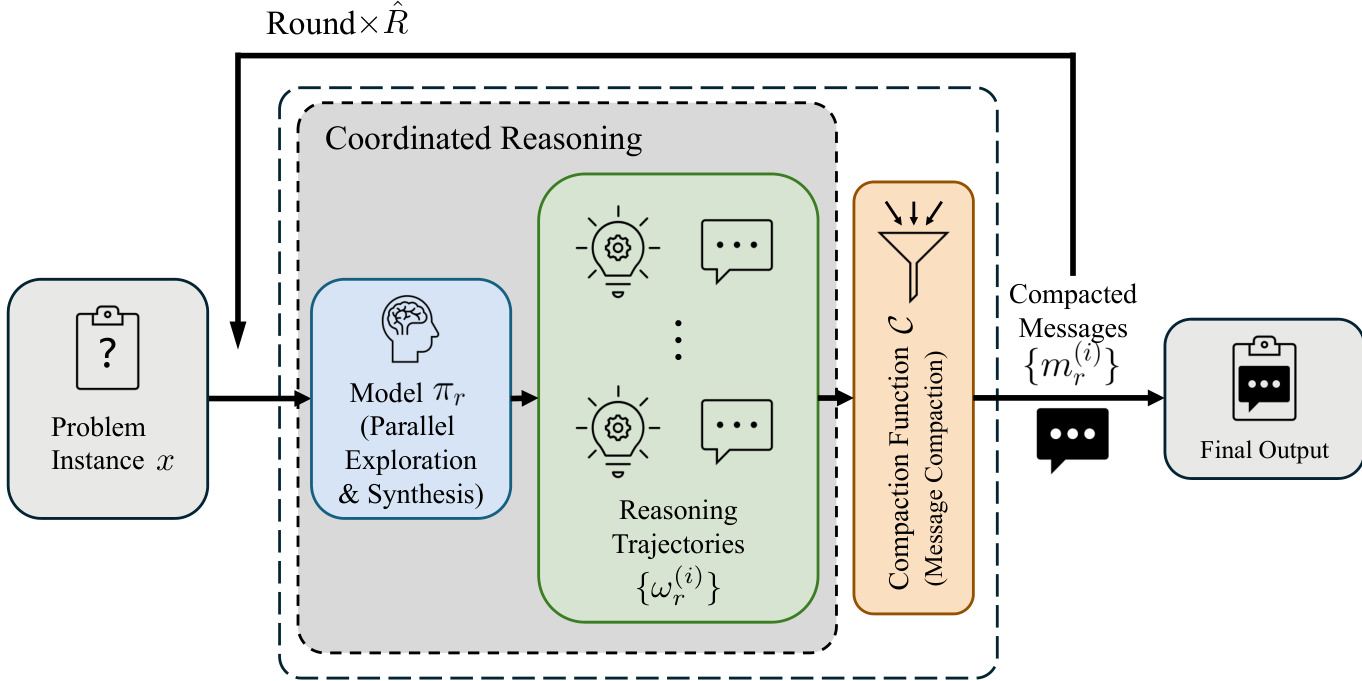
As shown in the figure below, the process is structured into two main stages per round: Synthesis and Parallel Exploration, followed by Message Compaction. In the first stage, the model πr, which uses the same weights across all rounds for operational simplicity, is invoked to generate the set of trajectories Ωr={ωr(i)} from the input P(x,Mr−1). The prompting function P serializes the problem and messages into a structured natural language input, as detailed in Table 6, which frames the messages as "Reference Responses" to encourage critical evaluation and synthesis. The second stage involves compressing the full trajectories Ωr into a new set of compact messages Mr via a compaction function C. In the implementation, this function extracts only the final conclusion from each trajectory, discarding intermediate reasoning steps, thereby ensuring that the input length for the next round remains within the context window. This iterative process repeats for R rounds, with the final round using a single trajectory (KR=1) to produce the final output y=mR(1), which is the model's answer.
The training of the PaCoRe model is conducted using large-scale, outcome-based reinforcement learning to instill the necessary synthesis capabilities. The training procedure treats a single round of the PaCoRe inference as an episodic reinforcement learning environment, where the policy πθ is optimized to generate high-quality reasoning trajectories from a given problem and message set. The policy receives a sparse terminal reward based on the correctness of the extracted message from the generated trajectory. To ensure that the model develops genuine synthesis rather than relying on simple heuristics, training instances where the average accuracy of the input message set exceeds a threshold are discarded. This approach compels the model to reconcile conflicting information and generate novel strategies that surpass the quality of any individual input, effectively training it to function within an implicitly multi-agent environment.
Experiment
- PaCoRe-8B is trained via large-scale reinforcement learning on competition-level math and coding tasks, using a two-stage data filtering process to promote synthesis over naive aggregation. Training evolves cross-checking behaviors and emergent correctness, enabling the model to generate correct solutions even from entirely incorrect input messages.
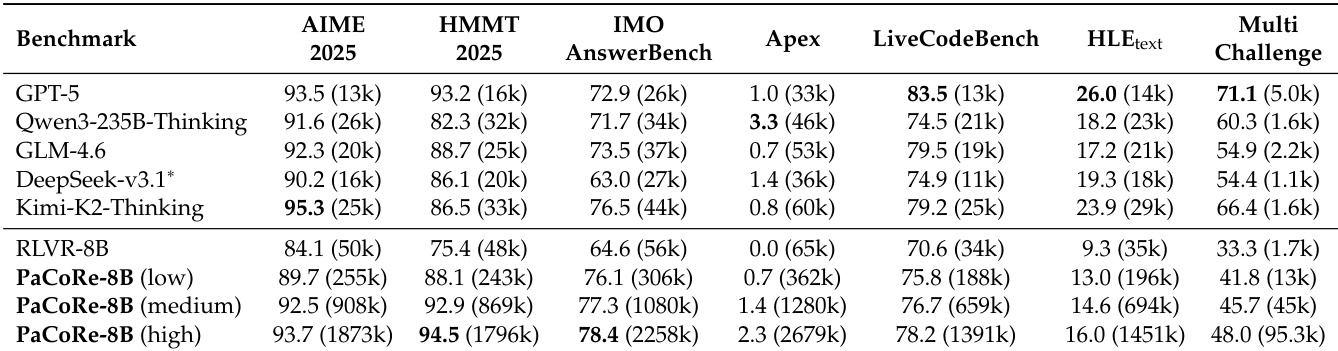
- On HMMT 2025, PaCoRe-8B achieves 94.5% pass@1 in the High inference setting (K = [32, 4]), surpassing GPT-5 and significantly outperforming larger models like Qwen3-235B-A22B-Thinking-2507 and DeepSeek-V3.1-Terminus.
- On LiveCodeBench, PaCoRe-8B reaches 78.2% pass@1, outperforming RLVR-8B and remaining competitive with frontier models such as GLM-4.6 and Kimi-K2-Thinking.
- On the challenging Apex benchmark, PaCoRe-8B achieves 2.3% pass@1 in the High setting, while RLVR-8B scores 0.0%, demonstrating its ability to solve problems where baseline models fail.
- Ablation studies confirm that parallel coordinated reasoning with message passing is essential: it enables robust scaling with test-time compute (TTC), while sequential or uncompactified approaches saturate or degrade under high TTC.
- PaCoRe generalizes effectively to new domains: on SWE-Verified, PaCoRe-8B (low) achieves 34.0% resolve rate, outperforming RLVR-8B (29.8%); on MultiChallenge, it improves from 33.3% to 48.0% under higher TTC.
- The PaCoRe training dataset alone, when used for standard RLVR training, yields significant performance gains on AIME 2025 and LiveCodeBench with minimal compute, indicating its high density and general applicability as a reasoning training substrate.
Results show that PaCoRe-8B consistently outperforms the RLVR-8B baseline and several larger models across all benchmarks, with the highest performance achieved in the high test-time scaling setting. The model reaches 94.5% on HMMT 2025 and 78.4% on IMOAnswerBench, surpassing GPT-5 and demonstrating strong generalization to challenging tasks like Apex and software engineering scenarios.
The authors use the PaCoRe data to train an RLVR model, which achieves a significant improvement over the SFT baseline on both AIME 2025 and LiveCodeBench. Results show that the RLVR model trained with PaCoRe data reaches 83.2% on AIME 2025 and 74.0% on LiveCodeBench, outperforming the SFT model by 1.8 and 8.0 percentage points respectively.

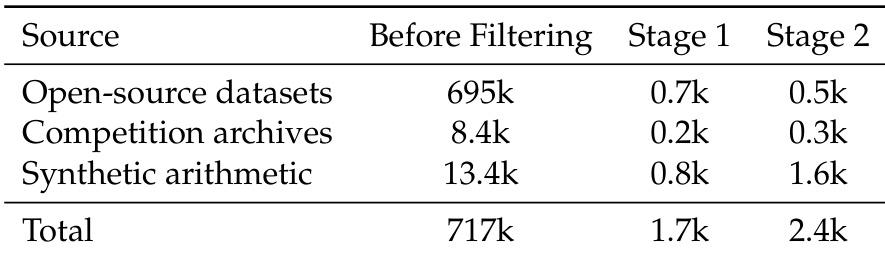
The authors use a two-stage filtering process to refine the training data distribution for PaCoRe-8B, reducing the total dataset size from 717k to 2.4k across three sources. Stage 1 filters for low message set accuracy and quality, while Stage 2 further refines the data by retaining only instances where synthesis accuracy is between 0 and 1, resulting in a more focused and effective training corpus.
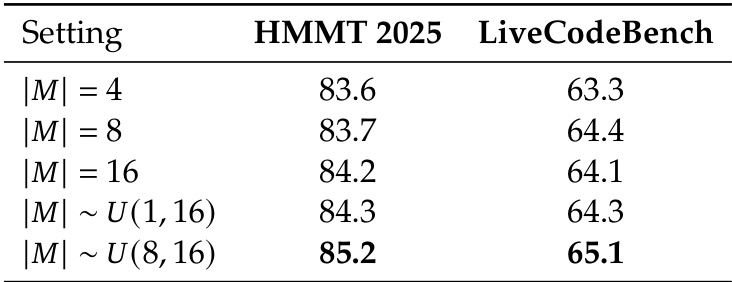
The authors use the table to analyze the impact of message set size on model performance, showing that varying the size of the message set during inference improves results. Results show that using a uniformly sampled message set size between 8 and 16 achieves the highest accuracy on both HMMT 2025 and LiveCodeBench, outperforming fixed-size settings.
The authors compare the performance of RLVR-8B and PaCoRe-8B (low) on the SWE-Verified benchmark, showing that PaCoRe-8B (low) achieves a resolve rate of 34.0%, which is a significant improvement over the RLVR-8B baseline of 29.8%. This result demonstrates that the PaCoRe framework enables strong generalization to software engineering tasks without task-specific tuning.