Command Palette
Search for a command to run...
RL-AWB: Deep Reinforcement Learning for Auto White Balance Correction in Low-Light Night-time Scenes
RL-AWB: Deep Reinforcement Learning for Auto White Balance Correction in Low-Light Night-time Scenes
Yuan-Kang Lee Kuan-Lin Chen Chia-Che Chang Yu-Lun Liu
Abstract
Nighttime color constancy remains a challenging problem in computational photography due to low-light noise and complex illumination conditions. We present RL-AWB, a novel framework combining statistical methods with deep reinforcement learning for nighttime white balance. Our method begins with a statistical algorithm tailored for nighttime scenes, integrating salient gray pixel detection with novel illumination estimation. Building on this foundation, we develop the first deep reinforcement learning approach for color constancy that leverages the statistical algorithm as its core, mimicking professional AWB tuning experts by dynamically optimizing parameters for each image. To facilitate cross-sensor evaluation, we introduce the first multi-sensor nighttime dataset. Experiment results demonstrate that our method achieves superior generalization capability across low-light and well-illuminated images. Project page: https://ntuneillee.github.io/research/rl-awb/
One-sentence Summary
The authors from MediaTek, National Taiwan University, and National Yang Ming Chiao Tung University propose RL-AWB, a novel framework that combines a nighttime-optimized statistical color constancy algorithm with deep reinforcement learning to dynamically tune white balance parameters without requiring ground-truth illumination, achieving superior cross-sensor generalization in low-light and complex lighting conditions.
Key Contributions
- We introduce SGP-LRD, a nighttime-specific statistical color constancy algorithm that enhances illumination estimation by combining salient gray pixel detection with local reflectance differences, achieving state-of-the-art performance on public nighttime benchmarks.
- We propose RL-AWB, the first deep reinforcement learning framework for automatic white balance that dynamically optimizes statistical algorithm parameters via Soft Actor-Critic with two-stage curriculum learning, enabling adaptive, data-efficient tuning without requiring ground-truth illumination labels.
- We release LEVI, the first multi-sensor nighttime dataset with 700 images from two camera sensors, enabling rigorous cross-sensor evaluation and demonstrating that RL-AWB achieves superior generalization with only 5 training images per dataset.
Introduction
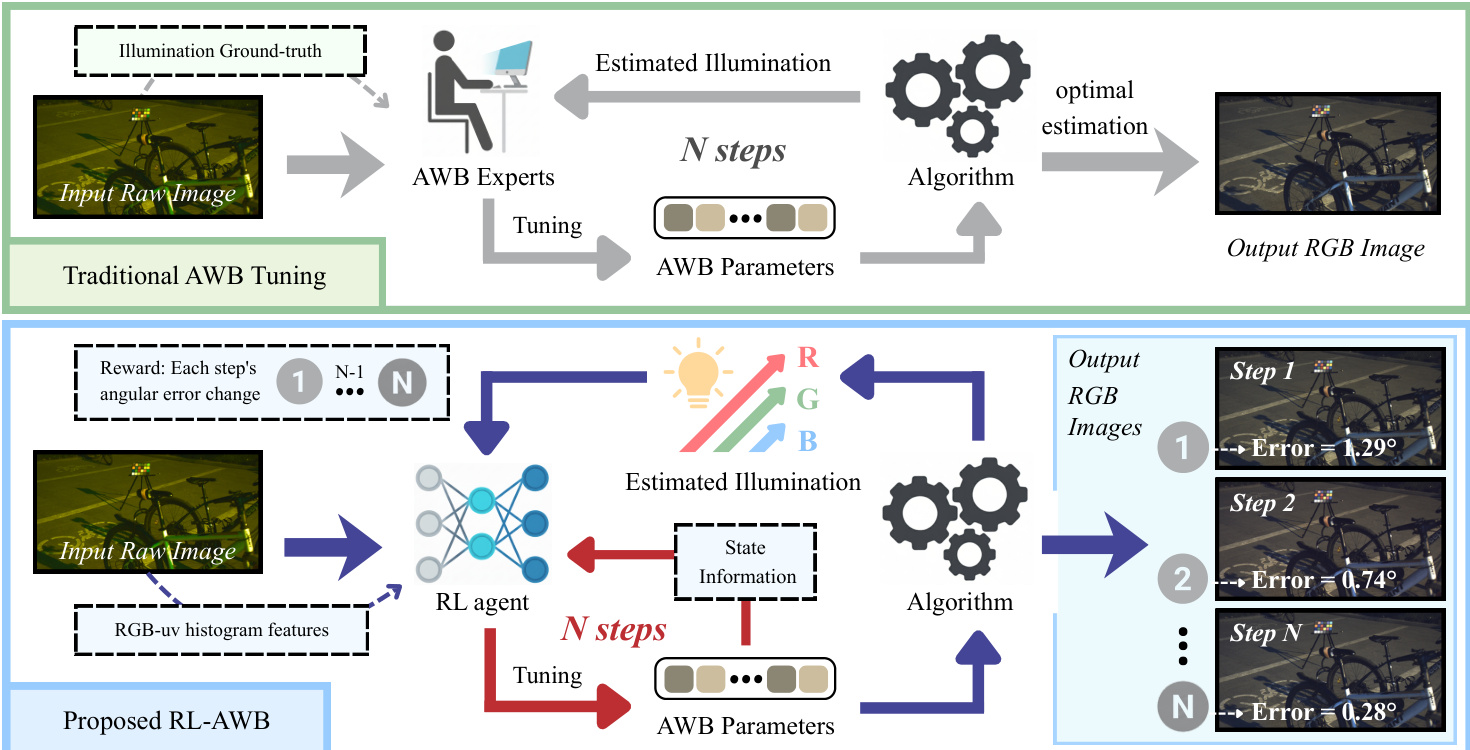
The authors address the challenge of automatic white balance (AWB) in low-light nighttime scenes, where traditional methods struggle due to high noise, mixed illumination, and unreliable color statistics. Prior statistical and deep learning approaches fail under these conditions—statistical methods rely on fixed parameters that break down in noise-heavy environments, while learning-based methods require large labeled datasets and suffer from poor cross-sensor generalization. To overcome these limitations, the authors introduce RL-AWB, a hybrid framework that combines a novel nighttime-specific statistical algorithm, SGP-LRD, with deep reinforcement learning. The RL agent learns to dynamically optimize key hyperparameters of SGP-LRD—gray-pixel sampling percentage and Minkowski order—through a Soft Actor-Critic policy trained with a two-stage curriculum, enabling fast, adaptive, and interpretable parameter tuning. This approach achieves state-of-the-art performance with minimal training data (only 5 images per dataset) and strong cross-sensor generalization, validated on the newly introduced LEVI dataset, which supports multi-sensor evaluation.
Dataset

- The LEVI dataset is a new multi-camera nighttime color constancy benchmark introduced to address the limitations of the prior NCC dataset, which contained only 513 images from a single camera.
- LEVI comprises 700 linear RAW images captured across two camera systems: 370 images from an iPhone 16 Pro (4320×2160, 12-bit) and 330 images from a Sony ILCE-6400 (6000×4000, 14-bit), with ISO values ranging from 500 to 16,000 to cover diverse low-light conditions.
- Each scene includes a Macbeth Color Checker, with manually annotated masks, enabling precise ground-truth illuminant estimation. The ground-truth illuminant is computed as the median RGB value of non-saturated achromatic patches on the checker.
- All images undergo black-level correction and are converted to linear RGB space to ensure consistency and compatibility with algorithmic processing.
- The dataset includes detailed metadata per image, such as focal length (mm), F-number, exposure time (s), and ISO, supporting analysis of how camera settings influence illuminant estimation.
- For model training and evaluation, images from all datasets—including LEVI and NCC—are normalized to a common resolution: iPhone 16 Pro images in LEVI are downsampled by 0.25×, while Sony ILCE-6400 images and all NCC images are downsampled by 0.125×.
- The RL-AWB (SAC) model is trained using a batch size of 256, a learning rate of 3×10⁻⁴, γ=0.99, τ=0.005, over 150,000 timesteps with 16 parallel environments, starting updates after 100 initial steps.
- Performance is evaluated using the standard angular error metric in degrees, with the dataset enabling cross-sensor generalization evaluation and improved assessment of low-light color constancy under varied imaging conditions.
Method
The proposed framework integrates a data-driven reinforcement learning (RL) approach with a robust nighttime color constancy algorithm, SGP-LRD, to achieve adaptive white balance tuning. The overall architecture is designed to learn optimal parameter configurations for the SGP-LRD algorithm based on scene characteristics, enabling automated and efficient illumination estimation. The system operates in two primary modes: a traditional, expert-driven tuning process and a proposed RL-AWB framework that learns to adapt parameters autonomously.
The core of the method is the SGP-LRD algorithm, which estimates the scene illumination by identifying and leveraging salient gray pixels. The process begins with gray pixel detection, where pixels are ranked based on their grayness, measured as the angular error between their local contrast vector and the gray direction. This initial set is refined through a two-layer filtering process to mitigate noise and chromatic outliers. The first stage, local variance filtering, removes pixels with low intra-pixel variance in the logarithmic RGB space, which are indicative of sensor noise. The second stage, color deviation filtering, eliminates pixels that are too distant from the dominant color cast of the scene, defined by the mean logarithmic intensity of the image. This refinement yields the Salient Gray Pixels (SGPs). To account for varying signal quality across the image, a gray-pixel confidence weighting scheme is applied. This weighting is adaptive, using the skewness of the luminance distribution to select an exponent parameter E, which modulates the confidence weight based on local brightness. The final illuminant estimate is computed using a Minkowski norm-based aggregation, where the weighted contributions of SGPs and their local reflectance differences are combined. The algorithm's design principles—reliability amplification, implicit noise filtering, and spatial prior exploitation—are inherently encoded in its structure, particularly through the use of overlapping local windows for reflectance difference computation.
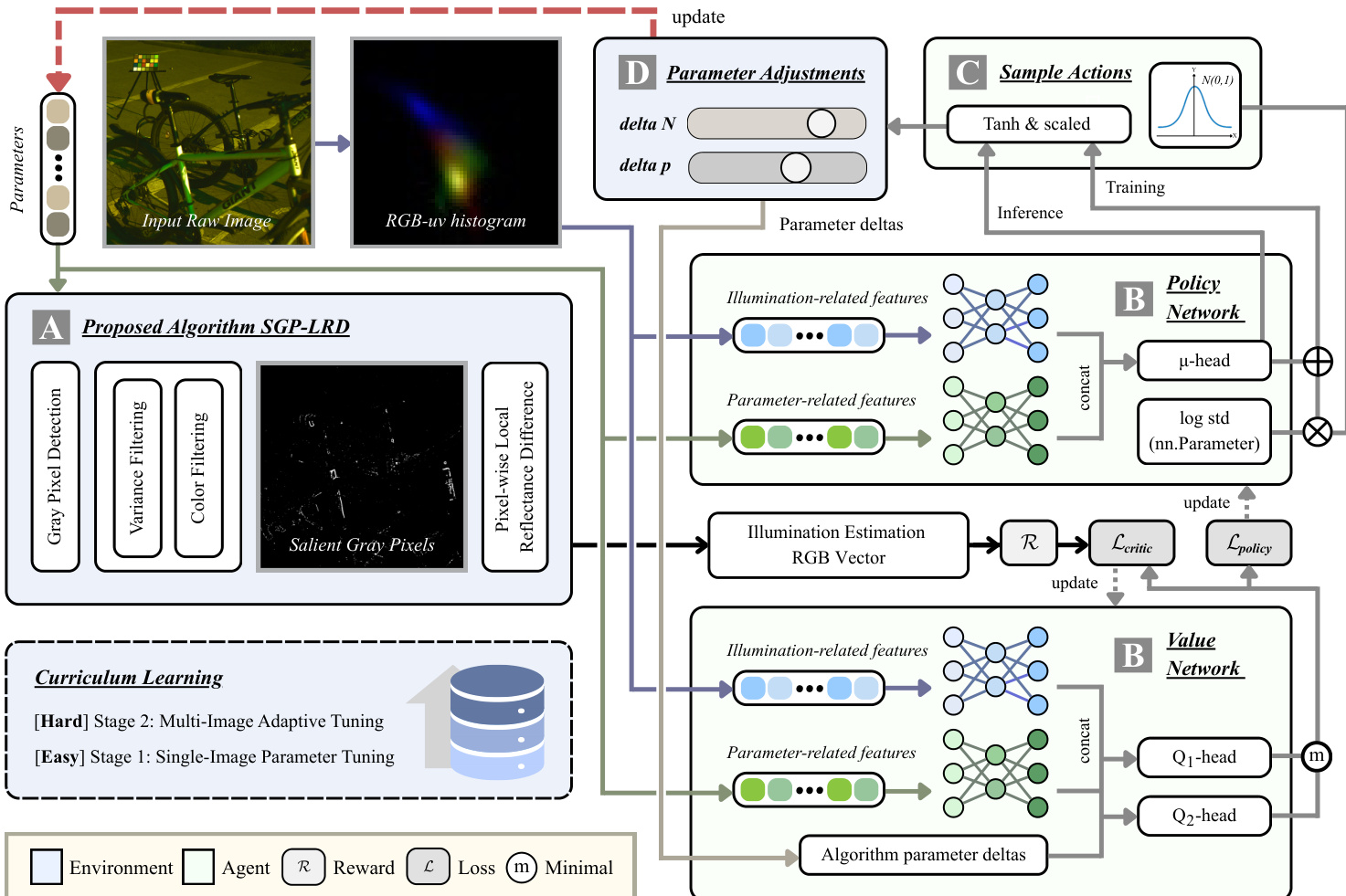
The RL-AWB framework, as illustrated in the figure, uses the SGP-LRD algorithm as its environment. The agent learns to tune two key parameters: the gray pixel candidate selection threshold N% and the Minkowski norm exponent p. The state representation is designed to be rich and scene-aware, combining illumination-related features derived from a log-chrominance (RGB-uv) histogram with a history of recent parameter adjustments. This state is processed by a two-branch MLP encoder, which fuses the features into a single embedding. The actor network, which outputs the policy, generates continuous actions for the parameter adjustments, which are then rescaled to valid ranges. The critic networks, implemented with twin Q-value heads, evaluate the quality of these actions. The training process is based on the Soft Actor-Critic (SAC) algorithm, which optimizes a policy that maximizes both the expected return and the policy entropy, promoting exploration and stability. The reward function is carefully designed to measure the relative improvement in angular error, with additional penalties for large action steps and bonuses for significant convergence, ensuring the agent learns to make effective and stable adjustments.
Experiment
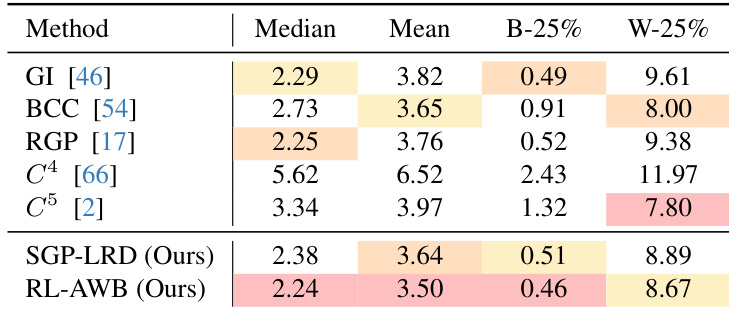
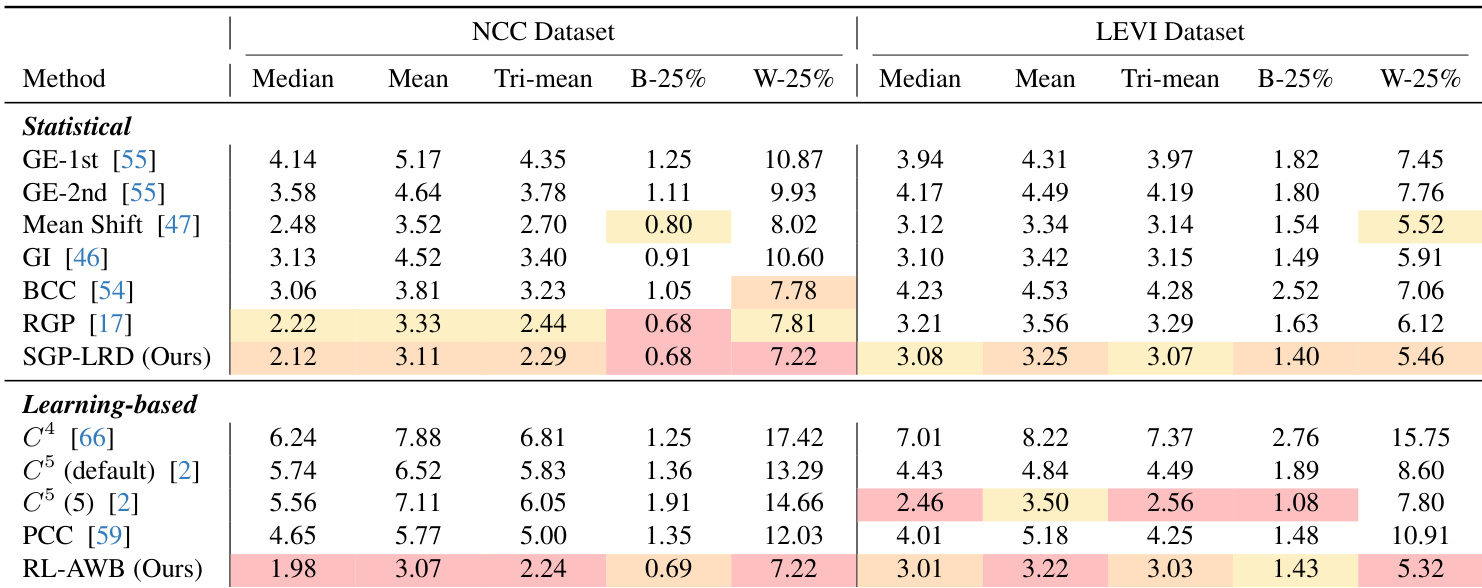
- In-domain evaluation on NCC and LEVI datasets: RL-AWB achieves the best median and mean angular errors under the 5-shot setting, outperforming statistical methods like SGP-LRD and deep learning baselines (C⁴, C⁵, PCC), with SGP-LRD enhanced by RL tuning showing superior instance-level adaptation.
- Cross-dataset generalization: RL-AWB significantly reduces performance degradation when transferring between NCC and LEVI datasets, consistently outperforming learning-based methods in both recovery and reproduction angular error, demonstrating robustness to domain and sensor shifts.
- Daytime and indoor generalization: On the Gehler-Shi dataset, RL-AWB achieves state-of-the-art results despite being trained on low-light data, reducing median angular error by 5.9% and best-25% error by 9.8% compared to SGP-LRD, showing strong cross-scenario adaptability.
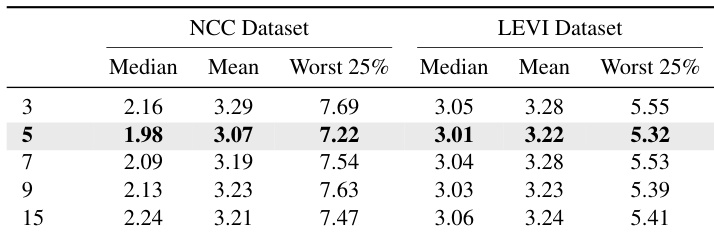
- Ablation studies confirm that M = 5 in the curriculum pool offers optimal trade-off, dual-branch architecture improves performance by better preserving adjustment history, and RL-based tuning consistently enhances SGP-LRD across settings.
- Reproduction angular error results validate that RL-AWB not only improves illuminant estimation accuracy but also enhances perceptual white balance quality, with consistent superiority in both in-dataset and cross-dataset evaluations.
Results show that RL-AWB achieves the lowest median and mean angular errors among all methods on the NCC dataset, outperforming both statistical and deep learning baselines. The authors use RL-AWB to adaptively tune SGP-LRD parameters, resulting in superior in-dataset performance and improved stability compared to fixed-parameter approaches.
The authors use a curriculum learning approach to evaluate the impact of training data size on RL-AWB performance, varying the pool size from 3 to 15 images. Results show that a pool size of 5 images achieves the best trade-off, with the lowest median and mean angular errors on both the NCC and LEVI datasets, indicating optimal performance under limited data.
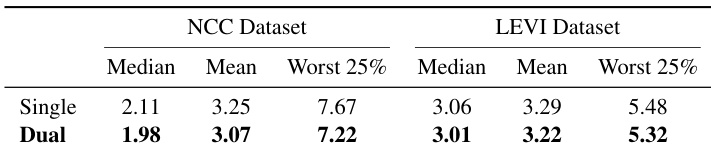
The authors use a dual-branch network architecture for RL-AWB, which processes high-dimensional WB-sRGB histograms and low-dimensional adjustment histories separately to preserve critical control information. Results show that the dual-branch design achieves lower median and worst-25% angular errors compared to the single-branch variant on both the NCC and LEVI datasets.
The authors use the NCC and LEVI datasets to evaluate illumination estimation performance using angular error, with lower values indicating better accuracy. Results show that RL-AWB achieves the lowest median and mean angular errors on both datasets, outperforming all statistical and learning-based baselines, particularly in the few-shot setting.
Results show that RL-AWB achieves the lowest median and worst-25% angular errors in cross-dataset evaluation, significantly outperforming all learning-based baselines on both NCC→LEVI and LEVI→NCC settings, demonstrating its superior generalization capability across different sensor and scene distributions.
