Command Palette
Search for a command to run...
RelayLLM: Efficient Reasoning via Collaborative Decoding
RelayLLM: Efficient Reasoning via Collaborative Decoding
Chengsong Huang Tong Zheng Langlin Huang Jinyuan Li Haolin Liu Jiaxin Huang
Abstract
Large Language Models (LLMs) for complex reasoning is often hindered by high computational costs and latency, while resource-efficient Small Language Models (SLMs) typically lack the necessary reasoning capacity. Existing collaborative approaches, such as cascading or routing, operate at a coarse granularity by offloading entire queries to LLMs, resulting in significant computational waste when the SLM is capable of handling the majority of reasoning steps. To address this, we propose RelayLLM, a novel framework for efficient reasoning via token-level collaborative decoding. Unlike routers, RelayLLM empowers the SLM to act as an active controller that dynamically invokes the LLM only for critical tokens via a special command, effectively "relaying" the generation process. We introduce a two-stage training framework, including warm-up and Group Relative Policy Optimization (GRPO) to teach the model to balance independence with strategic help-seeking. Empirical results across six benchmarks demonstrate that RelayLLM achieves an average accuracy of 49.52%, effectively bridging the performance gap between the two models. Notably, this is achieved by invoking the LLM for only 1.07% of the total generated tokens, offering a 98.2% cost reduction compared to performance-matched random routers.
One-sentence Summary
The authors from Washington University in St. Louis, University of Maryland, and University of Virginia propose RelayLLM, a token-level collaborative decoding framework that enables small language models to dynamically invoke large language models only for critical tokens via a special command, achieving 49.52% average accuracy across six benchmarks while reducing LLM usage to just 1.07% of tokens—offering 98.2% cost savings over random routers.
Key Contributions
- Existing collaborative methods between small and large language models suffer from inefficiency due to coarse-grained, all-or-nothing offloading, leading to high computational waste even when the small model can handle most reasoning steps.
- RelayLLM introduces token-level collaborative decoding where the small model acts as an active controller, dynamically invoking the large model only for critical tokens via a special command, enabling precise and efficient expert intervention.
- Evaluated on six benchmarks, RelayLLM boosts average accuracy from 42.5% to 49.52% while using the large model for just 1.07% of tokens—achieving a 98.2% cost reduction compared to performance-matched random routers.
Introduction
The authors address the challenge of deploying large language models (LLMs) for complex reasoning tasks, which are often limited by high computational costs, while small language models (SLMs) lack the reasoning capacity to handle such tasks effectively. Prior collaborative approaches rely on coarse-grained routing or cascading, where entire queries are offloaded to LLMs when deemed difficult—leading to significant computational waste, as SLMs can typically manage most reasoning steps independently. To overcome this, the authors propose RelayLLM, a token-level collaborative decoding framework where the SLM acts as an active controller, dynamically invoking the LLM only for critical tokens via a special command. This enables efficient, interleaved generation with minimal expert intervention. The method uses a two-stage training process—supervised warm-up for command syntax and Group Relative Policy Optimization (GRPO) for strategic help-seeking—balancing independence and assistance. Experiments show RelayLLM achieves 49.52% average accuracy across six benchmarks, a 7% improvement over baselines, while using the LLM for just 1.07% of tokens—reducing cost by 98.2% compared to a performance-matched random router. Notably, the SLM also improves on easier tasks without external help, indicating internalization of effective reasoning patterns.
Dataset

- The dataset is composed of queries drawn from a larger pool, with a focus on instances where large model intervention can be beneficial.
- Each query is evaluated by generating 10 responses using the large model, and only queries achieving a pass rate of at least 50% are retained.
- This filtering ensures the training data remains within the large model’s competence boundary, preventing the inclusion of overly difficult instances that would yield no improvement.
- The filtered subset forms the primary training data, used to train the model with a mixture of reasoning paths and feedback generated by the large model.
- No cropping or metadata construction is applied beyond the pass-rate-based filtering; the focus is on preserving high-quality, solvable instances for effective training.
Method
The RelayLLM framework employs a hybrid inference architecture that orchestrates collaboration between a resource-efficient Small Language Model (SLM) and a powerful Large Language Model (LLM) to achieve high-quality responses while minimizing computational cost. The SLM, denoted as MS, functions as the primary reasoning engine and central controller throughout the generation process. It operates autoregressively, generating tokens based on the current context. However, it is augmented with a specialized control mechanism that allows it to dynamically request assistance from the LLM, ML, when needed. This is achieved by generating a specific command pattern, Ccmd(n)=<call>⊕n⊕</call>, where n is the number of tokens the SLM anticipates requiring from the LLM. This command acts as a trigger for intervention.
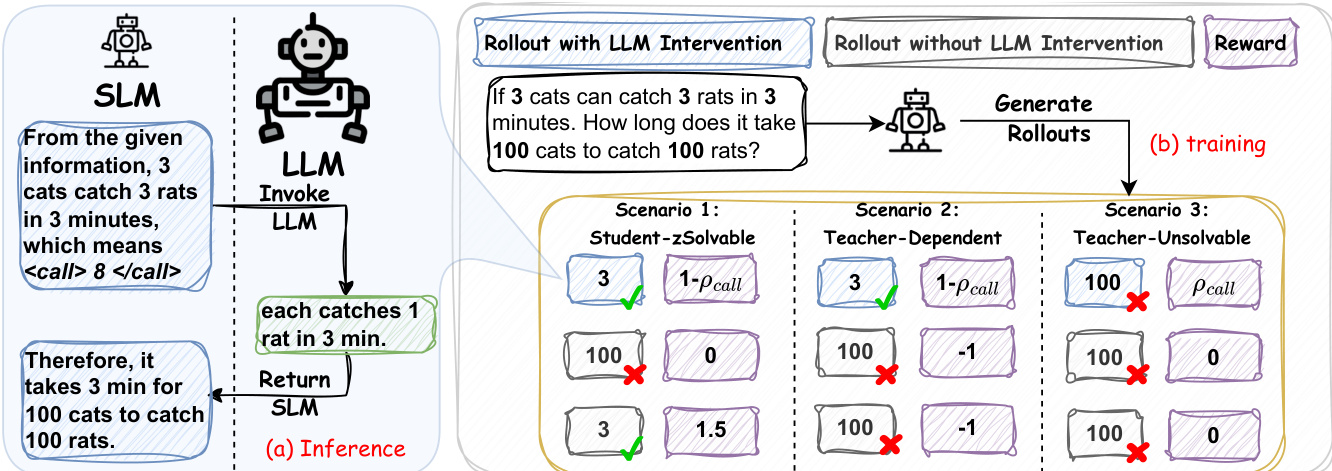
As shown in the figure below, the inference process is an interleaved generation cycle. When the SLM generates the command pattern, its generation pauses, and the current context—including the initial query and all tokens generated by the SLM up to that point—is forwarded to the LLM. To ensure compatibility with the LLM's standard input format, the special command tokens are stripped from the context before it is sent. The LLM then generates the next n tokens (or stops early if an end-of-sequence token is generated), providing a high-quality continuation or reasoning step. Control is then returned to the SLM, which resumes generation with the updated context, now including the tokens generated by the LLM. The SLM retains the full history, including its own command tokens, allowing it to maintain a trace of its delegation decisions and integrate the expert's guidance into its ongoing reasoning.

To enable the SLM to learn when and how long to invoke the LLM, a two-stage training framework is employed. The first stage is a supervised warm-up, which serves as a cold start to initialize the model with the necessary structural knowledge for generating the command pattern. A synthetic dataset, Dwarm, is constructed by sampling base sequences directly from a vanilla SLM to avoid distribution shifts. Command tokens are inserted at random positions within these sequences, simulating various calling scenarios. The model is fine-tuned on this dataset using standard cross-entropy loss, focusing on learning to output valid command patterns.
The second stage is policy refinement using reinforcement learning. The authors leverage Group Relative Policy Optimization (GRPO) within the Reinforcement Learning with Verifiable Reward (RLVR) paradigm. This framework samples a group of outputs for each query from the current policy and evaluates them relative to the group average. The training objective is formulated to maximize the performance of the generated responses while minimizing the cost of collaboration. A key component of this framework is the difficulty-aware reward design, which categorizes each query into one of three scenarios based on the collective performance of the sampled group: Student-Solvable, Teacher-Dependent, and Teacher-Unsolvable. This allows for a nuanced reward signal that encourages the SLM to solve problems independently when possible, seek help when necessary, and avoid costly errors.
Experiment
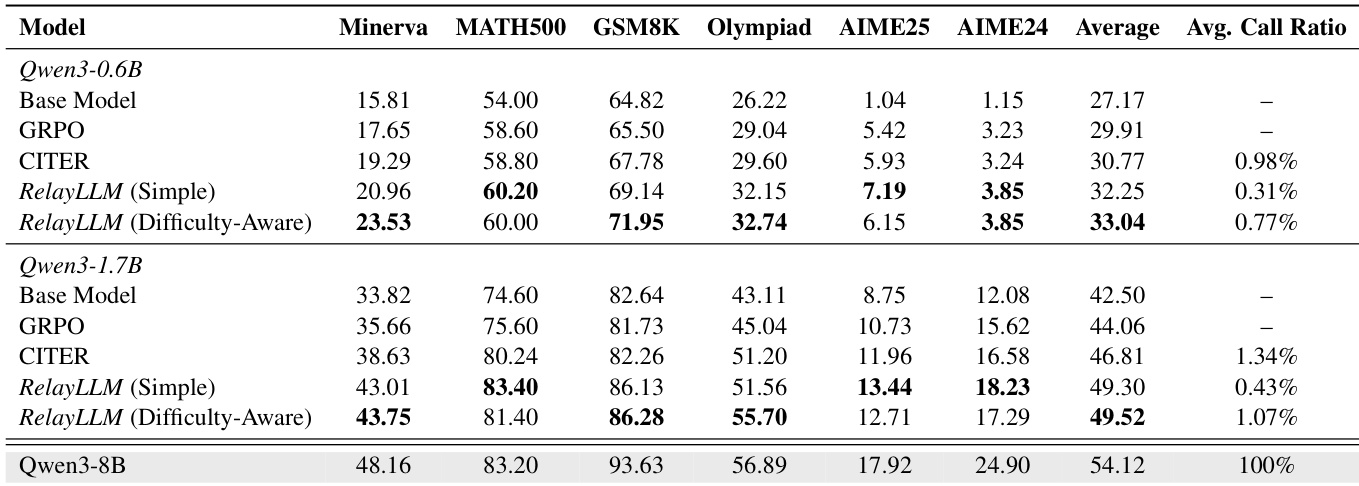
- Evaluated RelayLLM using Qwen3-0.6B and Qwen3-1.7B as student models with Qwen3-8B as the teacher, demonstrating superior performance across six reasoning benchmarks while maintaining under 1% token overhead.
- On Minerva, Qwen3-0.6B achieved 23.53% accuracy (up from 15.81%), a 48.8% relative improvement, with only 0.77% token usage for teacher calls, outperforming CITER despite CITER’s higher computational cost.
- Difficulty-Aware-Reward improved Qwen3-1.7B accuracy to 49.52% (vs. 49.30% for Simple-Reward), with a slight increase in call ratio (1.07% vs. 0.43%), showing better help-seeking in complex scenarios.
- RelayLLM enabled Qwen3-1.7B to recover ~60% of the performance gap between the base SLM (42.50%) and the expert model (54.12%), proving sparse, strategic intervention is highly effective.
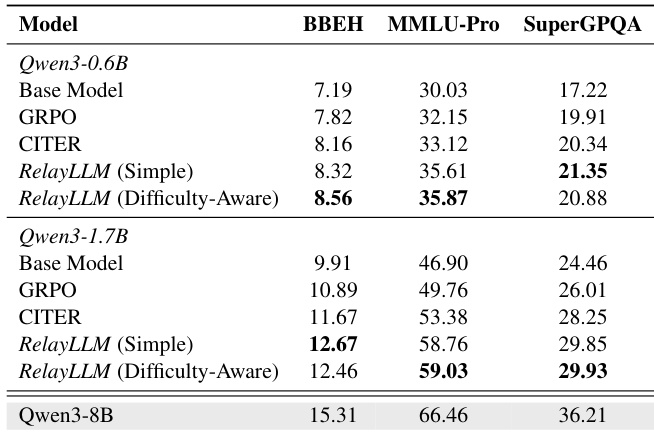
- Generalization to unseen domains: RelayLLM outperformed baselines on MMLU-Pro (59.03% vs. 49.76% GRPO), Big-Bench Hard, and SuperGPQA, indicating robust help-seeking behavior.
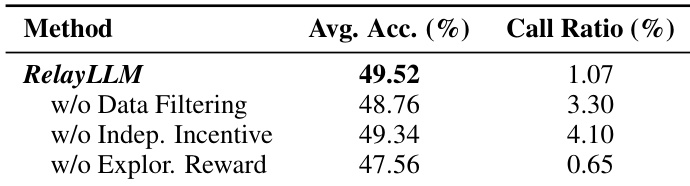
- Ablation studies confirmed that data filtering reduced call ratio by 3× and improved accuracy, independence incentives prevented over-reliance (call ratio dropped from 4.10% to 1.07%), and exploration reward was critical for accuracy (47.56% without it).
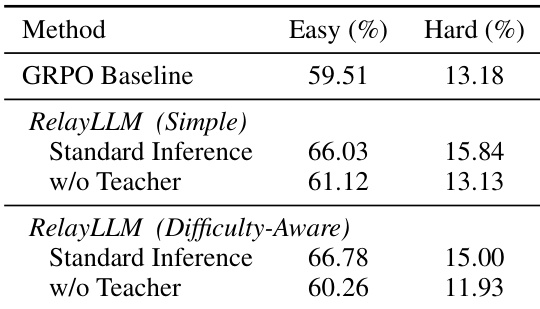
- Teacher-free evaluation showed RelayLLM retained strong intrinsic reasoning (61.12% on easy tasks), but performance dropped on hard tasks (e.g., 15.00% → 11.93%), confirming dependency on expert help for complex problems.
- Dynamic length prediction outperformed fixed-length strategies: RelayLLM matched Fixed-100 accuracy (81.40% on MATH500) with 1.07% call ratio vs. 2.87%, and surpassed Fixed-20 on Minerva (43.75% vs. 39.71%) with lower cost.
- Cross-LLM evaluation revealed that matching the training teacher (Qwen3-8B) maximized performance, but even weaker teachers (0.6B/1.7B) outperformed no-teacher baseline, indicating adaptation to external assistance.
- RelayLLM achieved comparable accuracy to larger models with negligible computational cost, demonstrating efficient, on-demand offloading and effective learning of help-seeking behavior.
The authors use Qwen3-0.6B and Qwen3-1.7B as student models to evaluate RelayLLM, comparing it against GRPO and CITER baselines across six reasoning benchmarks. Results show that RelayLLM achieves significant performance improvements over the base models and outperforms CITER, with the Difficulty-Aware-Reward variant achieving the highest accuracy while maintaining a low average call ratio of under 1%.
The authors use a teacher-free evaluation to assess the intrinsic reasoning capability of RelayLLM, showing that the student model retains improved reasoning skills even without access to the teacher. Results indicate that RelayLLM (Simple-Reward) achieves higher accuracy on easy datasets compared to the GRPO baseline, suggesting effective knowledge transfer, while performance drops on hard datasets, indicating continued dependence on the teacher for complex tasks.
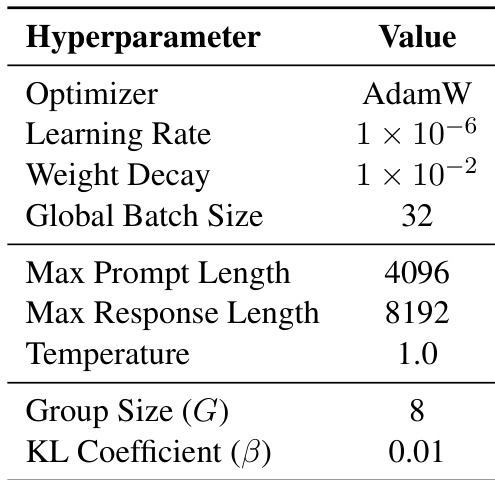
The authors use the GRPO algorithm for post-training, employing AdamW as the optimizer with a learning rate of 1×10−6 and a weight decay of 1×10−2. The model is trained with a global batch size of 32, a group size of 8, and a KL coefficient of 0.01 to ensure stability, while using a temperature of 1.0 during sampling.
The authors use an ablation study to evaluate the impact of key components in RelayLLM, showing that removing data filtering reduces accuracy while increasing the call ratio, indicating its importance in avoiding wasteful interactions. Removing the independence incentive leads to a higher call ratio, demonstrating that encouraging self-reliance improves efficiency. Eliminating the exploration reward significantly decreases accuracy, highlighting its role in prompting help-seeking during uncertain situations.
The authors use Qwen3-0.6B and Qwen3-1.7B as student models to evaluate RelayLLM against baselines on reasoning benchmarks, with Qwen3-8B as the teacher model. Results show that RelayLLM (Difficulty-Aware) achieves the highest accuracy on MMLU-Pro and SuperGPQA for both student models, outperforming all baselines while maintaining a low call ratio, demonstrating its effectiveness in generalizing to unseen domains.