Command Palette
Search for a command to run...
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Abstract
We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
One-sentence Summary
The authors from Shanghai Artificial Intelligence Laboratory and community contributors introduce SciEvalKit, a unified, open-source benchmarking toolkit for evaluating AI models in scientific intelligence across six domains, featuring expert-curated, real-world tasks and a flexible pipeline for reproducible, scalable assessment of capabilities like multimodal reasoning, symbolic reasoning, and hypothesis generation—enabling standardized evaluation of next-generation scientific foundation models.
Key Contributions
-
SciEvalKit addresses the lack of comprehensive evaluation for scientific intelligence in AI models by introducing a unified benchmarking framework that systematically assesses seven core competencies—ranging from scientific knowledge understanding and symbolic reasoning to multimodal perception and hypothesis generation—reflecting the full spectrum of real-world scientific reasoning.
-
The toolkit is built on expert-curated, domain-specific benchmarks from six major scientific fields (e.g., physics, chemistry, astronomy, materials science), ensuring tasks mirror authentic scientific challenges and require deep conceptual, symbolic, and multimodal understanding beyond surface-level pattern recognition.
-
SciEvalKit provides a flexible, open-source evaluation pipeline supporting batch testing, custom model and dataset integration, and transparent, reproducible results, with empirical evidence showing a significant performance gap—below 60 on scientific tasks despite scores above 90 on general benchmarks—highlighting the need for specialized scientific AI capabilities.
Introduction
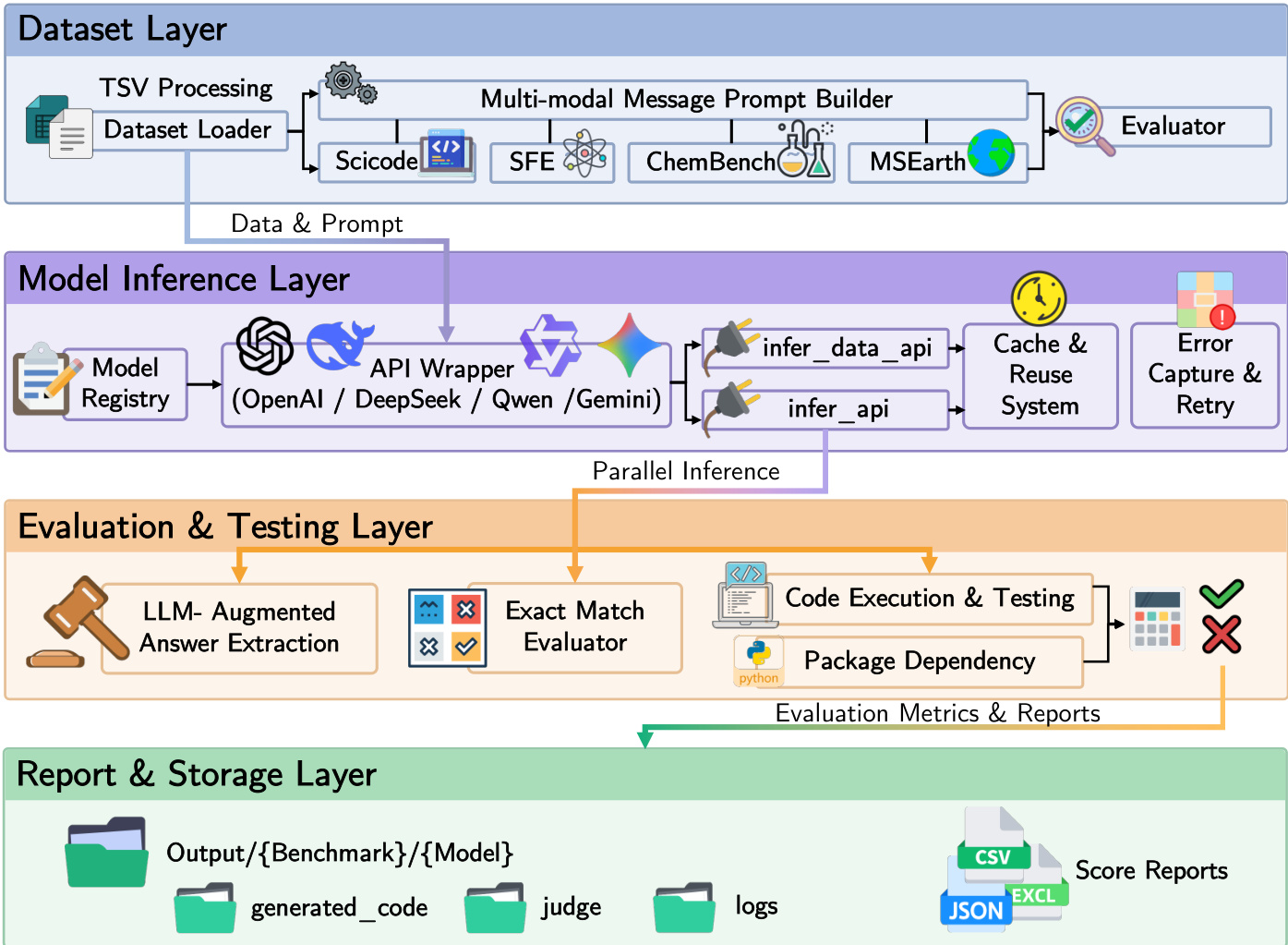
The authors leverage SciEvalKit, an open-source evaluation toolkit, to address the growing need for rigorous, domain-specific assessment of scientific intelligence in large language and multimodal models. Current benchmarks fall short by focusing on narrow, surface-level tasks—such as factual recall or generic image captioning—while failing to capture the complex, multi-representational reasoning required in real scientific workflows, including symbolic manipulation, code generation, hypothesis formation, and multimodal understanding of scientific data. This gap is especially evident in models that perform well on general tasks but underperform on expert-level scientific challenges, revealing a critical disconnect between broad capabilities and domain-specific expertise. The main contribution is a unified, extensible evaluation framework that integrates 15 expert-curated benchmarks across six scientific disciplines, organized around a seven-dimensional taxonomy of scientific intelligence grounded in cognitive theory. By supporting execution-aware scoring, multimodal inputs, and transparent, reproducible evaluation, SciEvalKit enables capability-oriented assessment that reveals fundamental shortcomings in current models—particularly in symbolic reasoning and visual grounding—while providing a standardized, community-driven platform for advancing AI in science.
Dataset

-
The dataset, SciEvalKit, is a curated benchmark suite designed to evaluate scientific intelligence in large language models across multiple modalities and disciplines. It comprises both text-only and multimodal benchmarks, selected through expert consultation and aligned with real-world scientific workflows.
-
Key subsets include:
- Text-only benchmarks: ChemBench (chemistry and materials science), MaScQA (materials science), ProteinLMBench (biomolecular reasoning), TRQA-lit (biomedical literature inference), PHYSICS (undergraduate physics), CMPhysBench (condensed matter physics), SciCode (scientific code generation), and AstroVisBench (astronomy visualization code).
- Multimodal benchmarks: MSEarth (Earth science with visual figures), SLAKE (clinical imaging with CT/X-ray/MRI and semantic annotations), and SFE (multilingual, multi-disciplinary scientific figures with perception-to-reasoning tasks).
-
Each subset is grounded in authentic scientific content, with tasks drawn from real research contexts. Sizes vary: ChemBench includes 100+ questions, ProteinLMBench has 944 six-choice questions, SFE contains 830 verified visual question-answer pairs, and AstroVisBench uses 110 Jupyter notebooks. All benchmarks undergo expert validation for scientific validity, correct solution rationales, and scoring criteria.
-
The paper uses the data in a training and evaluation split where the benchmarks are used as evaluation tasks only—no training data is derived from them. The model evaluation employs a mixture of benchmarks across disciplines and capabilities, with ratios designed to reflect balanced coverage of the seven core scientific intelligence dimensions: Scientific Multimodal Perception, Understanding, Reasoning, and Text-Only capabilities including Knowledge, Code Generation, Symbolic Reasoning, and Hypothesis Generation.
-
Processing includes expert curation of task formulations, manual verification of answers, and alignment with domain standards. For multimodal tasks, images are paired with precise textual context and metadata such as semantic segmentation masks (SLAKE), geospatial coordinates (MSEarth), and scientific figure captions. SFE uses hierarchical cognitive levels (perception, understanding, reasoning) to structure tasks. Code-based benchmarks (SciCode, AstroVisBench) include executable reference solutions and unit tests for validation.
-
No cropping is applied to images; instead, full scientific figures are used. Metadata construction includes domain labels, task types (multiple-choice, free-form, code generation), modality tags, and expert annotations. The suite is designed for procedural transparency, with detailed descriptions provided in Appendix B and continuous expansion planned for future releases.
Method
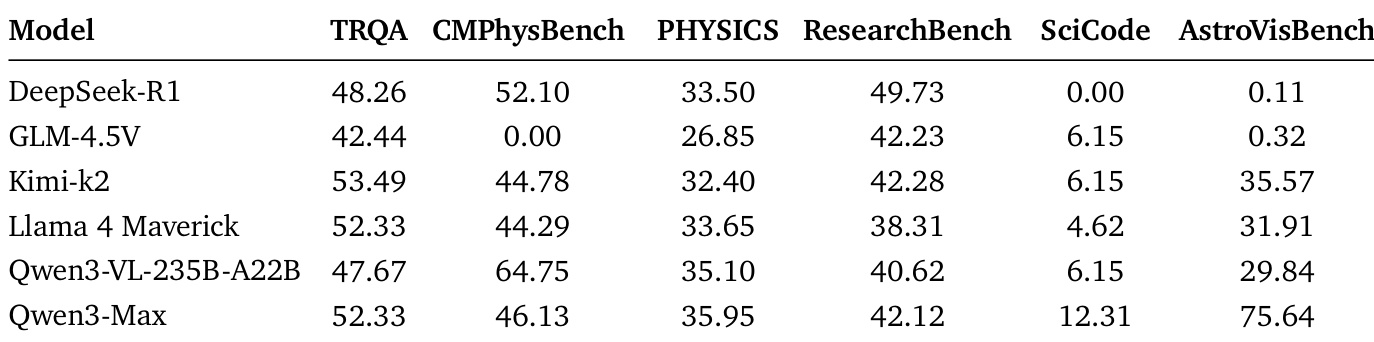
The SciEvalKit framework is structured as a modular, end-to-end pipeline for multimodal scientific benchmarking, organized into four distinct layers: Dataset, Model Inference, Evaluation & Testing, and Report & Storage. This layered architecture ensures clear separation of concerns, enabling extensibility and reproducibility across diverse scientific tasks. The framework's core design emphasizes a unified interface for prompt construction and model prediction, which applies consistently across text-only, image-based, and multi-modal scientific inputs involving diagrams, code, and symbolic expressions.
The Dataset Layer serves as the entry point for data ingestion and task specification. It is responsible for loading structured data from sources such as TSV files and converting raw task data—questions, images, video frame paths, code snippets, and answer options—into a standardized multi-modal message representation. This conversion is handled by the build_prompt() method, which is implemented by each dataset class that inherits from a base abstraction like TextBaseDataset, ImageBaseDataset, or VideoBaseDataset. These base classes provide a unified interface for metadata loading, index normalization, and modality-specific data caching. The multi-modal message is represented as an ordered list of typed content segments, where each segment explicitly declares its modality (e.g., text, image, video) and payload. This explicit specification ensures consistent interpretation by the model. The framework supports advanced message packing for video or sequential images when required. Additionally, each dataset class provides a standardized .evaluate() method that takes model predictions and applies dataset-specific scoring, which may involve exact matching, choice extraction, code execution, or LLM-based judging.
The Model Inference Layer mediates between the structured prompts generated by the Dataset Layer and the model outputs. It is responsible for model instantiation and inference execution. Model instantiation is managed by the build_model_from_config function, which resolves model metadata from a registry of supported VLMs. Each model object exposes a unified .generate(message, dataset) interface, abstracting the underlying execution method—whether it is local inference via vLLM or PyTorch-based implementations, or API-based cloud models like OpenAI, DeepSeek, Gemini, or Anthropic. Inference workflows are orchestrated by functions such as infer_data(), infer_data_api(), and infer_data_job_video(), which provide transparent support for batching, parallel token generation, retry mechanisms, and error tolerance. These functions construct messages from dataset prompts and invoke the model's .generate() method in a consistent manner, thereby abstracting away differences in backend execution, request formatting, and batching logic. Models may optionally override prompt formatting by checking a use_custom_prompt(dataset_name) flag, while still conforming to the unified interface contract.
The Evaluation & Testing Layer processes the model predictions generated by the inference layer. It performs capability-aligned scoring through a combination of deterministic and LLM-augmented evaluation paths. The framework provides multiple evaluation utilities, including exact matching, semantic retrieval, numerical scoring, and code execution. For code-execution tasks, such as those involving scientific programming, the framework invokes sandboxed Python environments to verify the computational correctness and visual output fidelity of the generated code. The evaluate() function, which is standardized across all datasets, applies the appropriate scoring method based on the task type. This layer also includes a build_judge() function for LLM-based judging, which provides a flexible mechanism for evaluating complex or open-ended responses. The evaluation pipeline is designed to be modular, allowing researchers to incorporate new datasets or evaluation strategies without modifying the core inference or scoring logic.
The Report & Storage Layer ensures the reproducibility and transparency of the entire benchmarking process. It manages the storage of all outputs, including predictions, logs, reasoning traces, metadata, and evaluation results. The framework follows a structured file convention, with helper functions like get_pred_file_path(), prepare_reuse_files(), and get_intermediate_file_path() ensuring consistency across model runs. Final evaluation metrics are serialized in standard formats such as CSV, JSON, or XLSX, facilitating longitudinal comparison and leaderboard hosting. This layer provides a complete audit trail of the benchmarking process, from data ingestion to final results, enabling researchers to reproduce and validate experiments.
Experiment
- Conducted capability-oriented evaluation across five scientific reasoning dimensions: Scientific Multimodal Perception, Understanding, Reasoning, Code Generation, Symbolic Reasoning, and Hypothesis Generation, with scores computed as averages over domain-specific benchmarks to ensure balanced assessment.
- Evaluated models using a hybrid scoring paradigm combining rule-based matching, semantic LLM-based judging, and execution-based verification, tailored to diverse answer formats including MCQ, code, open-ended text, and fill-in-the-blank.
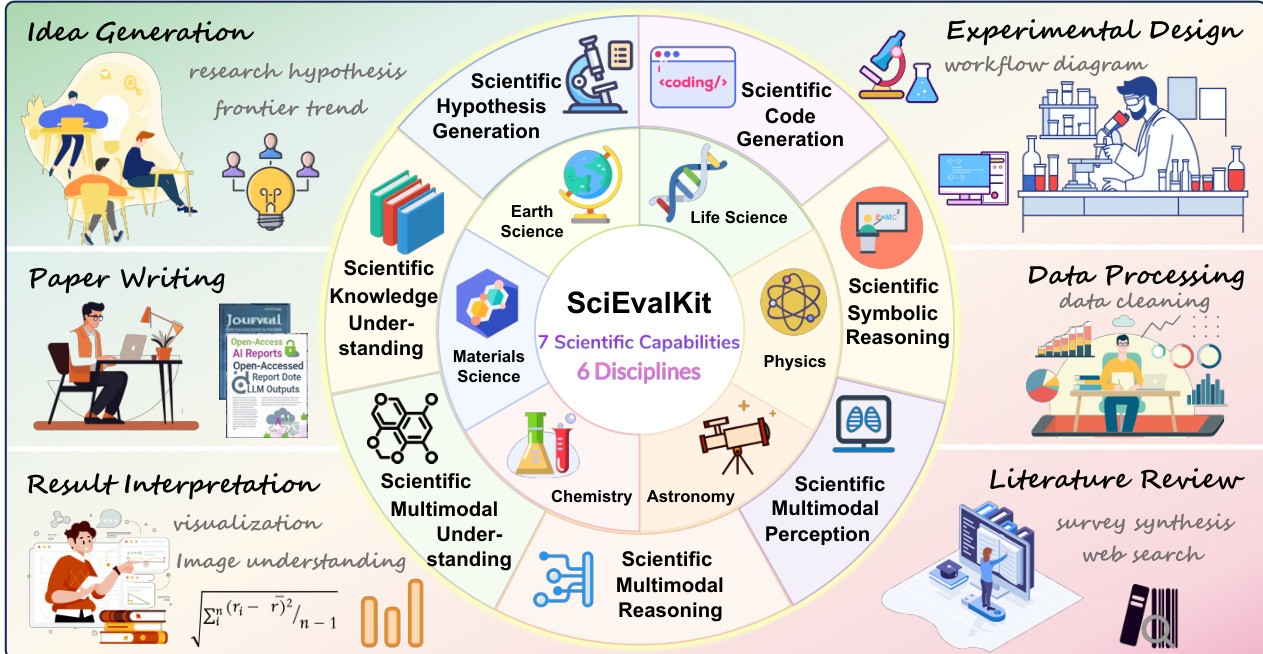
- On Scientific Knowledge Understanding, top models (Gemini-3-Pro, GPT-o3, GPT-5) achieved high scores (up to 76.05), indicating strong factual recall and concept comprehension, but performance in Code Generation and Symbolic Reasoning remained low (e.g., Gemini-3-Pro: 29.57, Qwen3-Max: 43.97), revealing a persistent gap in executable and formal reasoning.
- Qwen3-Max outperformed others in Code Generation and Symbolic Reasoning, demonstrating strong formal reasoning capabilities, while Gemini-3-Pro led in overall scientific text and multimodal performance.
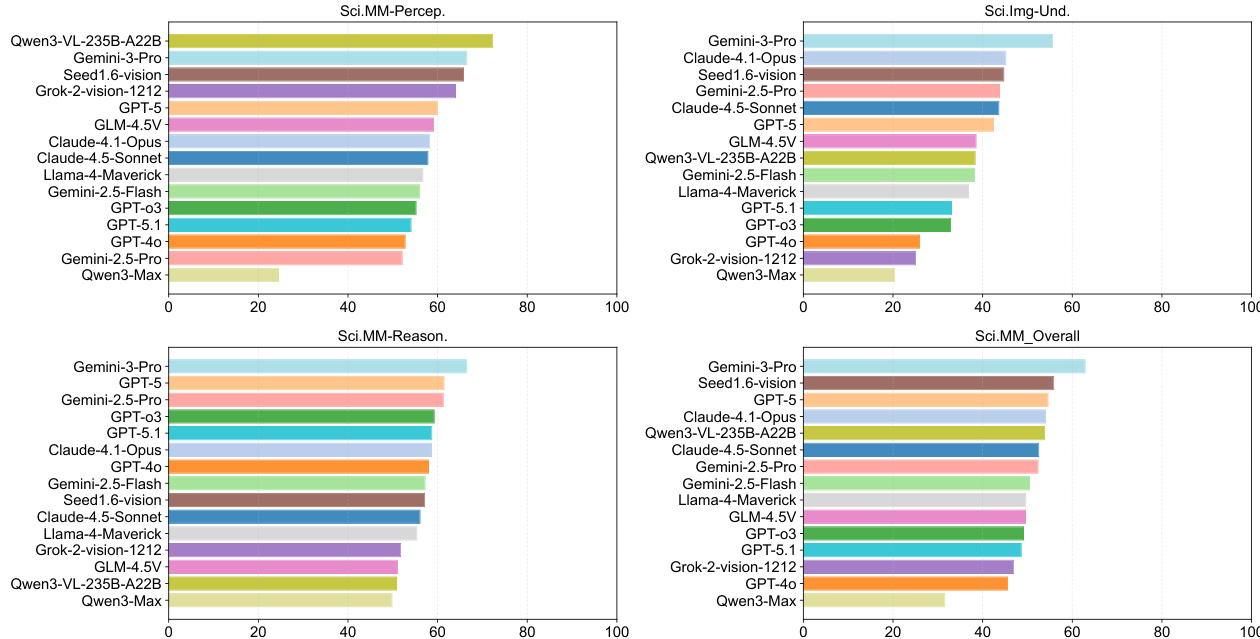
- In multimodal tasks, Gemini-3-Pro achieved the most balanced performance across perception, understanding, and reasoning, whereas Qwen3-VL-235B-A22B excelled in perception but lagged in higher-level understanding and reasoning, highlighting a lack of cross-modal integration.
- Scientific Multimodal Reasoning showed the highest variance among models, serving as the strongest discriminative signal, while perception tasks were more saturated and less indicative of advanced scientific intelligence.
- Execution-based evaluation confirmed that even top models struggle with generating correct, executable scientific code, underscoring the challenge of translating scientific intent into reliable computational procedures.
The authors use the table to evaluate large language models across six scientific benchmarks, including TRQA, CMPHysBench, PHYSICS, ResearchBench, SciCode, and AstroVisBench. Results show that Qwen3-Max achieves the highest score on AstroVisBench and performs competitively across other benchmarks, while DeepSeek-R1 and GLM-4.5V show lower performance, particularly on SciCode and AstroVisBench.
The authors use a capability-oriented evaluation framework to assess models across scientific multimodal perception, understanding, and reasoning. Results show that Gemini-3-Pro achieves the highest scores across all three dimensions, with strong performance in multimodal understanding and reasoning, while Qwen3-VL-235B-A22B leads in perception but shows significant drops in higher-level reasoning tasks.
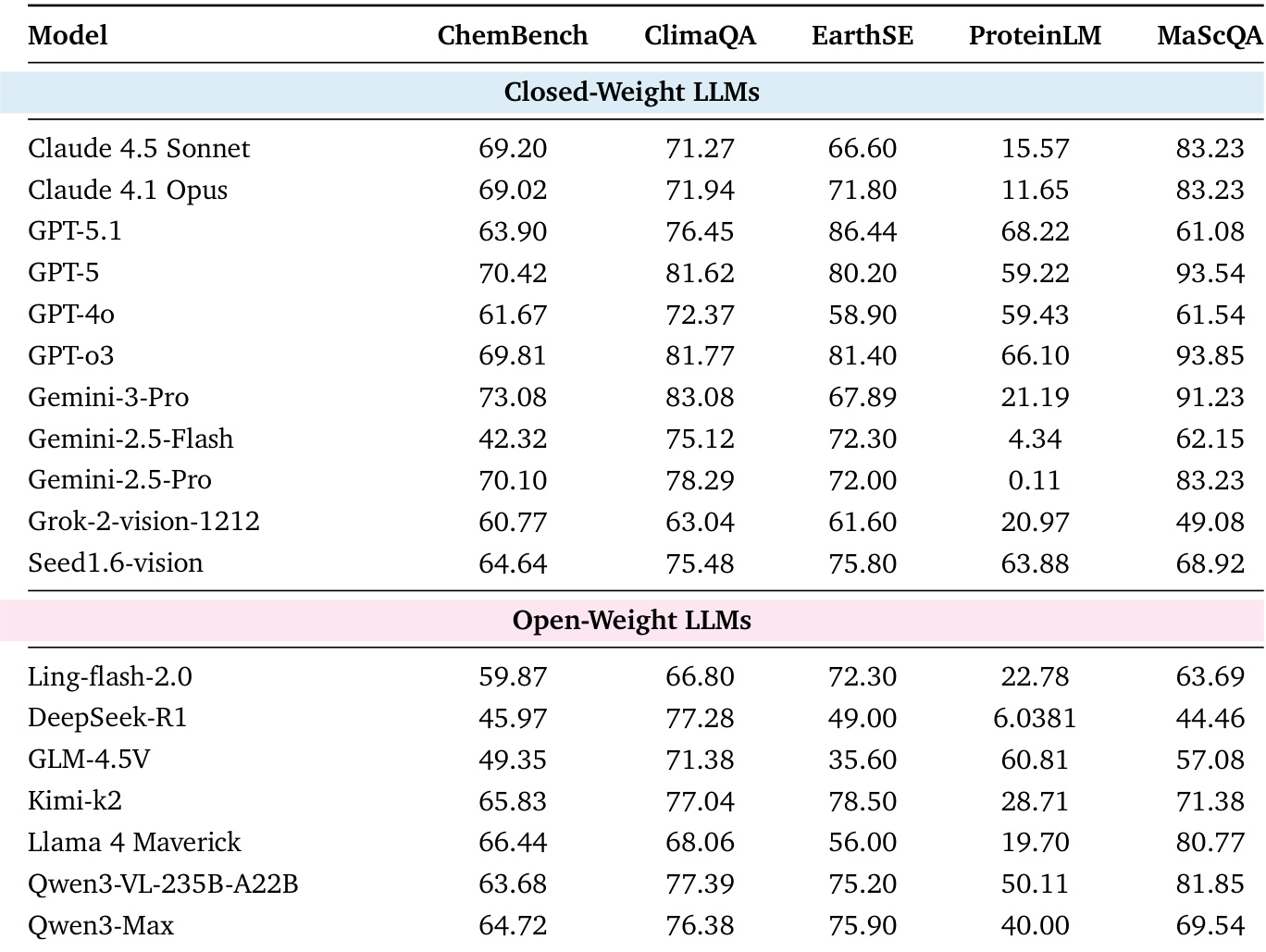
The authors use a capability-oriented evaluation framework to assess large language models across scientific text and multimodal tasks, with results showing that models achieve high scores in Scientific Knowledge Understanding but struggle with Scientific Code Generation and Symbolic Reasoning. The table reveals that Gemini-3-Pro and GPT-5 lead in most benchmarks, while open-weight models like Qwen3-Max and Qwen3-VL-235B-A22B show competitive performance, particularly in code generation and multimodal perception, though they lag in deeper reasoning tasks.
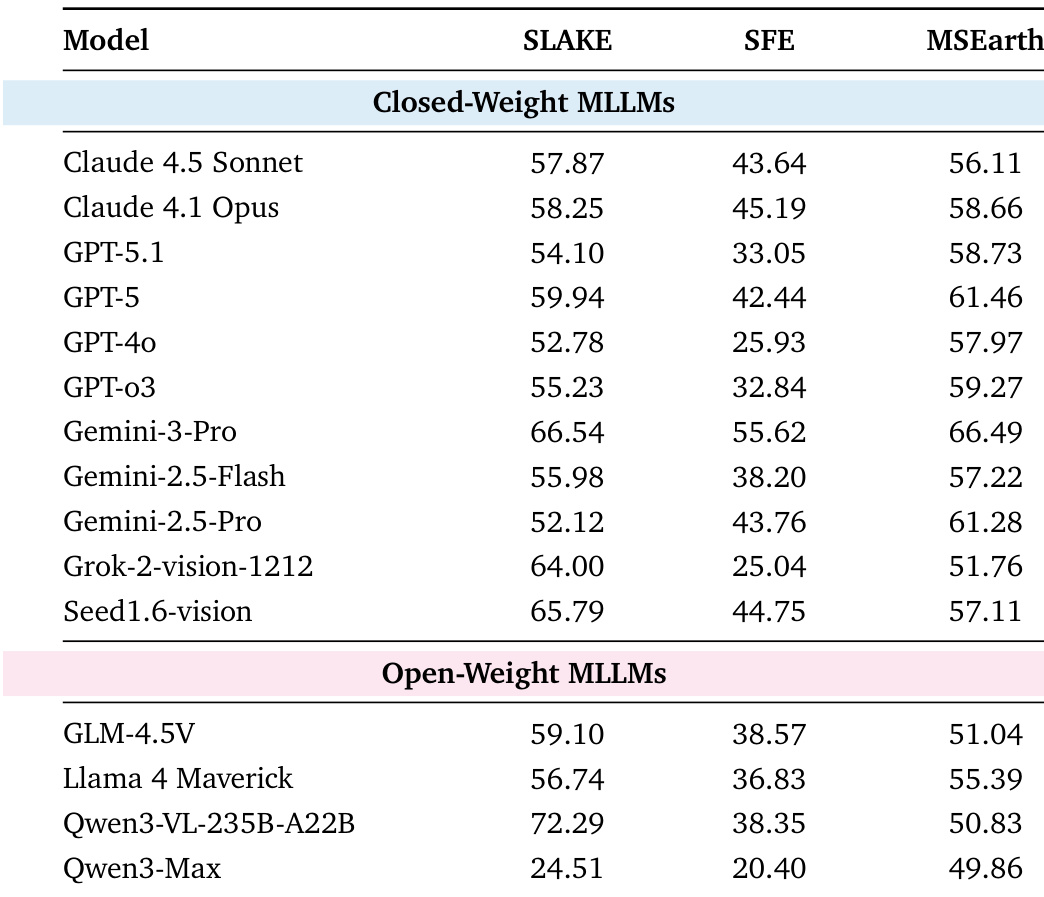
The authors use the table to evaluate multimodal language models on three scientific benchmarks: SLAKE, SFE, and MSearth, focusing on visual reasoning, code-based visualization, and entity localization. Results show that Qwen3-VL-235B-A22B achieves the highest score on SLAKE, while Gemini-3-Pro leads on SFE and MSearth, indicating strong performance across different multimodal tasks. Among open-weight models, Qwen3-VL-235B-A22B outperforms others on SLAKE, but Qwen3-Max shows significantly lower scores across all benchmarks, highlighting a performance gap between models specialized in visual perception and those focused on text-based reasoning.
The authors use a capability-oriented evaluation framework to assess large language models across five scientific competencies, with Table 2 presenting results for scientific text capabilities. Results show that Gemini-3-Pro achieves the highest scores across most dimensions, particularly in Scientific Knowledge Understanding and Hypothesis Generation, while Code Generation remains the weakest capability overall. Among open-weight models, Qwen3-Max performs competitively, leading in Code Generation and achieving strong scores in other text-based competencies.