Command Palette
Search for a command to run...
T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
Abstract
Text-to-Audio-Video (T2AV) generation aims to synthesize temporally coherent video and semantically synchronized audio from natural language, yet its evaluation remains fragmented, often relying on unimodal metrics or narrowly scoped benchmarks that fail to capture cross-modal alignment, instruction following, and perceptual realism under complex prompts. To address this limitation, we present T2AV-Compass, a unified benchmark for comprehensive evaluation of T2AV systems, consisting of 500 diverse and complex prompts constructed via a taxonomy-driven pipeline to ensure semantic richness and physical plausibility. Besides, T2AV-Compass introduces a dual-level evaluation framework that integrates objective signal-level metrics for video quality, audio quality, and cross-modal alignment with a subjective MLLM-as-a-Judge protocol for instruction following and realism assessment. Extensive evaluation of 11 representative T2AVsystems reveals that even the strongest models fall substantially short of human-level realism and cross-modal consistency, with persistent failures in audio realism, fine-grained synchronization, instruction following, etc. These results indicate significant improvement room for future models and highlight the value of T2AV-Compass as a challenging and diagnostic testbed for advancing text-to-audio-video generation.
One-sentence Summary
Researchers from Nanjing University, Kuaishou Technology, and Chinese Academy of Sciences propose T2AV-Compass, a unified benchmark using 500 complex prompts and a dual-level evaluation framework—integrating objective signal metrics with MLLM-as-judge assessments—to rigorously evaluate cross-modal alignment, instruction following, and perceptual realism in text-to-audio-video generation, revealing critical shortcomings in realism and synchronization across 11 state-of-the-art models.
Key Contributions
- Existing Text-to-Audio-Video (T2AV) evaluation is fragmented, relying on unimodal metrics that fail to assess cross-modal alignment, instruction following, and perceptual realism under complex prompts. T2AV-Compass addresses this with a unified benchmark of 500 diverse, complex prompts generated via a taxonomy-driven pipeline to ensure semantic richness and physical plausibility.
- The benchmark introduces a dual-level evaluation framework combining objective signal-level metrics for video/audio quality and cross-modal alignment with a subjective MLLM-as-a-Judge protocol. This protocol uses granular QA checklists and violation checks to assess high-level semantic logic, instruction following, and realism with enhanced interpretability.
- Extensive testing of 11 state-of-the-art T2AV systems, including proprietary models like Veo-3.1 and Kling-2.6, reveals critical gaps in audio realism, fine-grained synchronization, and instruction adherence. Results confirm even top models fall substantially short of human-level performance, highlighting significant room for improvement in the field.
Introduction
Text-to-Audio-Video (T2AV) generation synthesizes temporally coherent video and semantically synchronized audio from natural language descriptions, a capability critical for immersive media creation but hindered by fragmented evaluation methods that fail to assess cross-modal alignment, instruction following, and perceptual realism under complex prompts. Prior benchmarks rely on unimodal metrics or narrowly scoped tests, overlooking fine-grained constraints like off-screen sound, physical causality, and multi-source audio mixing, which prevents holistic assessment of model performance. The authors address this by introducing T2AV-Compass, a unified benchmark featuring 500 taxonomy-driven complex prompts and a dual-level evaluation framework that combines objective signal metrics for video/audio quality with an MLLM-as-a-Judge protocol for subjective realism and instruction adherence. Their evaluation of 11 state-of-the-art systems reveals a persistent audio realism bottleneck, underscoring the framework's diagnostic value in exposing critical gaps for future research.
Dataset
The authors use T2AV-Compass, a 500-prompt benchmark designed exclusively for text-to-audio-video (T2AV) evaluation, constructed via two complementary streams:
-
Community-sourced prompts (400 prompts):
- Aggregated from VidProM, Kling AI community, LMArena, and Shot2Story to capture diverse user intents.
- Filtered through semantic deduplication (cosine similarity ≥0.8 using all-mpnet-base-v2 embeddings) and square-root sampling to balance frequent/niche topics.
- Enhanced via Gemini-2.5-Pro for descriptive density (adding cinematography constraints, motion dynamics, and acoustic details), followed by manual auditing to remove static/illogical scenes.
-
Real-world video inversion (100 prompts):
- Sourced from post-October 2024 YouTube clips (4–10 seconds, 720p resolution) to avoid data leakage.
- Filtered for spatiotemporal integrity (no watermarks/rapid cuts), audiovisual complexity (1–4 sound layers, 30% speech), and thematic diversity (Modern Life, Sci-Fi, etc.).
- Converted to prompts via Gemini-2.5-Pro dense captioning, with human verification to align with ground-truth video dynamics.
The dataset is used solely for evaluation—not training—via a dual-level framework:
- Objective metrics assess unimodal quality (video aesthetics, audio realism) and cross-modal alignment (temporal sync, semantic consistency).
- Subjective MLLM-as-judge evaluations employ structured checklists derived from prompts, covering instruction following (via slot extraction) and perceptual realism (e.g., physical plausibility).
Key processing includes:
- Cropping YouTube clips to 5–10-second segments for meaningful semantic units.
- Converting prompts into hierarchical metadata (e.g., cinematography, sound types) using JSON schemas for systematic scoring.
- Ensuring complexity via high token counts (mirroring real-world queries) and fine-grained challenges (e.g., 72.8% prompts feature overlapping audio events).
Method
The authors leverage a dual-level evaluation framework for text-to-audio-video (T2AV) generation, designed to systematically assess both objective fidelity and subjective semantic alignment. At the core of this framework is T2AV-Compass, a unified benchmark that decomposes evaluation into two complementary tiers: objective metrics and reasoning-driven subjective judgment.
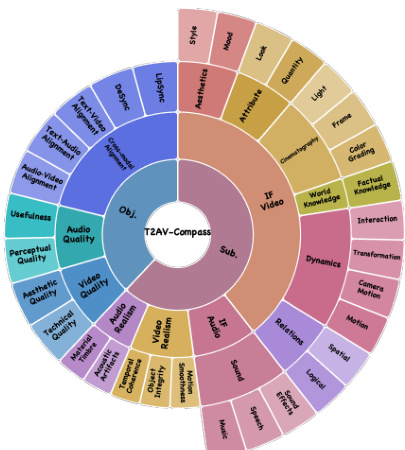
At the objective level, performance is measured across three pillars: video quality, audio quality, and cross-modal alignment. These are further broken down into granular sub-dimensions such as Motion Smoothness Score (MSS), Object Integrity Score (OIS), and Temporal Coherence Score (TCS) for video realism; Acoustic Artifacts Score (AAS) and Material-Timbre Consistency (MTC) for audio realism; and alignment metrics that quantify synchronization between modalities. Refer to the framework diagram for a visual mapping of these dimensions, which are organized into concentric rings representing their hierarchical relationships and functional groupings.
The subjective evaluation layer employs an MLLM-as-a-Judge protocol that mandates explicit reasoning before scoring. This protocol operates along two tracks: Instruction Following (IF), which verifies prompt adherence via granular QA checklists derived from the input prompt, and Perceptual Realism (PR), which diagnoses physical and perceptual violations independent of the prompt. The QA generation pipeline begins with prompt sourcing from models like VidProM or LMArena, followed by filtering, LLM rewriting, and human refinement to produce a final prompt suite. From this suite, automated QA checklists are generated per dimension—such as Look, Quantity, Motion, or Sound Effects—using slot extraction and dimension mapping, with human validation ensuring fidelity. The realism track further incorporates temporal coherence checks (TCS) and material-timbre consistency (MTC) to evaluate physical plausibility.
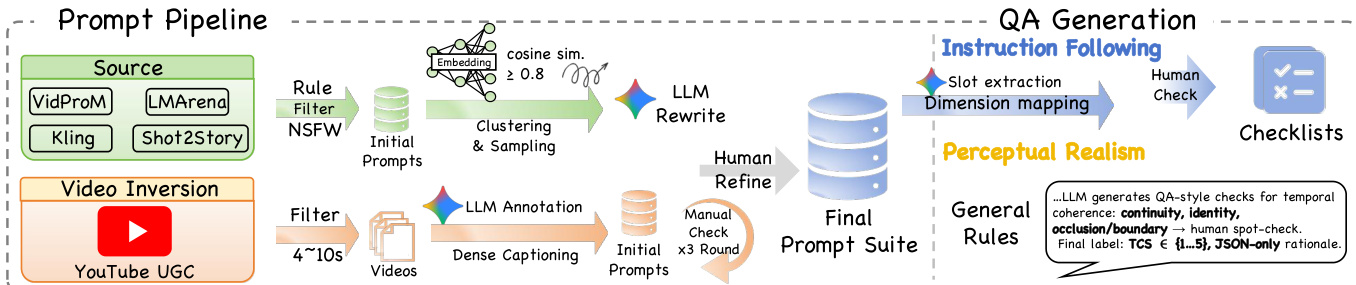
Each QA checklist is structured as binary (Yes/No) questions targeting specific sub-dimensions—for example, verifying whether “a red wooden table” appears (Look), or whether “a character runs left to right” occurs (Motion). These questions are generated per dimension (Attribute, Dynamics, Cinematography, etc.) and are designed to be objectively verifiable from the generated video. The framework enforces a reasoning-first protocol: the judge must articulate its rationale before assigning a 5-point score, enhancing interpretability and enabling precise error attribution. This dual-path evaluation ensures that both technical fidelity and high-level semantic coherence are rigorously assessed.
Experiment
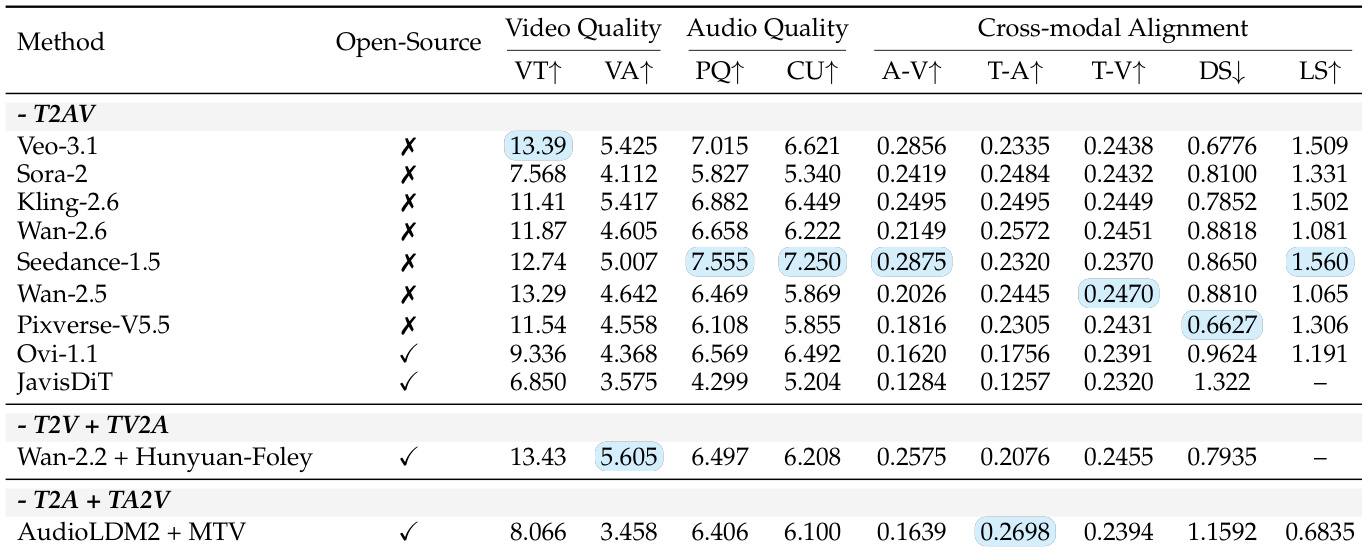
- Evaluated 11 T2AV systems using objective metrics covering video quality (VT, VA), audio quality (PQ, CU), and cross-modal alignment (T-A, T-V, A-V, temporal sync).
- Closed-source models (e.g., Veo-3.1, Sora-2) surpassed open-source counterparts across all objective metrics and semantic evaluations.
- Veo-3.1 achieved the highest overall average but showed significant deficiencies in Audio Realism, highlighting an industry-wide bottleneck where top models like Seedance-1.5 scored only 53.84 on Audio Realism, with most models stagnating in the 30s.
- Composed pipelines (Wan-2.2 + HunyuanFoley) excelled in Video Realism, surpassing all end-to-end models and demonstrating superior unimodal fidelity.
- Veo-3.1 and Wan-2.5 led in visual instruction-following, particularly in Dynamics, while Sora-2 lagged in temporal coherence despite strengths in static dimensions like World knowledge.
- MTC (Material-Timbre Consistency) emerged as the most challenging audio dimension, with Veo-3.1 showing balanced high performance and Sora-2 strong in OIS/TCS but weak in AAS.
The authors evaluate multiple text-to-audiovisual models across fine-grained instruction-following dimensions, revealing that end-to-end closed-source models like Veo-3.1 and Wan-2.5 consistently outperform open-source and composed systems in Dynamics, Relations, and World Knowledge. Composed pipelines such as Wan-2.2 + HunyuanFoley show competitive performance in specific areas like Aesthetics and Relations, but generally lag in temporal and interactional coherence. Open-source models including Ovi-1.1 and JavisDiT exhibit significantly lower scores across nearly all dimensions, particularly in Motion and Transform, indicating persistent challenges in handling complex temporal and structural instructions.
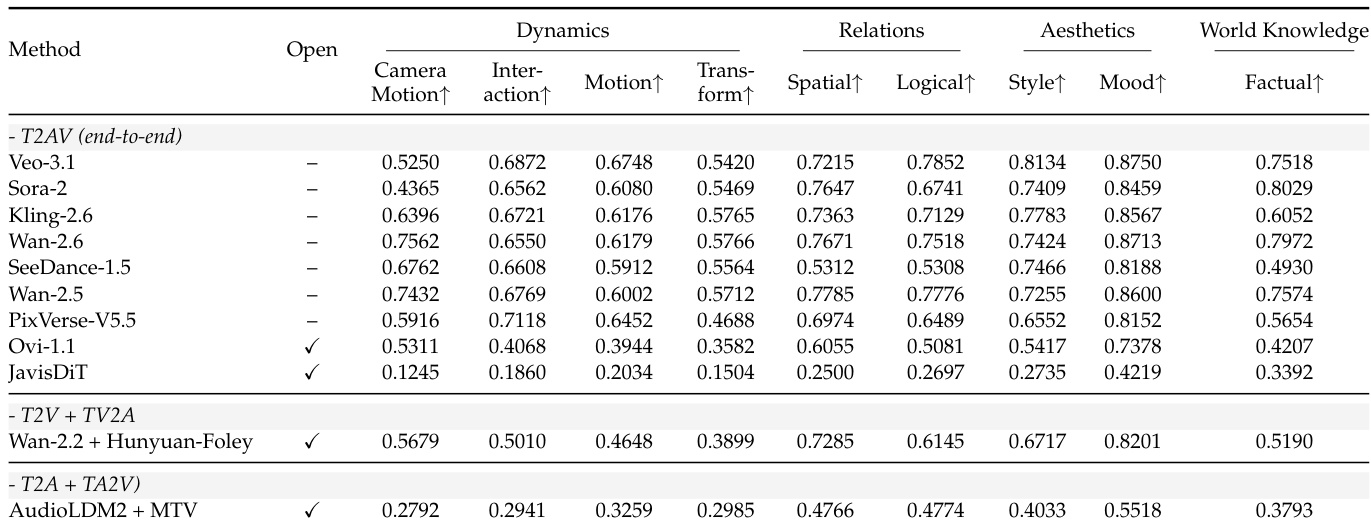
The authors use objective metrics to evaluate 11 T2AV systems across video quality, audio quality, and cross-modal alignment, revealing that closed-source models generally outperform open-source ones. Results show Veo-3.1 leads in video technical quality (VT) and cross-modal alignment (T-V), while composed pipelines like Wan-2.2 + Hunyuan-Foley achieve the highest video aesthetic score (VA). Audio quality remains a bottleneck, with even top models scoring modestly on perceptual quality (PQ) and content usefulness (CU), and synchronization metrics (DS, LS) vary widely across systems.
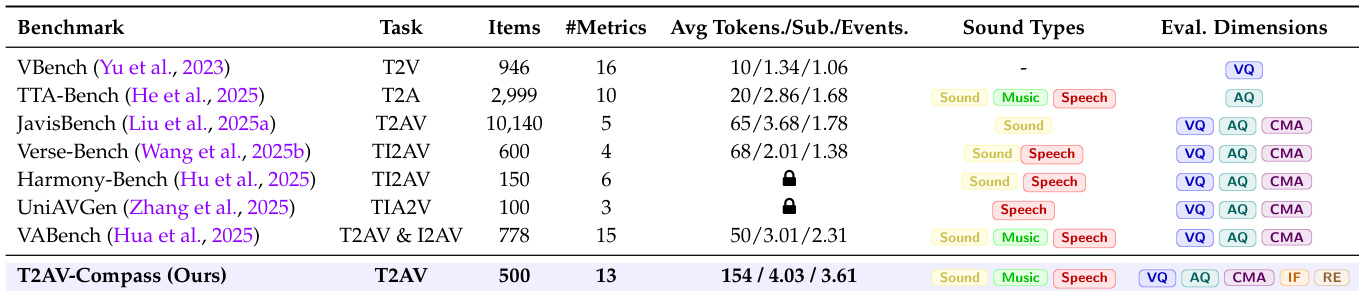
The authors use T2AV-Compass to evaluate text-to-audiovisual generation systems across 13 metrics, covering video quality, audio quality, cross-modal alignment, instruction following, and realism, with an average of 154 tokens per sample and support for sound, music, and speech. Results show T2AV-Compass includes more diverse evaluation dimensions than prior benchmarks while maintaining a moderate scale of 500 items, enabling comprehensive yet tractable assessment of multimodal coherence and perceptual fidelity.
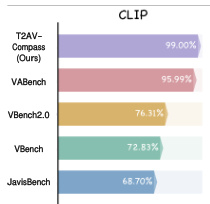
The authors use CLIP-based alignment scores to evaluate cross-modal consistency in text-to-audiovisual generation, with T2AV-Compass achieving the highest score at 99.00%. Results show that T2AV-Compass significantly outperforms prior benchmarks including VABench, VBench2.0, and JavisBench, indicating stronger semantic alignment between generated content and input prompts.
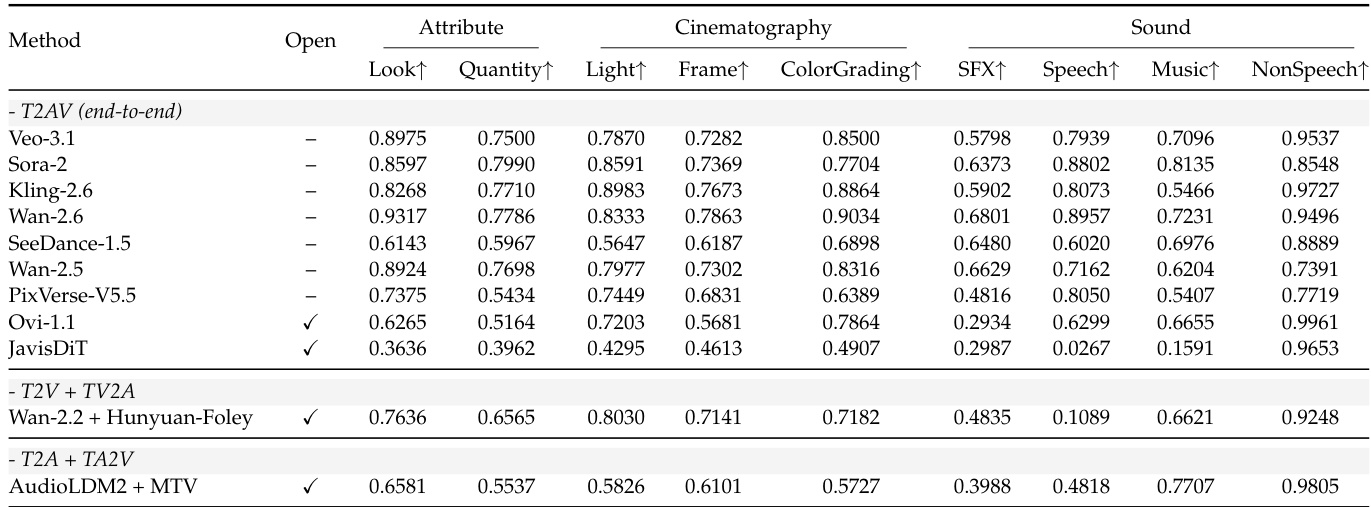
The authors evaluate multiple T2AV systems across visual and auditory dimensions using objective metrics, revealing that closed-source models generally outperform open-source ones in attribute and cinematography scores, while composed pipelines like Wan-2.2 + HunyuanFoley show competitive performance in specific areas such as non-speech audio fidelity. Results indicate a consistent gap in audio realism across all models, with speech and music scores notably lower than visual metrics, highlighting a persistent cross-modal bottleneck. Veo-3.1 leads in most visual categories but underperforms in sound-related metrics, underscoring the challenge of achieving balanced multimodal generation.