Command Palette
Search for a command to run...
Unified Video Editing with Temporal Reasoner
Unified Video Editing with Temporal Reasoner
Xiangpeng Yang Ji Xie Yiyuan Yang Yan Huang Min Xu Qiang Wu
Abstract
Existing video editing methods face a critical trade-off: expert models offer precision but rely on task-specific priors like masks, hindering unification; conversely, unified temporal in-context learning models are mask-free but lack explicit spatial cues, leading to weak instruction-to-region mapping and imprecise localization. To resolve this conflict, we propose VideoCoF, a novel Chain-of-Frames approach inspired by Chain-of-Thought reasoning. VideoCoF enforces a ``see, reason, then edit" procedure by compelling the video diffusion model to first predict reasoning tokens (edit-region latents) before generating the target video tokens. This explicit reasoning step removes the need for user-provided masks while achieving precise instruction-to-region alignment and fine-grained video editing. Furthermore, we introduce a RoPE alignment strategy that leverages these reasoning tokens to ensure motion alignment and enable length extrapolation beyond the training duration. We demonstrate that with a minimal data cost of only 50k video pairs, VideoCoF achieves state-of-the-art performance on VideoCoF-Bench, validating the efficiency and effectiveness of our approach. Our code, weight, data are available at https://github.com/knightyxp/VideoCoF.
Summarization
Researchers from the University of Technology Sydney and Zhejiang University propose VideoCoF, a Chain-of-Frames method that introduces reasoning tokens to enable mask-free, precise instruction-to-region video editing. By mimicking Chain-of-Thought reasoning, VideoCoF achieves fine-grained spatial control and motion coherence without task-specific priors, outperforming prior models on VideoCoF-Bench with minimal training data.
Key Contributions
- Introduces a novel Chain-of-Frames approach that enables fine-grained video editing by leveraging temporal reasoning, achieving state-of-the-art performance on a benchmark dataset.
- Proposes a unified model, VideoCoF, which integrates source tokens with noised edit tokens along the temporal dimension to ensure motion coherence and precise instruction-to-region alignment.
- Demonstrates superior performance on standard benchmarks, outperforming baseline methods by +15.14% in instruction-following accuracy and enabling effective video editing without reliance on user-provided masks.
Introduction
The authors leverage advances in video diffusion to address a key limitation in existing video editing methods—imprecise spatial control and poor instruction following—by introducing a unified, reasoning-based framework. Current approaches fall into two categories: expert models that use adapter modules with external masks for precise edits but require per-task overhead, and unified in-context learning models that enable mask-free editing but suffer from weak spatial accuracy due to lack of explicit region cues. The core challenge lies in balancing the need for high edit precision with the flexibility of mask-free, unified editing.
To resolve this trade-off, the authors propose VideoCoF, a Chain-of-Frames framework that embeds temporal reasoning into video diffusion models by predicting reasoning tokens—latent representations of edit regions—before generating the edited video. This enforces a “see → reason → edit” workflow inspired by Chain-of-Thought prompting, enabling accurate instruction-to-region alignment without user-provided masks.
Key innovations include:
- A Chain-of-Frames mechanism that explicitly models edit region prediction as a reasoning step, improving localization accuracy in unified video editing.
- A soft grayscale reasoning format that effectively represents spatial edit regions in latent space, enhancing instruction following.
- A RoPE alignment strategy that resets temporal positional indices to maintain motion coherence and support length extrapolation, enabling inference on videos up to 4× longer than training duration.
Dataset
- The authors use a unified dataset of 50k video pairs for training, carefully balanced across four core editing tasks: object addition (10k), object removal (15k), object swap (15k), and local style transfer (10k).
- The dataset combines filtered open-source videos from Señorita 2M with synthetically generated edits, ensuring diversity and instance-level complexity.
- For object addition and removal, the authors apply MiniMax-Remover to Señorita videos to create paired data, with the original as source and edited version as target (or vice versa); the removal set includes 5k multi-instance samples for robustness.
- Object swap and local style transfer samples are generated using VACE-14B in inpainting mode, guided by precise masks from Grounding DINO and creative prompts from GPT-4o to ensure diverse, high-quality edits.
- All generated video pairs undergo strict filtering using Dover Score (aesthetic quality) and VIE Score (editing fidelity), resulting in a distilled, high-quality subset used for training.
- The final training data contains no overlap with the evaluation set, enabling clean assessment of generalization.
- The authors introduce VideoCoF-Bench, a new benchmark of 200 videos from Pexels and adapted samples from EditVerse and UNIC-Bench, with no training data overlap.
- VideoCoF-Bench covers the same four editing tasks (50 samples each), half at the instance level, requiring fine-grained reasoning and instruction following.
- To ensure fair comparison, UNIC-Bench samples are modified by removing reference identity images, standardizing evaluation to text-driven editing only.
- The model is trained on the 50k filtered and synthesized video pairs, with equal task representation, to develop strong instruction-following and instance-level editing capabilities.
Method
The authors leverage a unified video editing framework called VideoCoF, built upon a VideoDiT backbone, to perform instruction-driven video editing through a structured reasoning-then-generation pipeline. The core innovation lies in the Chain of Frames (CoF) paradigm, which explicitly decomposes the editing task into three sequential phases: seeing the source video, reasoning about the edit region, and generating the edited content. This design addresses the limitation of prior in-context editing methods that concatenate source and target tokens without explicit spatial grounding, often resulting in misaligned edits.
Refer to the framework diagram, which illustrates how source, reasoning, and target video tokens are encoded separately via a Video VAE and then temporally concatenated into a single sequence. The model processes this unified sequence end-to-end using self-attention for in-context learning and cross-attention for language conditioning. The reasoning tokens—generated from gray-highlighted masks that visually ground the edit region—are inserted between the source and target tokens. This forces the model to first predict the spatial location of the edit before generating the modified content, mimicking a “seeing, reasoning, then editing” cognitive process.
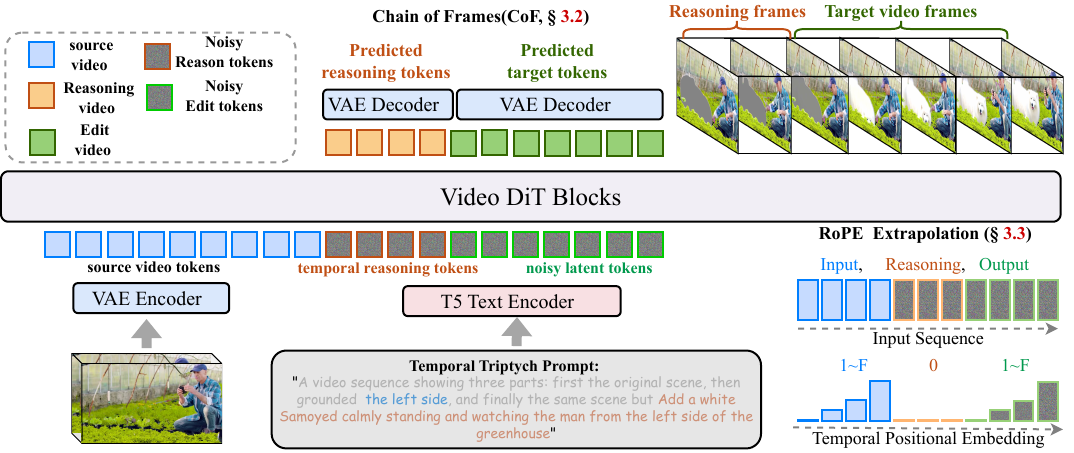
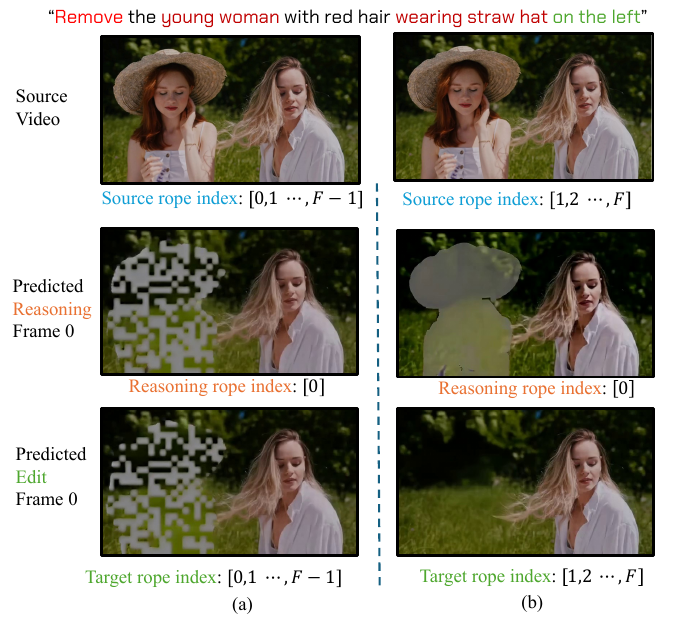
To enable variable-length inference and avoid overfitting to fixed temporal mappings, the authors revisit positional encoding design. Instead of assigning sequential indices across the entire concatenated sequence, they assign temporal RoPE indices [1, F] to both source and target videos, while reserving index 0 exclusively for the reasoning frame. This prevents index collisions that would otherwise cause visual artifacts to propagate from reasoning tokens into the target frames. As shown in the figure below, this isolation ensures clean separation of roles during denoising while preserving the model’s ability to generalize to videos of arbitrary length.
Training proceeds by treating the reasoning and target frames as the generation target. Given a triplet of source, reasoning, and target latents—denoted zs(0), zr(0), and ze(0)—the model receives a partially noised input z(t)=zs(0)∥zr,e(t), where only the reasoning and target portions are progressively noised according to t∈[0,1]. The model predicts the velocity field v=ε−zfull(0), and training minimizes the mean squared error over the reasoning and target frames:
L=L+F1i=F∑2F+L−1vi−[Fθ(z(t),t,c)]i22During inference, the source latents remain fixed while the reasoning and target blocks are initialized from noise and evolved via an ODE solver to their clean state. The final edited video is decoded from the target segment of the denoised latent sequence.
To bridge the gap between text-to-video generation and instruction-based editing, the authors introduce a temporal triptych prompt template: “A video sequence showing three parts: first the original scene, then grounded {ground instruction}, and finally the same scene but {edit instruction}.” This structured prompt embeds the editing intent within the temporal flow of the video, enabling the model to interpret instructions without requiring expensive instruction tuning. As demonstrated in the prompt comparison figure, this approach significantly improves editing accuracy compared to direct instruction formats.

Experiment
- Trained on WAN-14B with 50k video editing pairs, achieving superior performance in instruction following and success ratio
- Achieved 86.27% instruction following accuracy with 25.49% success ratio using a resolution-bucketing strategy across four aspect ratios
- Outperformed baseline methods including ICVE and InstructX by 1.52–7.39% in success ratio and 26.54–29.60% in preservation score
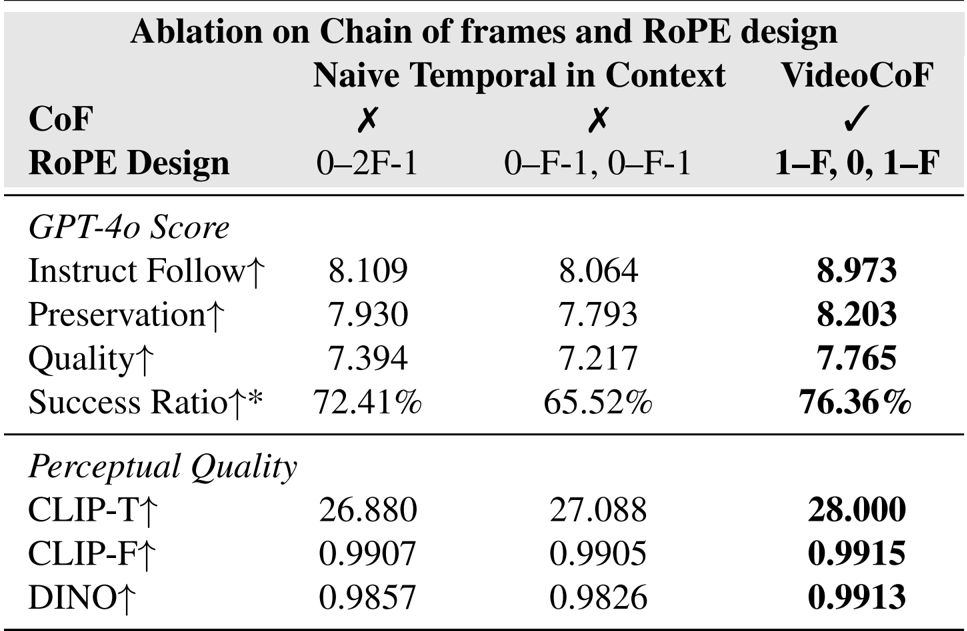
- Validated effectiveness of Chain of Frames (CoF) design through ablation studies on reasoning frames and RoPE alignment
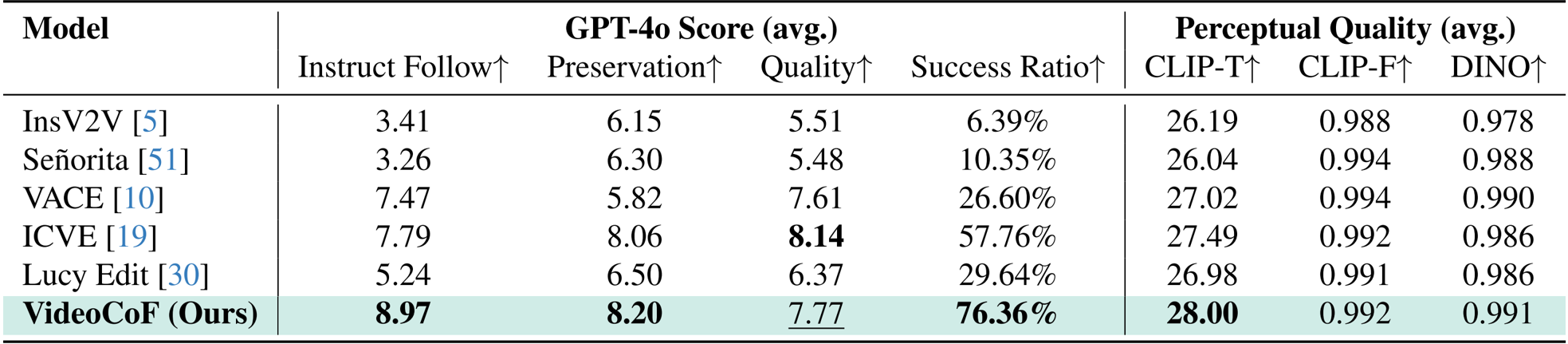
VideoCoF achieves the highest average instruction following score (8.97) and success ratio (76.36%) among all compared models, demonstrating superior precision in executing editing commands. While ICVE leads in visual quality (8.14), VideoCoF outperforms it in preservation (8.20) and perceptual alignment (CLIP-T: 28.00), indicating stronger fidelity to both instruction and original content. The model’s performance is achieved with only 50k training pairs, highlighting its data efficiency relative to larger-scale baselines.
The authors use an ablation study to compare VideoCoF against naive temporal in-context baselines, showing that incorporating reasoning frames and their RoPE alignment design improves instruction following by 10.65% and success ratio by 5.46%. Results show VideoCoF also achieves higher CLIP-T, CLIP-F, and DINO scores, confirming better text alignment and spatio-temporal structure preservation. The RoPE design enables length extrapolation without quality degradation, unlike fixed temporal mapping approaches.
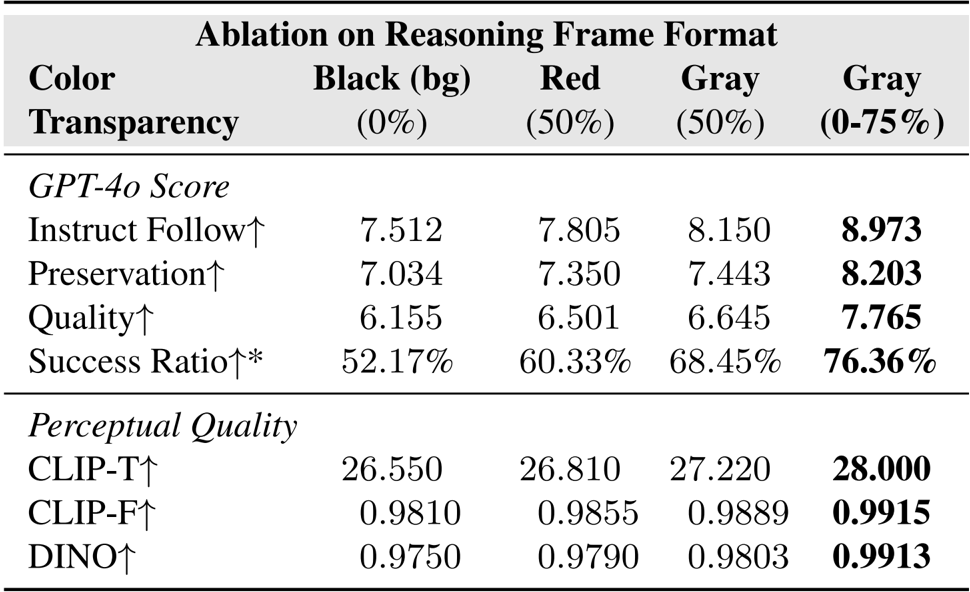
The authors test different reasoning frame formats and find that a progressive gray mask with increasing transparency from 0% to 75% yields the highest scores across all metrics, including instruction following, success ratio, and perceptual quality. This format outperforms static black, red, or uniform gray masks, confirming that gradual transparency enhances spatial guidance without disrupting temporal coherence. Results show consistent gains in both semantic alignment (CLIP-T) and structural consistency (DINO), validating the design’s effectiveness for precise video editing.