Command Palette
Search for a command to run...
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zijian Zhou Ao Qu Zhaoxuan Wu Sunghwan Kim Alok Prakash Daniela Rus Jinhua Zhao Bryan Kian Hsiang Low Paul Pu Liang
Abstract
Modern language agents must operate over long-horizon, multi-turn interactions, where they retrieve external information, adapt to observations, and answer interdependent queries. Yet, most LLM systems rely on full-context prompting, appending all past turns regardless of their relevance. This leads to unbounded memory growth, increased computational costs, and degraded reasoning performance on out-of-distribution input lengths. We introduce MEM1, an end-to-end reinforcement learning framework that enables agents to operate with constant memory across long multi-turn tasks. At each turn, MEM1 updates a compact shared internal state that jointly supports memory consolidation and reasoning. This state integrates prior memory with new observations from the environment while strategically discarding irrelevant or redundant information. To support training in more realistic and compositional settings, we propose a simple yet effective and scalable approach to constructing multi-turn environments by composing existing datasets into arbitrarily complex task sequences. Experiments across three domains, including internal retrieval QA, open-domain web QA, and multi-turn web shopping, show that MEM1-7B improves performance by 3.5x while reducing memory usage by 3.7x compared to Qwen2.5-14B-Instruct on a 16-objective multi-hop QA task, and generalizes beyond the training horizon. Our results demonstrate the promise of reasoning-driven memory consolidation as a scalable alternative to existing solutions for training long-horizon interactive agents, where both efficiency and performance are optimized.
One-sentence Summary
The authors, from Singapore-MIT Alliance for Research and Technology, National University of Singapore, MIT, and Yonsei University, propose MEM1, a reinforcement learning framework enabling language agents to maintain constant memory during long multi-turn interactions by dynamically consolidating relevant information into a compact internal state. Unlike full-context prompting, MEM1 strategically discards redundancy, improving reasoning efficiency and performance—achieving 3.5× better results and 3.7× lower memory use than Qwen2.5-14B-Instruct on complex QA tasks—while generalizing beyond training horizons.
Key Contributions
- Modern language agents face significant challenges in long-horizon, multi-turn interactions due to unbounded memory growth from full-context prompting, which increases computational costs and degrades reasoning performance on long inputs.
- MEM1 introduces an end-to-end reinforcement learning framework that enables constant memory usage by maintaining a compact, shared internal state that jointly supports reasoning and memory consolidation, dynamically integrating relevant information while discarding redundancy.
- Experiments across three domains show MEM1-7B achieves 3.5× higher performance and 3.7× lower memory usage than Qwen2.5-14B-Instruct on a 16-objective multi-hop QA task, while generalizing beyond the training horizon and scaling via a novel dataset composition method for realistic multi-turn environments.
Introduction
Modern language agents are increasingly required to handle long-horizon, multi-turn interactions—such as research, web navigation, and complex decision-making—where they must continuously retrieve information, adapt to new observations, and reason over interdependent queries. However, existing systems typically rely on full-context prompting, appending all prior interactions, which leads to unbounded memory growth, rising computational costs, and degraded reasoning performance, especially when context lengths exceed training limits. These approaches also suffer from inefficient context overload and lack end-to-end optimization of memory management. The authors introduce MEM1, an end-to-end reinforcement learning framework that enables agents to maintain constant memory usage across arbitrarily long tasks by learning to consolidate reasoning and memory into a compact, shared internal state. This state integrates relevant information while discarding redundancy, eliminating the need to retain prior context. To support scalable training, they propose a task augmentation method that composes single-objective datasets into complex, multi-hop sequences. Experiments across retrieval QA, open-domain web QA, and multi-turn shopping tasks show MEM1-7B achieves 3.5× higher performance and 3.7× lower memory usage than Qwen2.5-14B-Instruct on a 16-objective task, while generalizing beyond its training horizon. The work demonstrates that reasoning-driven memory consolidation offers a scalable, efficient alternative to traditional long-context modeling.
Dataset
- The dataset for long-horizon QA is constructed by augmenting a multi-hop QA dataset from [24], which combines data from HotpotQA [59] and Natural Question [26], into a 2-objective composite task.
- Each instance in the dataset consists of a single composite query that interleaves multiple sub-questions from the original corpus, requiring the agent to perform multiple search and reasoning steps to answer all components.
- The training and test splits follow the original papers, with test data drawn from out-of-distribution samples to evaluate generalization.
- For web navigation, the WebShop environment [60] is used, which provides environment-specific rewards during training and enables evaluation of agent behavior in interactive, real-world scenarios.
- The authors use a mixture of training data: the augmented multi-objective QA dataset for QA tasks and WebShop for web navigation, with each task trained separately using reinforcement learning.
- During training, the model is evaluated using exact match (EM) and F1 scores for QA tasks, and final environment reward for WebShop. Efficiency is measured via peak token usage, average dependency, and average inference time.
- To support long-horizon interactions, the agent’s context is programmatically truncated after each search query or answer generation, preserving memory efficiency.
- A meta-info hint [HINT: YOU HAVE {turns_left} TURNS LEFT] is prepended to each tag to guide termination decisions, with a maximum of 6 turns for 1–4 objective tasks and up to 20 turns for more complex ones.
- For retrieval, the system uses Faiss-GPU with an E5 Base model on a Wikipedia 2018 dump for local RAG, retrieving 3 passages per query. For online web search, the Serper API is used to fetch top 10 Google search results (titles, snippets, URLs) without requiring full page retrieval.
Method
The authors leverage a reinforcement learning (RL) framework to train MEM1, an agent designed to maintain constant memory usage during long-horizon reasoning tasks. The core of the architecture revolves around a dynamic context management mechanism that enables the agent to iteratively refine its internal state while discarding irrelevant historical information. At each reasoning step t, the agent generates an internal state ISt, which encapsulates a consolidated summary of past information and reasoning. This internal state is used to determine the next action: either a query queryt to interact with an external environment (such as a search engine or knowledge base) or a direct answer answert. If a query is issued, the environment provides feedback infot, which is then incorporated into the agent's context. The agent subsequently consolidates the tuple (ISt,queryt,infot) into a new internal state ISt+1, which becomes the basis for the next reasoning step. This process ensures that only the most relevant information is retained, as all prior context elements are pruned after each turn. The framework is designed to maintain bounded memory usage, with the agent retaining at most two internal states, two queries, and one piece of environment feedback at any given time. 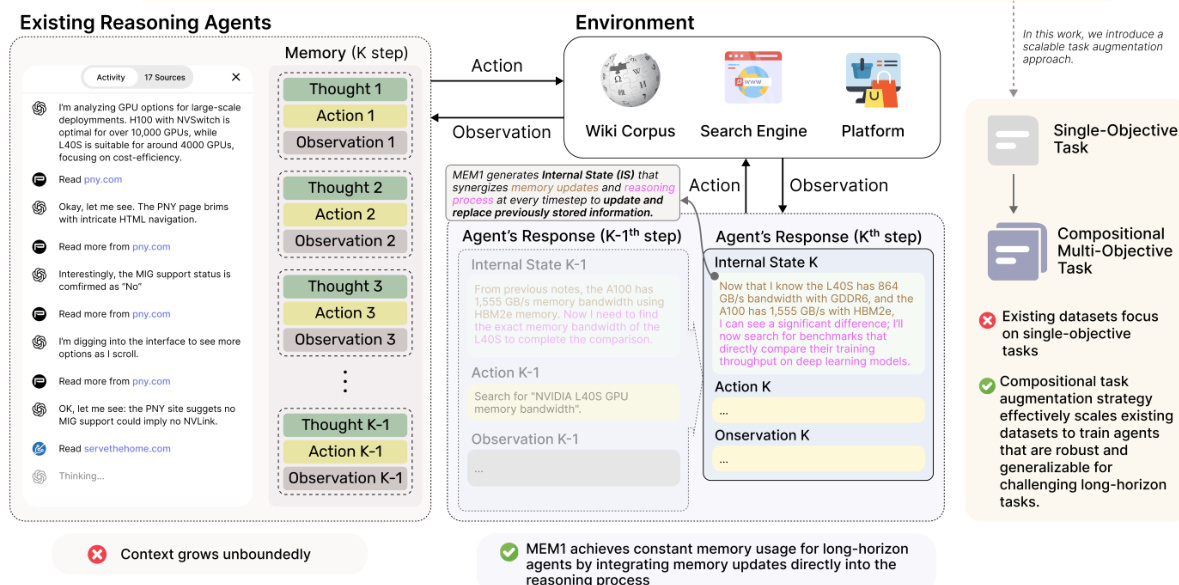
The training process employs a reinforcement learning pipeline where the agent is rewarded for successfully solving tasks that require multiple interactions with the environment. The reward signal is structured such that the agent must rely on its internal memory to accumulate and integrate useful information over time. This is achieved by forcing the agent to prune its context after each turn, thereby preventing it from accessing the full historical record. As a result, the agent learns to perform effective memory consolidation as a necessary component of its reasoning strategy. The RL framework is illustrated in the overall system diagram, which shows the interaction between the agent's internal state, the environment, and the reward assignment mechanism. 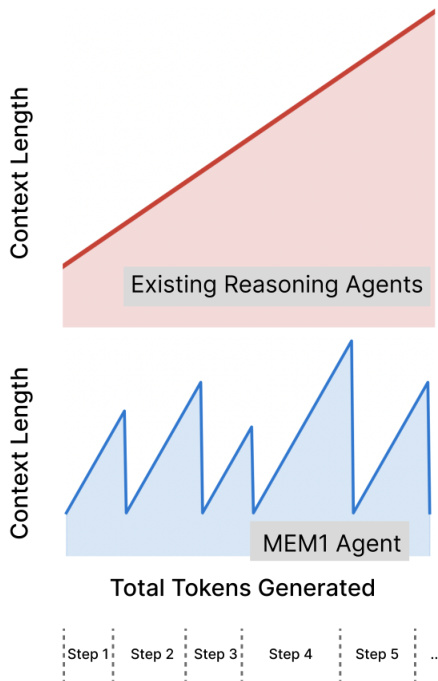
To address the challenges posed by the dynamic context updates during policy optimization, the authors introduce a masked trajectory approach. This method reconstructs a logically coherent full trajectory by stitching together multiple interaction turns, where each turn is represented as a tuple (ISt,queryt,infot) for t∈[1,T−1], with the final turn outputting the answer. This unified trajectory allows for standard policy optimization algorithms to be applied, despite the non-linear nature of the agent's context evolution. A key component of this approach is the use of a two-dimensional attention mask during the objective computation stage. This mask restricts each token's attention to only the tokens that were present in the memory at the time the token was generated, ensuring that the policy gradients are computed correctly under the memory-constrained regime. The attention mask is applied during the forward pass to compute action log-probabilities for the actor model and state value estimates for the critic model. During the policy update stage, an additional one-dimensional attention mask is applied to the full trajectory to ensure that gradient updates are localized to only the tokens generated by the model itself. 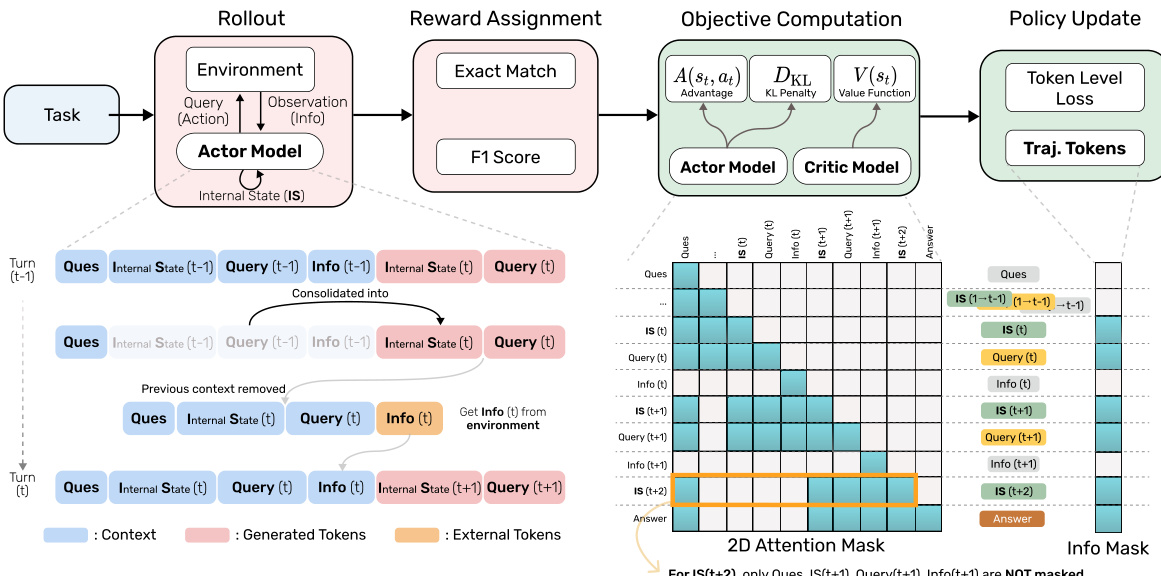
The rollout process of MEM1 is detailed in Algorithm 1, which outlines the step-by-step execution of the agent. The algorithm begins with an initial task prompt and proceeds through a series of turns, each involving the generation of a response token sequence. The agent generates tokens until it produces either a query or an answer. If a query is detected, the agent extracts the search query, retrieves feedback from the environment, and appends the information to the context. The process continues until the maximum number of turns is reached or the agent produces a final answer. The algorithm ensures that the context is reset after each turn, maintaining the constant memory property. 
Experiment
- MEM1 is trained via reinforcement learning on 2-objective QA tasks and demonstrates superior performance and efficiency on multi-objective multi-hop QA and WebShop navigation tasks, outperforming 7B baselines and even surpassing Qwen2.5-14B-Instruct in high-objective settings.
- On 16-objective QA tasks, MEM1 achieves 27.1% of the peak token usage and 29.3% of the inference time of Qwen2.5-14B-Instruct, while maintaining high accuracy (EM and F1 scores).
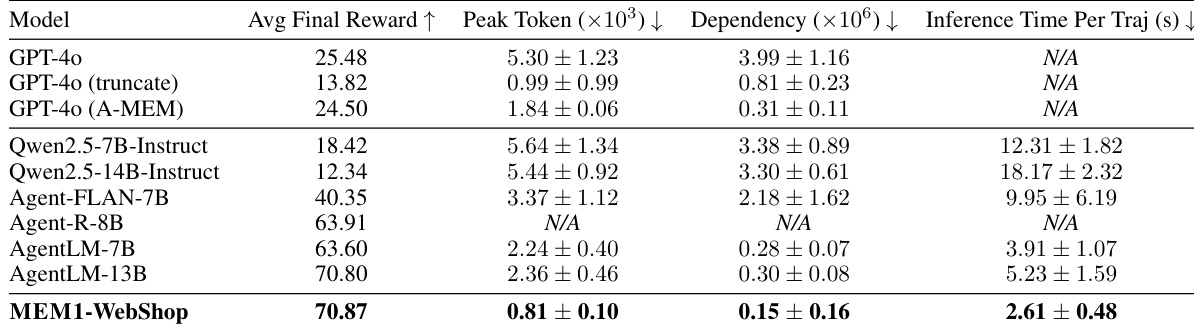
- In WebShop navigation, MEM1 outperforms Agent-Flan, Agent-R, and AgentLM, achieving 2.8× better peak token usage, 1.9× faster dependency length, and 1.5× faster inference time than the best baseline, even surpassing AgentLM-13B.
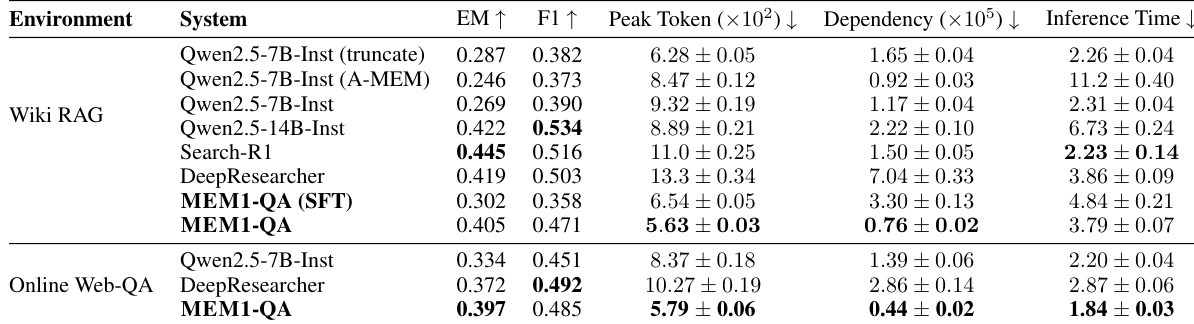
- On single-objective Wikipedia QA, MEM1 achieves the highest EM score and comparable F1 to Qwen2.5-14B-Instruct, with significantly lower peak token usage, dependency length, and inference time.
- MEM1 shows strong zero-shot transfer to online web-QA, maintaining high efficiency and competitive accuracy without retraining.
- Emergent behaviors include concurrent multi-question management, dynamic focus shifting, memory consolidation, query refinement, self-verification, and subgoal decomposition, enabling efficient long-horizon interaction.
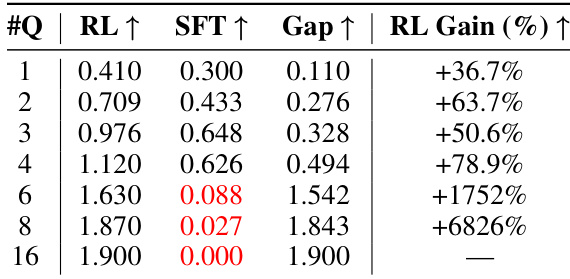
- RL training consistently outperforms SFT, with SFT collapsing on tasks with more than six objectives, while RL-trained MEM1 maintains robustness and scalability.
- Adding format rewards accelerates convergence but degrades final performance, indicating that outcome-based rewards better support effective reasoning and memory utilization.
The authors use a comprehensive set of metrics to evaluate MEM1 against various baselines, including GPT-4o and other agent models, across multi-turn tasks. Results show that MEM1 achieves the highest average final reward while maintaining significantly lower peak token usage, dependency, and inference time compared to all other models, demonstrating superior efficiency and performance.
Results show that MEM1-QA achieves higher exact match and F1 scores than all other models across 2-, 8-, and 16-objective tasks, while maintaining significantly lower peak token usage and inference time. The model demonstrates superior scalability, with its memory usage remaining nearly constant as the number of objectives increases, outperforming larger models like Qwen2.5-14B-Instruct in both efficiency and performance on long-horizon tasks.

Results show that MEM1-QA achieves competitive accuracy on both Wiki RAG and Online Web-QA tasks, with EM and F1 scores comparable to or exceeding those of larger models like Qwen2.5-14B-Instruct, while significantly reducing peak token usage, dependency length, and inference time. The model demonstrates strong efficiency gains, particularly in memory management, maintaining a near-constant peak token count even as task complexity increases.
Results show that the RL-trained MEM1 agent outperforms the SFT-trained model across all multi-turn tasks, with the performance gap widening as the number of questions increases. The SFT model collapses on tasks with more than six questions, while the RL model maintains strong performance, achieving a 1752% gain over SFT on the six-question task and a 6826% gain on the 16-question task.