Command Palette
Search for a command to run...
Fast Text-to-Audio Generation with Adversarial Post-Training
Fast Text-to-Audio Generation with Adversarial Post-Training
Abstract
Text-to-audio systems, while increasingly performant, are slow at inference time, thus making their latency unpractical for many creative applications. We present Adversarial Relativistic-Contrastive (ARC) post-training, the first adversarial acceleration algorithm for diffusion/flow models not based on distillation. While past adversarial post-training methods have struggled to compare against their expensive distillation counterparts, ARC post-training is a simple procedure that (1) extends a recent relativistic adversarial formulation to diffusion/flow post-training and (2) combines it with a novel contrastive discriminator objective to encourage better prompt adherence. We pair ARC post-training with a number optimizations to Stable Audio Open and build a model capable of generating approx12s of 44.1kHz stereo audio in approx75ms on an H100, and approx7s on a mobile edge-device, the fastest text-to-audio model to our knowledge.
One-sentence Summary
The authors, from UC San Diego, Stability AI, and Arm, propose ARC (Adversarial Relativistic-Contrastive) post-training—a novel distillation-free acceleration method for text-to-audio diffusion/flow models that combines a relativistic adversarial loss with a contrastive discriminator to enhance prompt adherence and realism, enabling 12-second 44.1kHz stereo audio generation in 75ms on an H100 and 7 seconds on mobile edge devices, significantly advancing real-time creative applications.
Key Contributions
- Text-to-audio generation remains slow due to the iterative sampling nature of diffusion and flow models, limiting real-time creative applications despite recent advances in model quality.
- The authors introduce Adversarial Relativistic-Contrastive (ARC) post-training, a novel distillation-free method that combines a relativistic adversarial loss with a contrastive discriminator objective to improve audio realism and prompt adherence during accelerated inference.
- ARC enables generation of approximately 12 seconds of 44.1kHz stereo audio in just 75ms on an H100 GPU and under 7 seconds on mobile edge devices, outperforming prior methods in speed and diversity while being the first fully adversarial, non-distillation approach for audio flow models.
Introduction
Text-to-audio generation has made significant strides in quality, but inference latency remains a major bottleneck—current models often require seconds to minutes per generation, limiting real-time creative applications. Prior acceleration methods rely heavily on distillation, which demands substantial computational resources for training and storage, and often inherits the drawbacks of Classifier-Free Guidance, such as reduced diversity and over-saturation. Some post-training approaches avoid distillation by using adversarial losses, but these have seen limited success in audio due to weak prompt adherence and lack of effective training recipes. The authors introduce Adversarial Relativistic-Contrastive (ARC) post-training, a novel framework that extends relativistic adversarial training to text-conditioned audio and introduces a contrastive discriminator objective to enforce prompt fidelity. This approach enables fast, high-quality audio generation without distillation or CFG, achieving 12 seconds of 44.1kHz stereo audio in just 75ms on an H100 GPU—100x faster than the original model—and enabling on-device inference in ~7 seconds on mobile CPUs, making it the fastest text-to-audio system to date.
Method
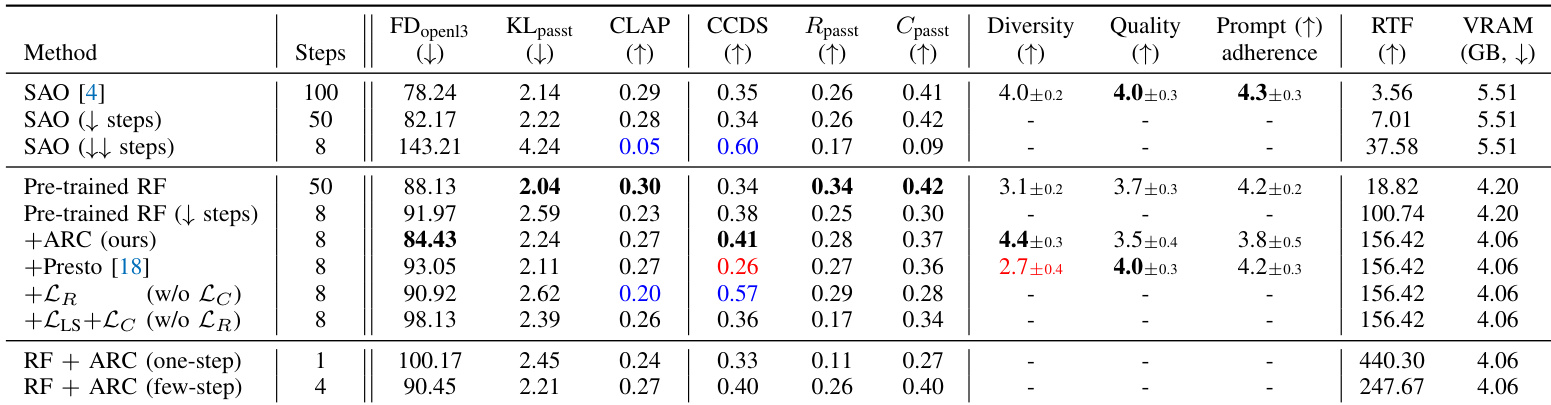
The authors leverage a two-stage framework for text-to-audio generation, beginning with a pre-trained rectified flow model and proceeding to adversarial post-training to accelerate sampling while preserving quality and prompt adherence. The overall architecture is built upon a latent diffusion model that operates in a compressed audio space. The base model consists of a 156M parameter autoencoder from SAO, which compresses stereo audio waveforms into a 64-channel latent representation at a 21.5Hz resolution. This latent space is conditioned on text prompts encoded by a 109M parameter T5 text embedder. The core generative component is a Diffusion Transformer (DiT), initially pre-trained as a rectified flow model to predict the velocity of the flow vθ(xt,t,c), which is used to reverse the forward noising process defined by xt=(1−t)x0+tϵ.
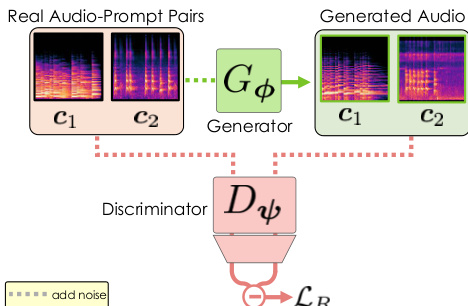
As shown in the figure below, the post-training stage transforms the pre-trained velocity predictor vθ into a few-step generator Gϕ by reparameterizing the model to directly output clean audio x^0 from a noisy input xt. This is achieved through adversarial post-training, where the generator Gϕ and a discriminator Dψ are jointly optimized. The discriminator is initialized from the pre-trained DiT, using its input embedding layers and 75% of its blocks, and is augmented with a lightweight 1D convolutional head. The training process involves corrupting real audio x0 with noise to obtain xt, which is then passed to the generator to produce a denoised sample x^0. Both the real and generated samples are subsequently re-noised to a lower noise level s to form the inputs for the discriminator. The generator is trained to minimize a relativistic adversarial loss LR, which compares the discriminator's output on a generated sample to its output on a paired real sample, encouraging the generator to produce outputs that are "more real" than their real counterparts. This loss is defined as LR(ϕ,ψ)=E[f(Δgen−Δreal)], where f(x)=−log(1+e−x), Δgen is the discriminator logit for the generated sample, and Δreal is the logit for the real sample.
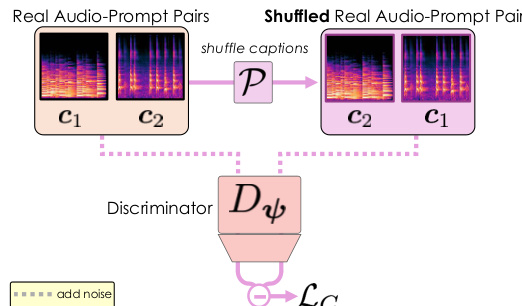
To address the issue of poor prompt adherence that can arise from the realism-focused adversarial loss, the authors introduce a contrastive loss LC for the discriminator. This loss is designed to improve the discriminator's ability to understand the alignment between audio and text prompts. It is applied by shuffling the text prompts within a batch, creating mismatched audio-text pairs, and training the discriminator to maximize the difference between the logits for correct pairs and incorrect pairs. The loss is formulated as LC(ψ)=E[f(Δreal(x0,s,P[c])−Δreal(x0,s,c))], where P[⋅] denotes a random permutation of the prompts. This contrastive objective encourages the discriminator to focus on semantic features rather than spurious correlations, thereby providing a stronger gradient signal for the generator to improve prompt adherence. The total post-training objective is the sum of the relativistic adversarial loss and the contrastive loss, LARC(ϕ,ψ)=LR(ϕ,ψ)+λ⋅LC(ψ).
After post-training, the model is used for inference with a specialized sampling strategy. The generator Gϕ is designed to directly estimate clean outputs from noisy inputs, which necessitates a change from the traditional ODE solvers used by rectified flows. Instead, the authors employ ping-pong sampling, which alternates between denoising a sample using Gϕ and re-noising it to a lower noise level. This iterative refinement process allows the model to produce high-fidelity audio in a small number of steps, significantly accelerating the generation process.
Experiment
- Evaluated accelerated text-to-audio models on AudioCaps test set (4,875 generations), validating performance across audio quality, semantic alignment, prompt adherence, and diversity using FDopen13, KLpasst, CLAP score, Rpasst, Cpasst, and proposed CCDS metric.
- Achieved 100x speedup over SAO (100-step) and 10x over pre-trained RF (50-step) with competitive metrics, while ARC post-training improved diversity without significant quality loss.
- ARC outperformed Presto in diversity (higher CCDS and MOS diversity) despite slightly lower quality, with Presto showing high quality but severe diversity reduction.
- 8-step inference achieved best results, aligning with recent findings on step efficiency in accelerated models; ablations confirmed the importance of relativistic loss and joint LR and LC training.
- CCDS metric showed strong correlation with subjective diversity MOS, validating its effectiveness for conditional diversity assessment.
- On edge devices (Vivo X200 Pro), dynamic Int8 quantization reduced inference time from 15.3s to 6.6s and peak VRAM from 6.5GB to 3.6GB, enabling sub-200ms latency on consumer GPUs.
- Demonstrated practical creative applications including real-time sound design, style transfer, voice-to-audio control, and beat-aligned generation, highlighting responsiveness and versatility.
The authors use a rectified flow model trained with ARC post-training to achieve significant speed improvements while maintaining high audio quality and prompt adherence. Results show that their method achieves competitive performance with state-of-the-art models like SAO and Presto, but with substantially lower latency and higher diversity, particularly when using 8 steps, while also demonstrating effective edge-device optimization through quantization.