Command Palette
Search for a command to run...
OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
Wasi Uddin Ahmad Sean Narenthiran Somshubra Majumdar Aleksander Ficek Siddhartha Jain Jocelyn Huang Vahid Noroozi Boris Ginsburg
Abstract
Since the advent of reasoning-based large language models, many have found great success from distilling reasoning capabilities into student models. Such techniques have significantly bridged the gap between reasoning and standard LLMs on coding tasks. Despite this, much of the progress on distilling reasoning models remains locked behind proprietary datasets or lacks details on data curation, filtering and subsequent training. To address this, we construct a superior supervised fine-tuning (SFT) dataset that we use to achieve state-of-the-art coding capability results in models of various sizes. Our distilled models use only SFT to achieve 61.8% on LiveCodeBench and 24.6% on CodeContests, surpassing alternatives trained with reinforcement learning. We then perform analysis on the data sources used to construct our dataset, the impact of code execution filtering, and the importance of instruction/solution diversity. We observe that execution filtering negatively affected benchmark accuracy, leading us to prioritize instruction diversity over solution correctness. Finally, we also analyze the token efficiency and reasoning patterns utilized by these models. We will open-source these datasets and distilled models to the community.
One-sentence Summary
The authors from NVIDIA propose a new supervised fine-tuning dataset for coding, enabling distilled models to achieve state-of-the-art performance on Live-CodeBench (61.8%) and CodeContests (24.6%) without reinforcement learning, leveraging instruction diversity over solution correctness through execution filtering, with implications for efficient, transparent model training in code generation.
Key Contributions
-
The paper addresses the lack of transparent, open-access datasets for distilling reasoning capabilities into smaller language models, introducing OPENCODEREASONING—a large-scale synthetic dataset with 736,712 Python code samples across 28,904 competitive programming questions, enabling superior supervised fine-tuning (SFT) performance without reliance on proprietary data or reinforcement learning.
-
By training models exclusively with SFT on this dataset, the authors achieve state-of-the-art results on coding benchmarks, including 61.8% pass@1 on Live-CodeBench and 24.6% on CodeContests, outperforming both open-weight SFT-only models and several SFT+RL alternatives, demonstrating that high-quality SFT data can close the performance gap with more complex training regimes.
-
Ablation studies reveal that code execution filtering during data curation harms benchmark accuracy, leading the authors to prioritize instruction diversity over solution correctness, while also analyzing token efficiency and reasoning patterns, offering actionable insights for future dataset design and model distillation.
Introduction
The authors leverage synthetic data generation and supervised fine-tuning to advance the performance of smaller language models on competitive coding tasks, addressing the growing need for high-quality, scalable training data. Prior work has relied heavily on proprietary datasets or complex training pipelines involving reinforcement learning, which limits reproducibility and accessibility. While some open-weight models achieve strong results through SFT-only training, they typically lag behind SFT+RL models due to smaller or less diverse datasets. The authors introduce OpenCodeReasoning, a large-scale open dataset of 736,712 Python-based reasoning examples derived from 28,904 competitive programming problems, which enables SFT-only models to surpass prior open-weight and even some proprietary models. Their analysis reveals that instruction diversity is more critical than solution correctness, as code execution filtering can harm benchmark performance, and they demonstrate that scaling synthetic data effectively closes the gap with RL-trained models.
Dataset
- The OPENCODEREASONING dataset comprises 736,712 Python code solutions with reasoning traces, generated by DeepSeek-R1, covering 28,904 unique competitive programming questions.
- Data sources include TACO, APPS, CodeContests, and CodeForces via the OpenR1 project, with exact-match deduplication applied to eliminate overlaps, resulting in a diverse and non-redundant question set.
- A rigorous benchmark contamination check was performed using cosine similarity (threshold 0.7) and human-in-the-loop validation with Llama-3.3-70B-Instruct and Qwen2.5-32B-Instruct, confirming no semantic overlap with evaluation benchmarks.
- Solutions were generated using a reasoning-enabled LLM, followed by post-processing: reasoning traces are verified and extracted within and tags, and code blocks are isolated using
python orcpp delimiters. - Responses containing code within reasoning traces are filtered out to ensure clean separation between reasoning and code, a step that removed only a negligible number of samples.
- Syntactic correctness of code blocks is validated using Tree Sitter, ensuring only properly formatted code is retained.
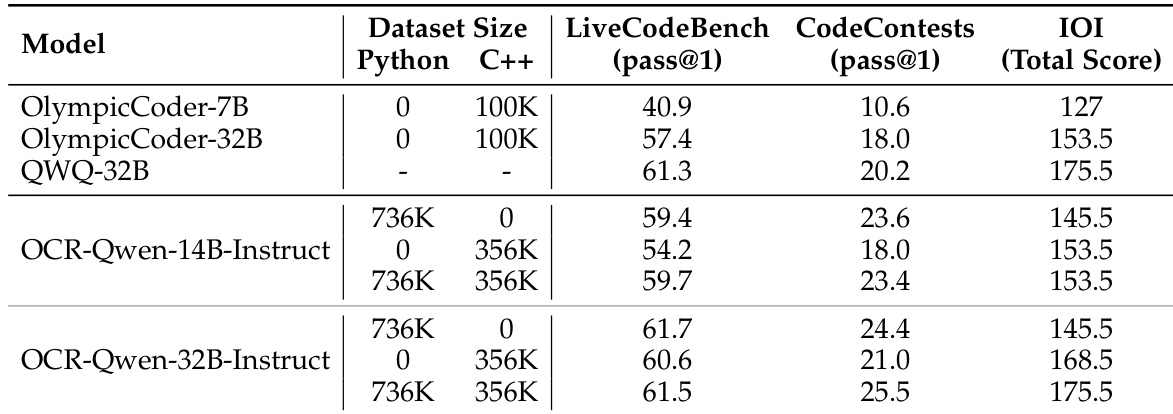
- The final dataset includes 736,712 Python samples and 355,792 C++ samples, with detailed token statistics available per source (Figure 2).
- The dataset is used to fine-tune Qwen2.5 models (7B, 14B, 32B) with a mixture of solutions from different sources, leveraging the full scale of 736,712 samples to achieve state-of-the-art performance on LiveCodeBench and CodeContests.
- Training employs a balanced mixture of reasoning and code, with no code embedded in reasoning sections, and processing ensures consistent formatting and high-quality, executable code.
Method
The authors leverage the DeepSeek-R1 model to generate multiple solutions for each problem, primarily in Python, with additional C++ solutions for preliminary experiments on the IOI benchmark. The generation process employs Nucleus Sampling with a temperature of 0.6 and top-p of 0.95, ensuring diverse yet focused outputs. To enforce structured reasoning, the model is explicitly prompted to include reasoning traces by injecting a specific tag during inference. This approach is implemented using SGLang, which supports efficient inference with a maximum output sequence length of 16k tokens.

As shown in the figure below, the initial segmentation prompt presents a chain of thought for solving a problem and instructs the model to identify and segment the reasoning into distinct patterns such as problem rephrasing, new idea generation, self-evaluation, verification, backtracking, and subgoal generation. The output format requires the model to label each segment with a pattern name and associate the corresponding text content.

The final segmentation prompt refines the task by focusing on unannotated segments within a chain of thought, delimited by <unannotated> and </unannotated> tags. The model is tasked with identifying the reasoning pattern used in each segment and producing a structured output that includes the content, reasoning for the pattern assignment, and the pattern name. This two-stage prompting strategy enables the model to systematically decompose and label complex reasoning processes.
Experiment
- Scaling up data in stages from 25k to 736k samples demonstrates a strong positive correlation between data volume and performance on coding benchmarks, with the largest gains observed when incorporating hard difficulty problems from CodeContests.
- On LiveCodeBench and CodeContests, OCR-Qwen-32B-Instruct achieved 61.8 and 24.6 pass@1, respectively, surpassing QwQ-32B and approaching DeepSeek-R1’s performance (65.6 and 26.2), highlighting the effectiveness of large-scale data and distillation.
- Ablation study shows that fine-tuning on incorrect code solutions (which are often from harder problems) yields higher accuracy than using only correct solutions, indicating that challenging, error-prone samples contribute valuable reasoning signals.
- Including C++ solutions in training improves performance on the C++-specific IOI benchmark but does not benefit Python-focused benchmarks, suggesting language-specific data is necessary for optimal results.
- Analysis reveals that OCR-32B models generate reasoning traces 20–30% shorter than QwQ-32B while achieving comparable accuracy, and that longer reasoning does not improve performance on hard problems—often leading to reasoning loops or degraded accuracy.
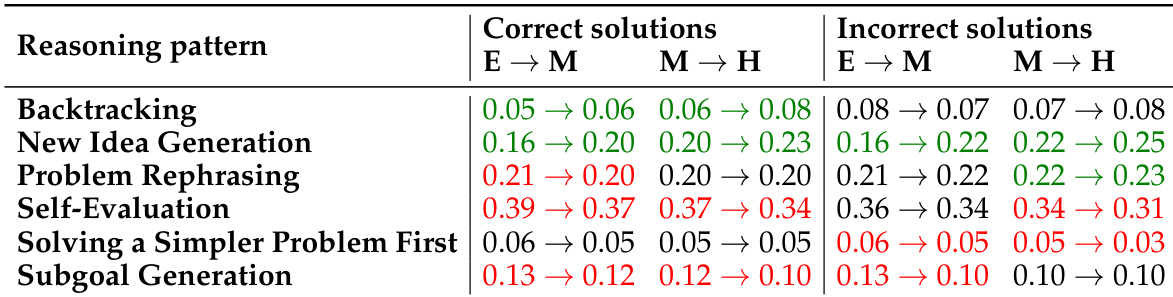
- Correct solutions exhibit higher self-evaluation and subgoal generation, and greater reasoning pattern diversity, which are statistically linked to improved correctness, indicating these strategies are critical for effective problem solving.
Results show that as problem difficulty increases from easy to medium to hard, correct solutions exhibit a significant increase in backtracking and self-evaluation patterns, while incorrect solutions maintain high levels of backtracking across all difficulty levels. The data also indicates that self-evaluation and subgoal generation are more prevalent in correct solutions, suggesting these patterns contribute to solution accuracy.
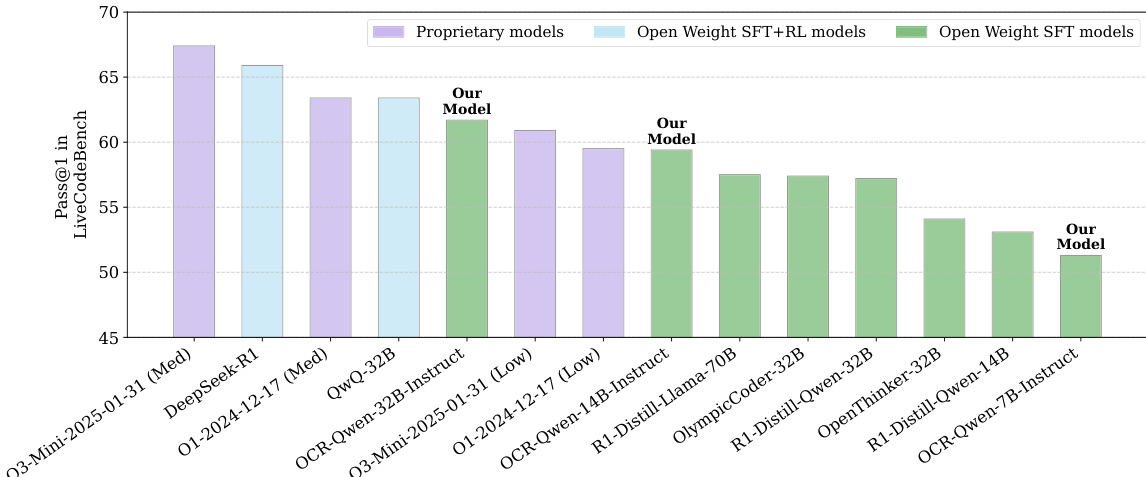
The authors use the OpenCodeReasoning dataset to fine-tune Qwen2.5 models, achieving state-of-the-art performance on LiveCodeBench. Results show that their OCR-Qwen-32B-Instruct model outperforms all open-weight models, including QwQ-32B and OlympicCoder-32B, and comes within a small margin of the proprietary DeepSeek-R1 model.
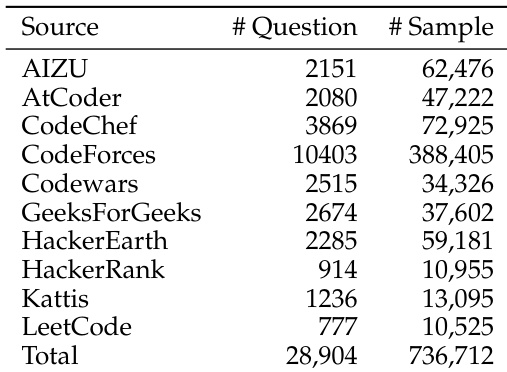
The authors use the OpenCodeReasoning dataset, which aggregates data from multiple sources including CodeForces, CodeChef, and LeetCode, to train and evaluate code generation models. Results show that the dataset contains 736,712 samples across 28,904 unique questions, with CodeForces contributing the largest number of samples and questions.
Results show that fine-tuning on incorrect solutions yields higher performance on both LiveCodeBench and CodeContests compared to using only correct solutions, despite the incorrect solutions being generated from more challenging problems. This suggests that even erroneous outputs from large models can contribute positively to distillation, likely due to their association with harder problems that require more complex reasoning.

The authors evaluate the impact of including C++ solutions in the training dataset by fine-tuning Qwen-2.5-14B-Instruct and Qwen-2.5-32B-Instruct models on a combined dataset of Python and C++ samples. Results show that while the inclusion of C++ data does not improve performance on Python benchmarks, it significantly enhances accuracy on the C++-specific IOI benchmark, indicating that multilingual data can boost performance in target languages.