Command Palette
Search for a command to run...
Task Tokens: A Flexible Approach to Adapting Behavior Foundation Models
Task Tokens: A Flexible Approach to Adapting Behavior Foundation Models
Ron Vainshtein Zohar Rimon Shie Mannor Chen Tessler
Abstract
Recent advancements in imitation learning for robotic control have led to transformer-based behavior foundation models (BFMs) that enable multi-modal, human-like control for humanoid agents. These models generate solutions when conditioned on high-level goals or prompts, for example, walking to a coordinate when conditioned on the position of the robot's pelvis. While excelling at zero-shot generation of robust behaviors, BFMs often require meticulous prompt engineering for specific tasks, potentially yielding suboptimal results. In this work, we introduce "Task Tokens" - a method to effectively tailor BFMs to specific tasks while preserving their flexibility. Our approach integrates naturally within the transformer architecture of BFMs. Task Tokens trains a task-specific encoder (tokenizer), with the original BFM remaining untouched. Our method reduces trainable parameters per task by up to ×125 and converges up to ×6 faster compared to standard baselines. In addition, by keeping the original BFM unchanged, Task Tokens enables utilizing the pre-existing encoders. This allows incorporating user-defined priors, balancing reward design and prompt engineering. We demonstrate Task Tokens' efficacy across various tasks, including out-of-distribution scenarios, and show their compatibility with other prompting modalities.
One-sentence Summary
By training a task-specific encoder while keeping the original transformer architecture frozen, the proposed Task Tokens method adapts behavior foundation models to specific robotic control tasks with up to 125 times fewer trainable parameters and 6 times faster convergence than standard baselines.
Key Contributions
- The paper introduces Task Tokens, a method designed to adapt Behavior Foundation Models (BFMs) to specific tasks by training a task-specific encoder while keeping the original BFM parameters frozen.
- This approach integrates directly into the existing transformer architecture, allowing for the use of pre-existing encoders and the incorporation of user-defined priors to balance reward design with prompt engineering.
- Experimental results demonstrate that Task Tokens reduce trainable parameters per task by up to 125 times and achieve convergence up to 6 times faster than standard baselines across various tasks and out-of-distribution scenarios.
Introduction
Goal Conditioned Behavior Foundation Models (GC-BFMs) are essential for generating diverse, human-like motions in robotics and animation by mapping goals directly to actions. While these models excel at reproducing common motions, they struggle to adapt to out-of-distribution constraints or specialized tasks defined by users. Existing solutions like prompt engineering or fine-tuning are often inefficient or risk degrading the foundational knowledge stored within the model. The authors leverage a Task Tokens approach to bridge this gap, providing a mechanism that incorporates task-specific optimization while preserving the natural behavior of the underlying foundation model.
Method
The authors propose a parameter-efficient method called Task Tokens to adapt a Goal-Conditioned Behavior Foundation Model (GC-BFM), specifically MaskedMimic, to specific downstream tasks without fine-tuning the underlying foundation model. This approach preserves the zero-shot capabilities and general behavioral priors of the BFM while enabling task-specific optimization.
The core architecture relies on the transformer-based nature of MaskedMimic, which processes sequences of tokens. The method integrates three distinct input sources to guide the model. As shown in the framework diagram:

These sources include Prior Tokens, which allow for user-defined behavioral priors such as textual prompts or joint conditions; State Tokens, which represent the current environment state sti using pre-trained encoders; and Task Tokens, which are generated by a dedicated Task Encoder. The frozen GC-BFM integrates these inputs to produce task-optimized actions ati.
The Task Encoder is designed as a lightweight, generic module implemented as a feed-forward multilayer perceptron (MLP) with ReLU activations. It processes task-goal observations gti—which are represented in the agent's egocentric reference frame—and predicts a Task Token τti∈R512. For example, in a steering task, the input gti might include target direction, facing direction, and desired speed. To ensure alignment with the pre-trained representations of MaskedMimic, the encoder is also provided with proprioceptive information. The resulting Task Token is concatenated with other tokens in the BFM's input space, creating a token "sentence" where the task-specific signal acts as a specialized word guiding the model toward the target behavior.
To optimize the Task Encoder, the authors utilize Proximal Policy Optimization (PPO). During the training process, the BFM predicts action probabilities based on the combined token sequence. The PPO objective is computed with respect to the task-specific reward and the BFM's action probabilities. Crucially, the gradients flow through the frozen GC-BFM to update only the Task Encoder parameters. This design prevents the degradation of the foundation model's prior knowledge, which might otherwise occur through full fine-tuning.
For complex tasks that require sequential execution, the authors implement multi-phase prompting. This mechanism uses a finite-state machine (FSM) to switch between different prior tokens while using a single Task Token. As shown in the figure below, this allows the agent to transition between distinct behavioral phases, such as moving from a locomotion phase to a striking phase, based on geometric proximity to a target:
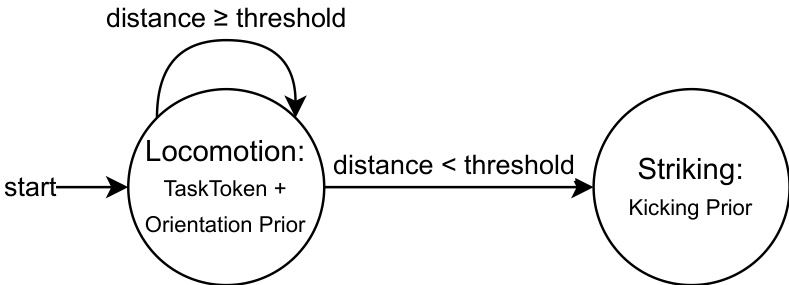
Experiment
The researchers evaluated the Task Tokens method across diverse humanoid control tasks, including reaching, steering, and striking, to assess its ability to adapt behavior foundation models to specific objectives. The experiments validate that this hybrid approach achieves rapid convergence and high success rates while maintaining the robustness and multi-modal prompting capabilities of the original model. Qualitative results from human studies and out-of-distribution tests confirm that the method produces natural, human-like motions that generalize well to varying environmental conditions such as changes in gravity and friction.
The authors compare the success rates of various humanoid control methods across five distinct tasks. Results show that Task Tokens achieves high performance across most environments, demonstrating strong competitive capabilities compared to established baselines. Task Tokens maintains high success rates in Direction, Steering, and Reach tasks. The method performs comparably to advanced baselines like PPO and AMP in several task categories. While some baselines show higher success in the Strike and Long Jump tasks, Task Tokens remains effective in the majority of evaluated scenarios.
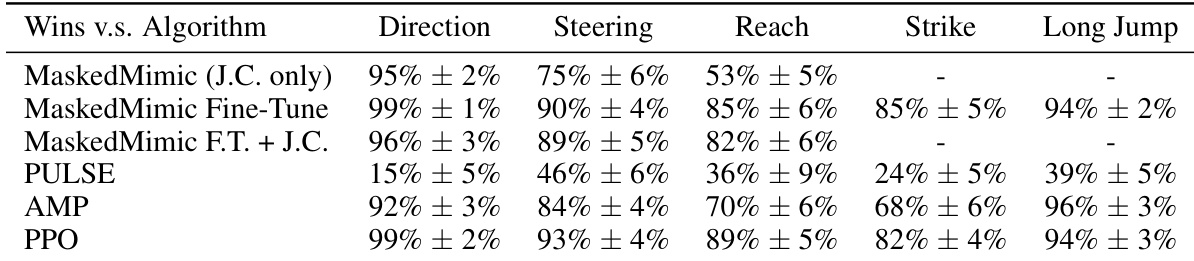
The authors evaluate the performance of Task Tokens across several humanoid control tasks by comparing success rates with various baselines. The results demonstrate that Task Tokens achieves high success rates across most environments, effectively adapting the foundation model to new tasks. Task Tokens performs competitively with or outperforms fine-tuning methods in most evaluated tasks. The method shows significant improvements in success rates for tasks like Reach and Steering compared to the original zero-shot MaskedMimic approach. While fine-tuning achieves high success in the Strike task, Task Tokens maintains strong performance across the majority of other scenarios.

The authors compare the Task Tokens approach against several baselines across five humanoid control tasks. Results show that Task Tokens achieves high success rates in most environments, demonstrating effective task adaptation while maintaining competitive performance against specialized methods. Task Tokens achieves superior success rates in the Reach, Direction, and Steering tasks compared to most baselines. The method performs highly effectively on the Long Jump task, matching the performance of state-of-the-art hierarchical approaches. While other methods like MaskedMimic Fine-Tune and PULSE show strong results in the Strike task, Task Tokens remains highly competitive across the task suite.

The authors conduct an ablation study to evaluate how different Task Encoder architectures affect performance on the steering task. The results demonstrate that larger MLP encoders and the inclusion of current pose information generally contribute to higher success rates. Using a bigger MLP encoder tends to improve the success rate in steering tasks. Incorporating current pose information into the encoder leads to better performance when using a larger MLP. The combination of a larger MLP and current pose information yields the highest success rate among the tested configurations.
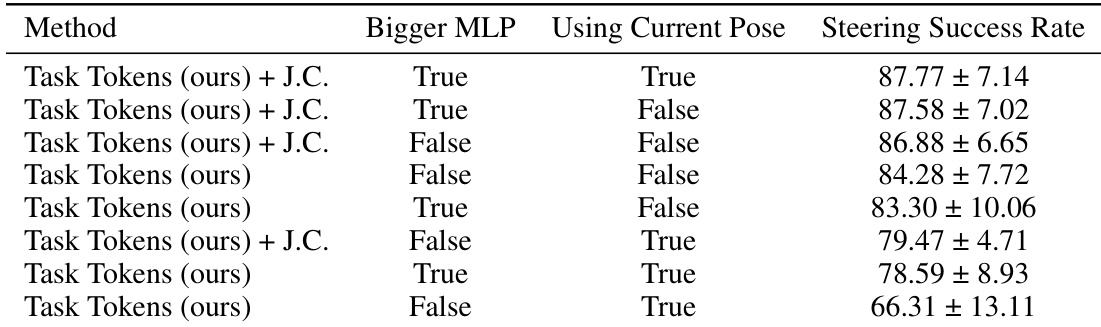
The authors evaluate the Task Tokens approach by comparing its success rates across five humanoid control tasks against several established baselines and conducting an ablation study on encoder architectures. The results demonstrate that Task Tokens provides effective task adaptation and achieves highly competitive performance, often outperforming or matching advanced fine-tuning and hierarchical methods in most scenarios. Furthermore, the ablation study indicates that performance is optimized by utilizing larger MLP encoders and incorporating current pose information.