Command Palette
Search for a command to run...
R1-Onevision: Advancing Generalized Multimodal Reasoning through
Cross-Modal Formalization
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Abstract
Large Language Models have demonstrated remarkable reasoning capability in complex textual tasks. However, multimodal reasoning, which requires integrating visual and textual information, remains a significant challenge. Existing visual-language models often struggle to effectively analyze and reason visual content, resulting in suboptimal performance on complex reasoning tasks. Moreover, the absence of comprehensive benchmarks hinders the accurate assessment of multimodal reasoning capabilities. In this paper, we introduce R1-Onevision, a multimodal reasoning model designed to bridge the gap between visual perception and deep reasoning. To achieve this, we propose a cross-modal reasoning pipeline that transforms images into formal textural representations, enabling precise language-based reasoning. Leveraging this pipeline, we construct the R1-Onevision dataset which provides detailed, step-by-step multimodal reasoning annotations across diverse domains. We further develop the R1-Onevision model through supervised fine-tuning and reinforcement learning to cultivate advanced reasoning and robust generalization abilities. To comprehensively evaluate multimodal reasoning performance across different grades, we introduce R1-Onevision-Bench, a benchmark aligned with human educational stages, covering exams from junior high school to university and beyond. Experimental results show that R1-Onevision achieves state-of-the-art performance, outperforming models such as GPT-4o and Qwen2.5-VL on multiple challenging multimodal reasoning benchmarks.
One-sentence Summary
The authors from Zhejiang University, WeChat Vision (Tencent Inc.), and Renmin University of China propose R1-Onevision, a multimodal reasoning model that transforms images into formal textual representations for precise language-based reasoning, outperforming GPT-4o and Qwen2.5-VL on complex tasks through a cross-modal pipeline and a new benchmark aligned with human educational stages.
Key Contributions
- Existing visual-language models struggle with multimodal reasoning due to poor integration of visual perception and deep textual reasoning, often failing to handle complex, structured visual tasks like diagram-based problem solving.
- The authors introduce a cross-modal reasoning pipeline that converts images into formal textual representations, enabling precise, step-by-step reasoning, and construct the R1-Onevision dataset with detailed, annotated reasoning traces across diverse domains.
- R1-Onevision achieves state-of-the-art performance on multimodal reasoning benchmarks, outperforming models like GPT-4o and Qwen2.5-VL, and is evaluated using R1-Onevision-Bench, a new benchmark aligned with human educational levels from junior high to university.
Introduction
The authors address the challenge of multimodal reasoning in large language models, where integrating visual perception with deep, structured reasoning remains difficult. Prior models either rely on rigid, predefined reasoning templates that limit flexibility or imitate ground-truth answers without genuine reasoning, leading to poor generalization and failure on complex visual tasks. Additionally, existing benchmarks are narrow in scope, focusing on specific domains like math and lacking alignment with real-world educational progression. To overcome these limitations, the authors introduce R1-Onevision, a multimodal reasoning model built around a cross-modal reasoning pipeline that converts images into formal textual representations, enabling precise, language-based reasoning. They construct the R1-Onevision dataset with detailed, step-by-step reasoning annotations across diverse domains and develop the model through supervised fine-tuning and rule-based reinforcement learning to enhance both reasoning quality and generalization. Furthermore, they introduce R1-Onevision-Bench, a comprehensive benchmark aligned with human educational stages, enabling evaluation of reasoning performance across subjects and difficulty levels. The approach achieves state-of-the-art results on multiple benchmarks, outperforming models like GPT-4o and Qwen2.5-VL.
Dataset
- The dataset, R1-Onevision, is used to enhance the reasoning capabilities of visual language models through supervised fine-tuning (SFT).
- It supports the development of a structured, consistent output format and fosters advanced reasoning in large-scale models, setting a strong foundation for subsequent reinforcement learning.
- The R1-Onevision-Bench benchmark, derived from this dataset, evaluates multimodal reasoning across five major domains: Math, Biology, Chemistry, Physics, and Deduction.
- The benchmark includes 38 subcategories and is organized into five difficulty levels: Junior High School, High School, University, and Social Test, reflecting a progression in cognitive complexity.
- Data spans real-world reasoning tasks from middle school to university levels, incorporating diverse problem types requiring deep thinking and multimodal understanding.
- The benchmark is designed to mirror human educational development, enabling evaluation of model performance across academic and practical reasoning domains.
- Tasks are carefully curated with examples provided across categories and grade levels, ensuring comprehensive coverage of reasoning challenges.
- The dataset is used in training with a mixture of SFT data, where the model is fine-tuned on curated, high-quality multimodal questions and answers.
- No explicit cropping strategy is mentioned, but the data includes image-text pairs designed to support complex reasoning.
- Metadata is constructed around domain, subcategory, difficulty level, and educational grade to enable granular evaluation and analysis.
Method
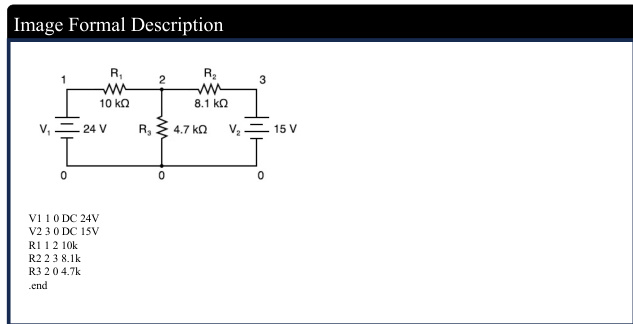
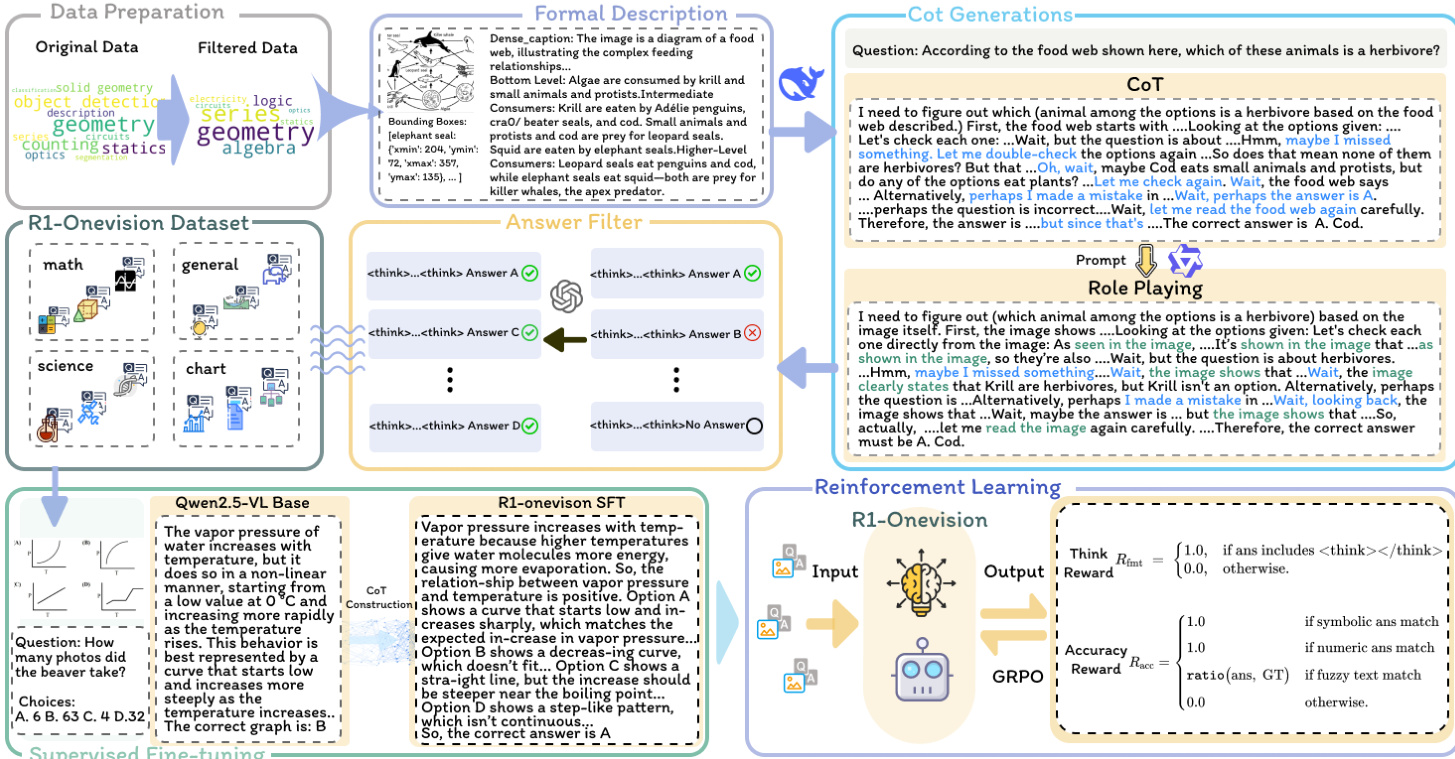
The authors leverage a comprehensive cross-modal reasoning pipeline to bridge the gap between language reasoning models and vision models by integrating visual formal representations. This pipeline is designed to enable language models to reason over image elements by providing structured, formal descriptions of visual content. The framework begins with data curation and filtering, where diverse multimodal datasets—covering natural images, OCR-based text extraction, charts, mathematical expressions, and scientific reasoning problems—are aggregated, with only those supporting structured reasoning retained. The curated data is then processed to generate formal descriptions of visual content using a combination of GPT-4o, Grounding DINO, and EasyOCR. For charts and diagrams, GPT-4o generates structured representations such as SPICE for circuit schematics, PlantUML or Mermaid.js for flowcharts, HTML for UI layouts, and CSV/JSON for tables. Natural scenes are enhanced with fine-grained spatial descriptions by using Grounding DINO to extract bounding box annotations and GPT-4o to generate descriptive captions. Text-only images are handled by employing EasyOCR to extract text with positional information, followed by GPT-4o to reconstruct the original document. For images containing both visual and textual content, the pipeline integrates GPT-4o-generated captions, Grounding DINO bounding boxes, and EasyOCR-extracted text to ensure comprehensive capture of both modalities. Mathematical images are processed by prompting GPT-4o to propose reasoning strategies to guide inference.

The pipeline proceeds to generate reasoning processes by prompting a language reasoning model, specifically DeepSeek R1, with the dense captions and questions derived from the formal descriptions. To address the limitation of traditional Chain-of-Thought (CoT) approaches, which lack direct visual comprehension, the authors introduce a role-playing strategy that emulates human-like visual understanding. This method involves iteratively revisiting the image, refining its understanding, and enhancing the fidelity of the reasoning process. The role-playing strategy ensures that the model's reasoning is grounded directly in the visual input rather than relying on textual descriptions. The generated reasoning processes are then subjected to quality assurance, where GPT-4o is used to remove inaccurate, irrelevant, or inconsistent CoT steps, ensuring a high-quality dataset for multimodal reasoning.
The resulting dataset, R1-Onevision, is a carefully crafted resource designed to push the boundaries of multimodal reasoning. It encompasses a wide range of domains, including science, mathematics, chart data, and general real-world scenarios, totaling over 155k carefully curated samples. The dataset serves as a rich resource for developing visual reasoning models.
The authors employ a two-stage post-training strategy to enhance multimodal reasoning capabilities. The first stage is Supervised Fine-Tuning (SFT), which stabilizes the model's reasoning process and standardizes its output format. The second stage is rule-based Reinforcement Learning (RL), which further improves generalization across diverse multimodal tasks. The RL stage is built upon the SFT-trained model and employs rule-based rewards to optimize structured reasoning and ensure output validity. Two reward rules are defined: Accuracy Reward and Format Reward. The Accuracy Reward evaluates the correctness of the final answer by extracting the final answer via regular expressions and verifying it against the ground truth. For deterministic tasks such as math problems, the final answer must be provided in a specified format (e.g., within a box) to enable reliable rule-based verification. In cases like object detection, the reward is determined by the Intersection over Union (IoU) score with the ground truth. The Format Reward ensures the existence of the reasoning process by requiring that the response must follow a strict format where the model's reasoning is enclosed between and markers, with a regular expression ensuring the presence and correct ordering of these markers.
To achieve balanced integration of consistent policy updates and robust reward signals, the authors employ Group Relative Policy Optimization (GRPO). For each token in the generated answer, GRPO computes the log probabilities under both the new policy (π(θ)) and a reference policy. It then calculates a ratio of these probabilities and clips it to the range [1−ϵ,1+ϵ] to prevent overly large updates. The normalized reward, serving as the advantage, is used in a PPO-style loss:
Lclip=−E[min(ratiot⋅Advt, clippedratiot⋅Advt)].Here, Advt denotes the advantage function, capturing how much better (or worse) a particular action is compared to a baseline policy value. To further maintain closeness to the reference distribution, a KL divergence penalty (weighted by β) is added, yielding the overall loss:
LGRPO(θ)=−E[min(ratiot⋅Advt,clippedratiot⋅Advt)−β⋅KL(πθ(y∣x),πref(y∣x))].This combination ensures that the model integrates rule-based rewards efficiently without compromising training stability.
Experiment
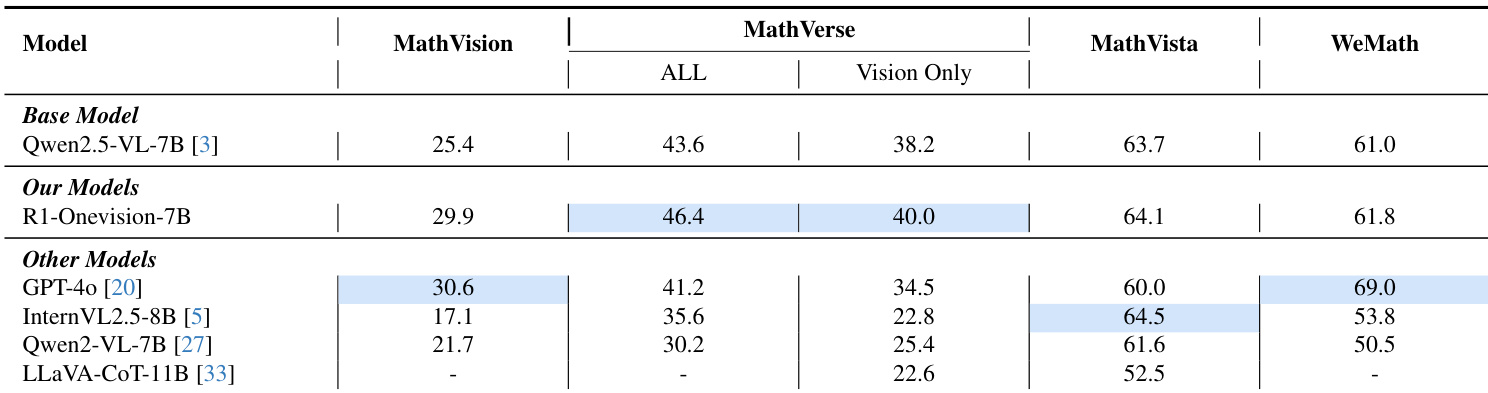
- Evaluated R1-Onevision on MathVista, MathVision, MathVerse, and WeMath benchmarks, demonstrating consistent superiority over state-of-the-art multimodal models, particularly in fine-grained visual-textual alignment and chain-of-thought reasoning.
- Achieved 29.9% accuracy on MathVision, comparable to GPT-4o, and surpassed GPT-4o by 5.2% (MathVerse ALL), 5.5% (MathVerse Vision Only), and 4.1% (MathVista), validating enhanced reasoning capabilities.
- On the R1-Onevision benchmark, Qwen2.5-VL-72B achieved 52% average accuracy, matching Claude-3.5 and ranking just behind Gemini-2.0-Flash, while R1-Onevision (3B) achieved 23.6% on MathVision and 38.6% on MathVerse (ALL), showing strong performance even on smaller models.
- SFT followed by RL significantly improved performance, with RL providing incremental gains, confirming the complementary role of both training strategies in enhancing deductive reasoning.
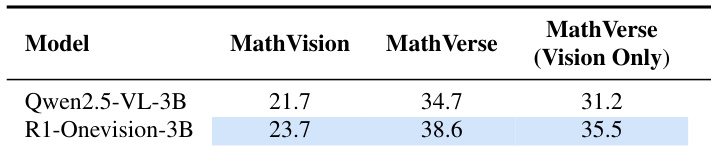
- Ablation studies confirmed the scalability of the method across model sizes, with R1-Onevision (3B) showing substantial improvements over the base model, indicating broad applicability.
The authors use the Qwen2.5-VL-3B model as a base to evaluate the effectiveness of their R1-Onevision approach. Results show that R1-Onevision-3B achieves higher accuracy than the base model across all three benchmarks, with improvements of 2.0, 3.9, and 4.3 percentage points on MathVision, MathVerse, and MathVerse (Vision Only), respectively.
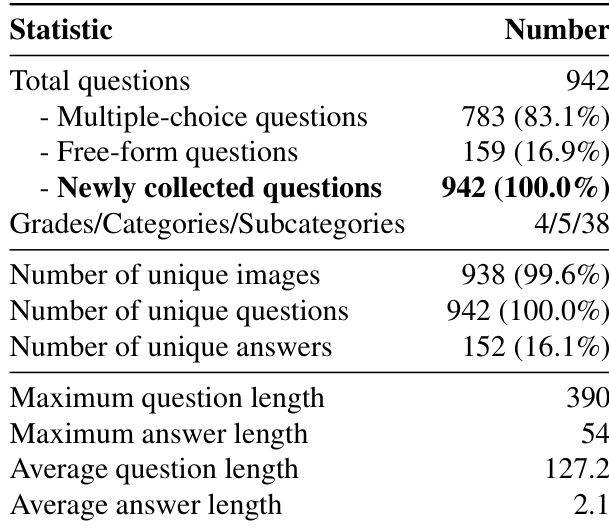
The authors present a comprehensive analysis of the R1-Onevision benchmark, which consists of 942 total questions, including 783 multiple-choice and 159 free-form questions, all newly collected. The benchmark is structured across four difficulty grades and five academic categories, with a focus on evaluating multimodal reasoning capabilities through a diverse set of unique images, questions, and answers.
The authors use a table of standard enthalpies of formation to calculate the standard enthalpy change for a chemical reaction, applying the formula ΔH° = ΣΔH°f(products) - ΣΔH°f(reactants). The model correctly identifies the relevant values, performs the calculation step-by-step, and arrives at the answer -205.4 kJ·mol⁻¹, which matches option A.

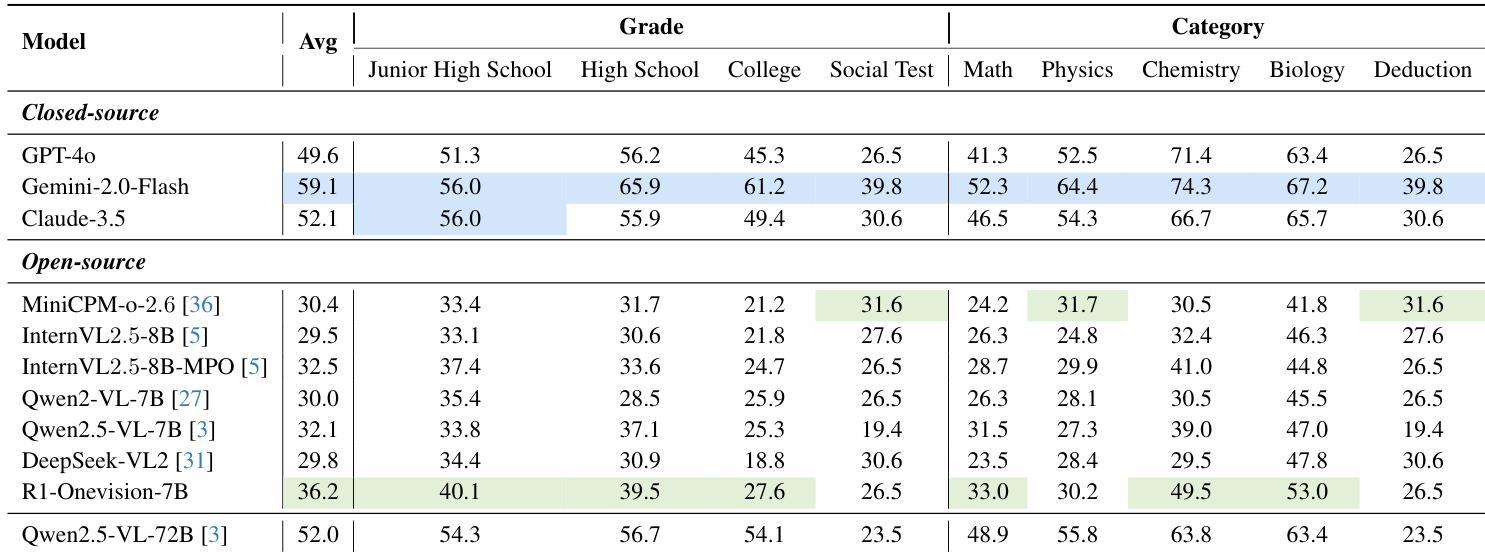
The authors use Table 3 to compare the performance of closed-source and open-source multimodal models on the R1-Onevision benchmark, which is categorized by difficulty level and academic discipline. Results show that closed-source models like Gemini-2.0-Flash achieve the highest average accuracy, surpassing 50%, while open-source models such as Qwen2.5-VL-72B reach 52% average accuracy, narrowing the gap with top closed-source models.
The authors use R1-Onevision-7B to evaluate its performance on multiple multimodal reasoning benchmarks, showing that it outperforms the base Qwen2.5-VL-7B model across all tasks. Results show that R1-Onevision-7B achieves 29.9% accuracy on MathVision, surpassing the base model's 25.4%, and reaches 46.4% on MathVerse (ALL) and 40.0% on MathVerse (Vision Only), demonstrating significant improvements in visual-textual alignment and reasoning.