Command Palette
Search for a command to run...
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy
Abstract
We introduce Long-VITA, a simple yet effective large multi-modal model for long-context visual-language understanding tasks. It is adept at concurrently processing and analyzing modalities of image, video, and text over 4K frames or 1M tokens while delivering advanced performances on short-context multi-modal tasks. We propose an effective multi-modal training schema that starts with large language models and proceeds through vision-language alignment, general knowledge learning, and two sequential stages of long-sequence fine-tuning. We further implement context-parallelism distributed inference and logit-masked language modeling head to scale Long-VITA to infinitely long inputs of images and texts during model inference. Regarding training data, Long-VITA is built on a mix of 17M samples from public datasets only and demonstrates state-of-the-art performance on various multi-modal benchmarks, compared against recent cutting-edge models with internal data. Long-VITA is fully open-source and reproducible. By leveraging our inference designs, Long-VITA models achieve a remarkable 2× prefill speedup and 4× context length extension in a single node with 8 GPUs. We hope Long-VITA can serve as a competitive baseline and offer valuable insights for the open source community to advance long-context multimodal understanding.
One-sentence Summary
Long-VITA is a large multi-modal model that processes up to 1 million tokens across images, video, and text by employing a multi-stage training schema and context-parallelism distributed inference to achieve state-of-the-art performance on various benchmarks while maintaining leading short-context accuracy and a 2x prefill speedup.
Key Contributions
- The paper introduces Long-VITA, a large multi-modal model capable of processing up to 4K video frames or 1M text tokens while maintaining high performance across both short-context image and long-context video understanding tasks.
- A multi-modal training schema is proposed that transitions from large language models through vision-language alignment and general knowledge learning to two sequential stages of long-sequence fine-tuning.
- The work implements context-parallelism distributed inference and a logit-masked language modeling head to scale to infinitely long inputs, achieving a 2x prefill speedup and 4x context length extension on a single node with 8 GPUs.
Introduction
Large multi-modal models are essential for processing complex, real-world data involving images, videos, and text. While proprietary models can handle massive inputs, existing open-source alternatives often struggle to balance short-context accuracy with long-context capabilities. Previous research typically focuses on long video understanding by compressing visual tokens, which often leads to performance degradation, or neglects the ability to process static images effectively. The authors leverage a phased training schema and context-parallelism distributed inference to introduce Long-VITA, an open-source model capable of scaling to 1 million tokens. This approach enables high-performance understanding across images, short videos, and long-form content without sacrificing short-context precision.
Dataset
The authors construct the Long-VITA training set using exclusively open-source data, organized into the following categories:
- Image-Text Data: This subset is divided into three functional groups:
- Image Captioning: Comprised of LLaVA-ReCap, ALLaVA-4V, ShareGPT4V, and LLaVA-OneVision-Mid.
- Visual Question Answering (VQA): Combines general VQA data from LVIS-Instruct4V, the-cauldron, Docmatix, and LLaVA-OneVision.
- Interleaved Image-Text: Includes M4-Instruct for multi-image capabilities and a newly created Comic-9k dataset. The Comic-9k dataset contains 200,000 images from 9,000 comic books paired with manually labeled synopses to enhance understanding of sequences exceeding 10 images.
- Video-Text Data: The authors utilize VideoGPT-plus, ShareGemini, and LLaVA-Video-178K for general video understanding. To support movie-level long-context capabilities, they constructed the MovieNet-Summary dataset using paired movies and synopses from MovieNet.
- Short Text Data: Pure text data is sourced from a variety of collections including OpenHermes-2.5, LIMA, databricks-dolly-15k, and several mathematical datasets such as MetaMathQA, MathInstruct, Orca-Math, atlas-math-sets, goat, and camel-ai-math.
- Long Text Data: To transfer long-context capabilities to the multimodal model, the authors gather data from Long-Instruction-with-Paraphrasing, LongForm, LongAlign-10k, LongCite-45k, LongWriter-6k, LongQLoRA, LongAlpaca, and Long-Data-Collections.
The authors note that while Comic-9k and MovieNet-Summary are original contributions of this work, the entire training pipeline relies on open data and does not employ data filtering methods.
Method
The Long-VITA architecture is designed to facilitate long-context vision understanding by avoiding token compression and sparse local attention. The authors construct this multi-modal framework around three primary components: a Vision Encoder, a Projector, and a Large Language Model (LLM).
For the backbone, the authors utilize Qwen2.5-14B-Instruct as the LLM. The visual component is built upon the InternViT-300M vision encoder. To handle high-resolution images with varying aspect ratios, the authors introduce a dynamic tiling vision encoding strategy. To bridge the gap between visual and linguistic modalities, a 2-layer MLP is employed as the vision-language projector to map image features into the word embedding space. Furthermore, a pixel shuffle operation is applied to the visual tokens, which reduces the total number of visual tokens to one-quarter.
The training process for Long-VITA is structured into four distinct stages, characterized by increasing sequence lengths to progressively scale the model's context window.
In Stage 1, the focus is on vision-language alignment. The goal is to establish initial connections between visual and language features. During this phase, the LLM and the vision encoder are frozen, and only the vision projector is trained. The authors primarily utilize caption data and incorporate Docmatix to enhance document-based visual question answering (VQA) capabilities.
Stage 2 transitions into the learning of general knowledge. Once alignment is established in the embedding space, the model undergoes extensive training using diverse image-text data for tasks such as image captioning, common VQA, OCR, and multi-modal conversations. The authors also integrate text-only general instructions, mathematical problems, and arithmetic calculations. For video understanding, VideoGPT-plus and ShareGemini-cap are included. To manage large datasets, the authors use a packing strategy where data items are concatenated into fixed sequence lengths of 32K for Stage 1 and 16K for Stage 2. During these first two stages, positional embeddings and attention masks are reset for each packed sample to ensure that each text-vision pair only attends to its own content.
The complexity increases in Stage 3, which focuses on long-sequence fine-tuning. The context length is extended to 128K. The authors reduce the sampling ratio of Stage 2 data to 0.1 and introduce additional long-context text instructions, comic book summaries, and video understanding datasets.
Finally, Stage 4 extends the long-sequence fine-tuning to a context length of 1,024K by adding movie summary data. Unlike the previous stages, the training data in Stage 3 and Stage 4 is packed into fixed sequence lengths without resetting the positional embeddings or the attention masks. This specific design choice forces the model to capture the correlations between the two modalities within extremely long-contextual information.
The composition of the datasets used throughout these various stages is detailed in the following table:
Experiment
The researchers evaluate Long-VITA's efficiency and performance through infrastructure testing and comprehensive benchmarks on image and video understanding. The experiments validate that the proposed logits-masked language modeling head significantly reduces memory consumption and increases sequence length capacity during inference. Results demonstrate that Long-VITA achieves state-of-the-art performance among open-source models under 20B parameters, showing exceptional capabilities in multi-image tasks and long-form video comprehension using only publicly available data.
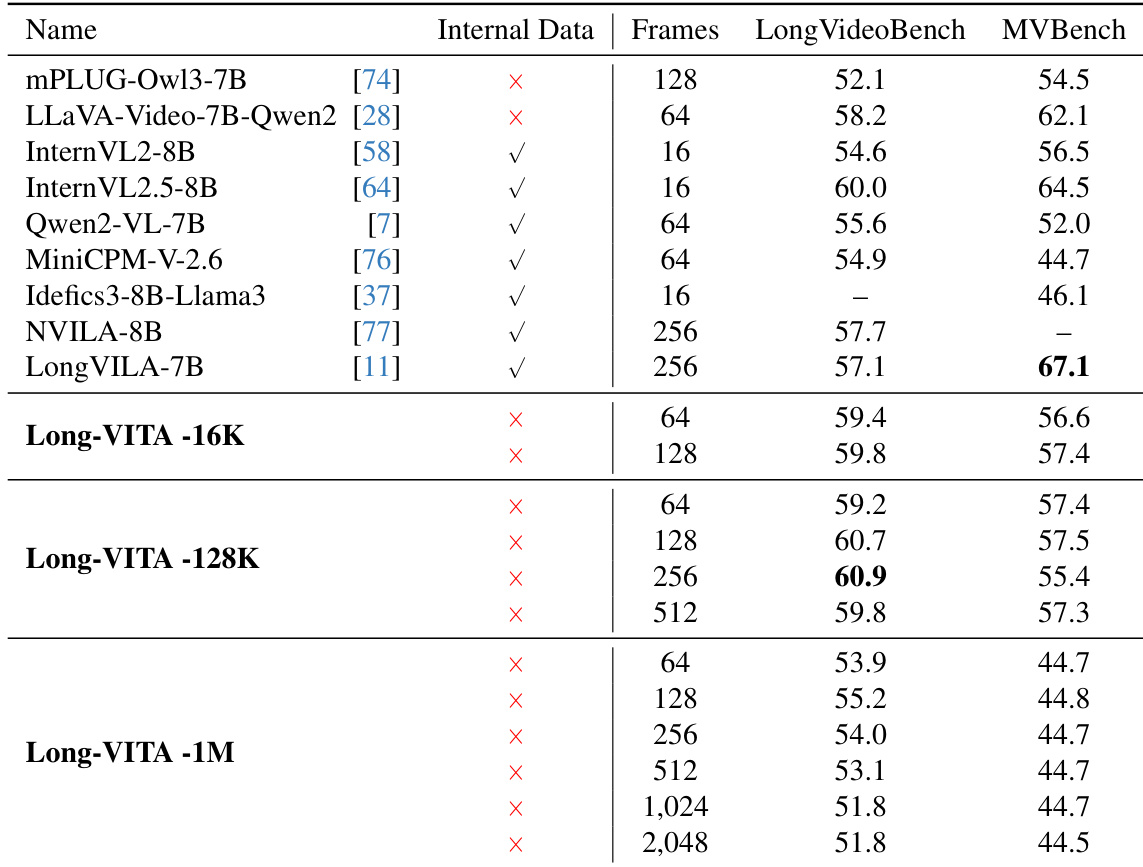
The authors evaluate the performance of Long-VITA models across different sequence lengths using LongVideoBench and MVBench. Results show that the model maintains strong video understanding capabilities across various frame counts and temporal lengths. Long-VITA-128K achieves leading performance on LongVideoBench, particularly at higher frame counts. The Long-VITA series demonstrates competitive results on MVBench across multiple frame configurations. Long-VITA-1M maintains consistent performance even when processing a significantly larger number of frames.
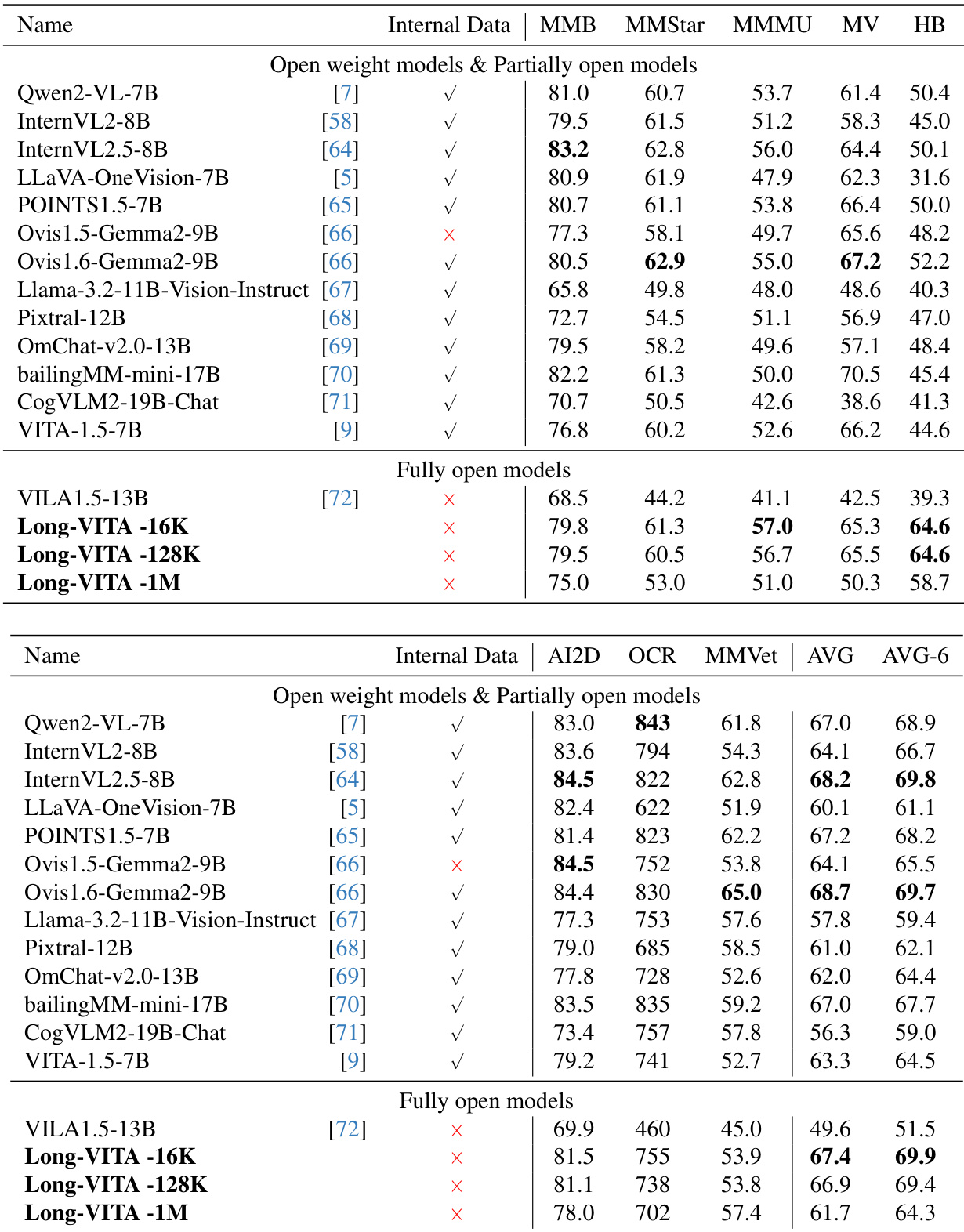
The authors compare Long-VITA models against various open weight and partially open models across multiple multimodal benchmarks. Results show that Long-VITA models achieve competitive performance on image and video understanding tasks using only open source data. Long-VITA-16K demonstrates superior performance on several image benchmarks compared to other models in the same parameter range The Long-VITA model series achieves high average scores across both objective and general multimodal evaluation collections Long-VITA models maintain strong capabilities in tasks involving visual reasoning and OCR
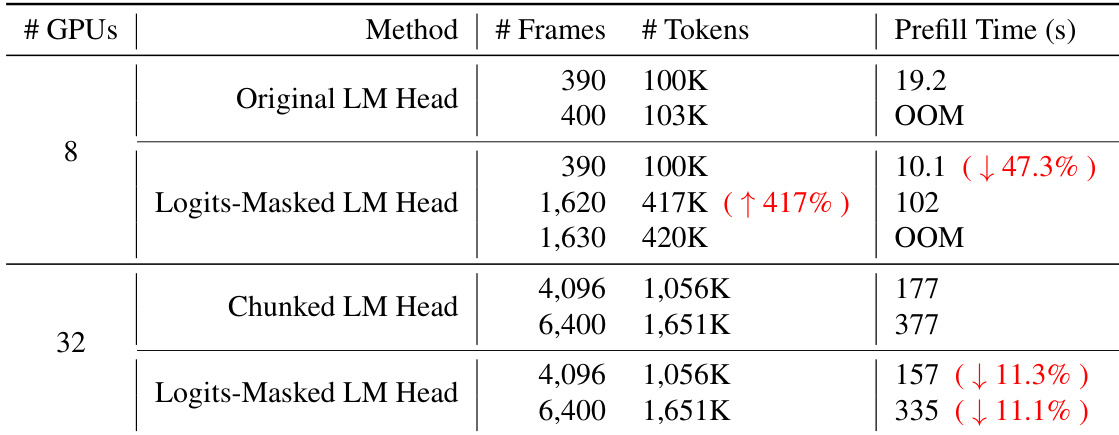
The authors compare different language modeling head designs to evaluate their impact on sequence length capacity and inference speed. The results demonstrate that the logits-masked LM head significantly improves the maximum supported tokens and reduces prefill time compared to the original method. The logits-masked LM head enables a much higher number of tokens before encountering out-of-memory errors compared to the original LM head The logits-masked LM head reduces prefill time relative to the original LM head The logits-masked LM head provides a speedup in prefill time when compared to the chunked LM head at higher token counts
The authors compare the performance of Long-VITA models against various open-weight, partially open, and fully open models on the LongVideoBench benchmark. The results demonstrate that Long-VITA models maintain strong video understanding capabilities across different temporal lengths, specifically within short, medium, and long context categories. Long-VITA-128K achieves competitive or superior performance in medium and long context video understanding compared to other models in its parameter class. The Long-VITA series shows robust performance across varying frame counts, ranging from short to long video sequences. Long-VITA models perform strongly on long-form video tasks without relying on internal or proprietary training data.
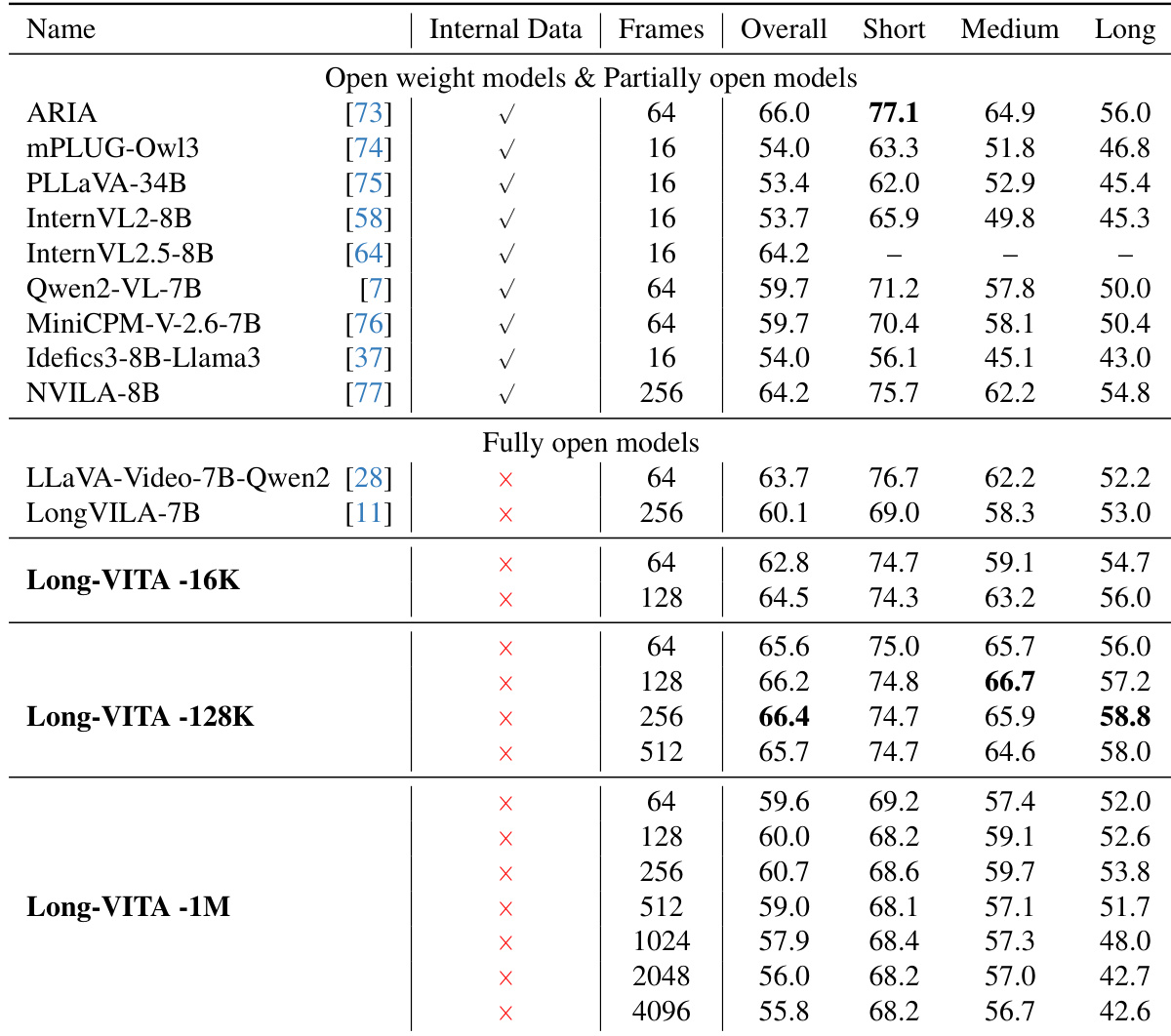
The Long-VITA models were evaluated across various multimodal benchmarks and architectural configurations to assess video understanding, image reasoning, and sequence capacity. The results demonstrate that the models maintain robust performance across diverse temporal lengths and frame counts, achieving competitive results in visual reasoning and OCR using only open source data. Furthermore, the implementation of a logits-masked LM head significantly enhances both sequence length capacity and inference speed compared to standard architectural designs.