Command Palette
Search for a command to run...
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Junying Chen Zhenyang Cai Ke Ji Xidong Wang Wanlong Liu Rongsheng Wang Jianye Hou Benyou Wang
Abstract
The breakthrough of OpenAI o1 highlights the potential of enhancing reasoning to improve LLM. Yet, most research in reasoning has focused on mathematical tasks, leaving domains like medicine underexplored. The medical domain, though distinct from mathematics, also demands robust reasoning to provide reliable answers, given the high standards of healthcare. However, verifying medical reasoning is challenging, unlike those in mathematics. To address this, we propose verifiable medical problems with a medical verifier to check the correctness of model outputs. This verifiable nature enables advancements in medical reasoning through a two-stage approach: (1) using the verifier to guide the search for a complex reasoning trajectory for fine-tuning LLMs, (2) applying reinforcement learning (RL) with verifier-based rewards to enhance complex reasoning further. Finally, we introduce HuatuoGPT-o1, a medical LLM capable of complex reasoning, which outperforms general and medical-specific baselines using only 40K verifiable problems. Experiments show complex reasoning improves medical problem-solving and benefits more from RL. We hope our approach inspires advancements in reasoning across medical and other specialized domains.
One-sentence Summary
HuatuoGPT-o1 is a medical large language model that advances complex reasoning via a two-stage approach combining fine-tuning guided by a medical verifier and reinforcement learning with verifier-based rewards on only 40K verifiable problems, outperforming general and medical-specific baselines.
Key Contributions
- This work introduces verifiable medical problems paired with a medical verifier to check the correctness of model outputs in a domain where verification is typically challenging. The proposal addresses the difficulty of verifying medical reasoning compared to mathematical tasks.
- A two-stage training approach is developed that uses the verifier to guide search for complex reasoning trajectories during fine-tuning and applies reinforcement learning with verifier-based rewards. Experiments demonstrate that this method improves medical problem-solving and benefits significantly from reinforcement learning enhancements.
- HuatuoGPT-o1 is introduced as a medical large language model capable of complex reasoning that outperforms general and medical-specific baselines. Performance gains are realized using only 40K verifiable problems, highlighting the efficiency of the proposed framework.
Introduction
Recent advancements in large language models highlight the value of complex reasoning, yet most efforts focus on mathematics rather than high stakes fields like medicine. Medical applications demand robust reasoning for reliable diagnoses, but verifying thought processes remains challenging without clear ground truths. The authors address this gap by constructing 40K verifiable medical problems and deploying a medical verifier to assess solution correctness. They introduce a two stage training framework that utilizes verifier guided search for fine tuning and reinforcement learning to refine complex reasoning capabilities. This approach yields HuatuoGPT-o1, a specialized model that outperforms general and medical specific baselines while demonstrating the efficacy of complex reasoning in healthcare contexts.
Dataset
-
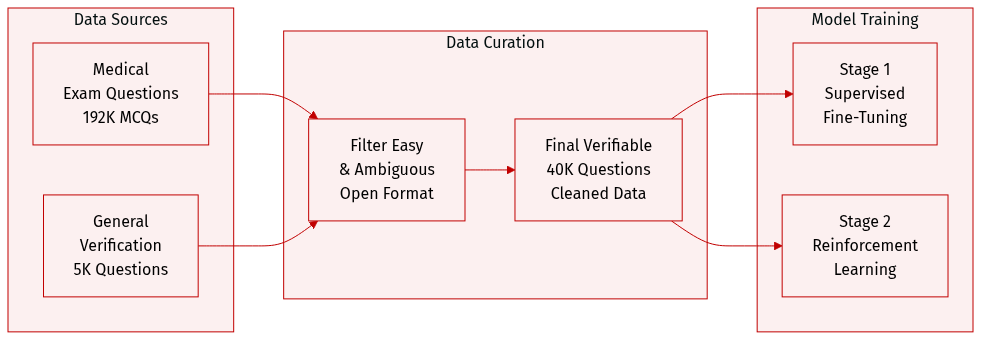
Dataset Composition and Sources
- The authors construct the core dataset from 192K medical multiple-choice exam questions sourced from the training sets of MedQA-USMLE and MedMcQA.
- They transform these closed-set questions into open-formal problems with unique ground-truth answers to enable reasoning verification.
- To support generalization, the collection includes 5K general verification questions from the non-medical tracks of MMLU-Pro.
-
Key Details and Filtering Rules
- Challenging questions are selected by removing items that three small LLMs (Gemma2-9B, LLaMA-3.1-8B, Qwen2.5-7B) answer correctly.
- Short questions and those lacking unique correct answers are discarded, with GPT-4o employed to filter out ambiguous cases.
- The final filtered medical dataset contains 40K verifiable questions.
- An additional 4K unconverted close-set questions are included to enhance generalization capabilities.
-
Training Splits and Usage
- The 40K medical questions are split evenly with 20K allocated for Supervised Fine-Tuning in Stage 1 and 20K for Reinforcement Learning in Stage 2.
- The general MMLU-Pro data is integrated alongside the medical data during the training process.
- All data undergoes strict screening to avoid contamination with evaluation benchmarks using a filter for 64 consecutive character overlaps.
-
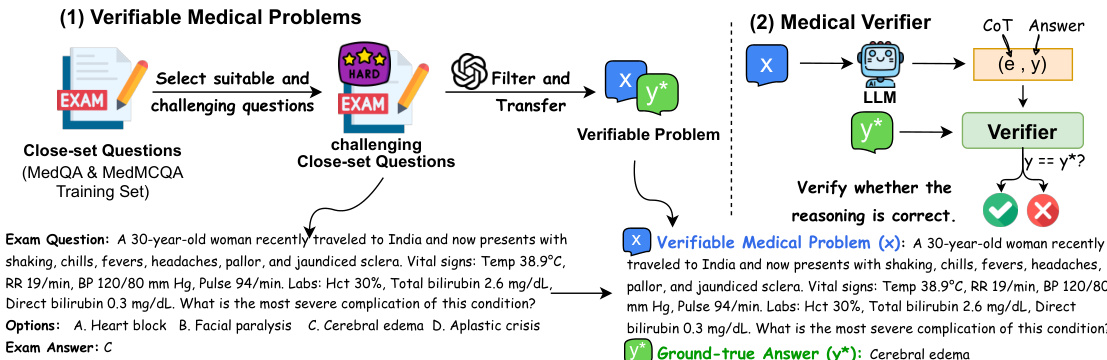
Processing and Verification Strategy
- GPT-4o reformats the selected multiple-choice questions into open-ended problems containing a specific query and a concise standard answer.
- A GPT-4o-based verifier checks model outputs against ground-truth answers to provide binary feedback for building correct reasoning trajectories.
- Exact match methods are avoided in favor of LLM-based verification due to the prevalence of aliases in the medical domain.
Method
The authors present a two-stage framework for training large language models (LLMs) to perform medical complex reasoning, emphasizing the development of a "thinks-before-it-answers" behavior. The overall methodology is structured into two distinct phases: Stage One, which focuses on learning complex reasoning through supervised fine-tuning (SFT), and Stage Two, which enhances reasoning capabilities using reinforcement learning (RL).
The process begins with the construction of verifiable medical problems, derived from closed-set question sets such as MedQA and MedMCQA. These problems are filtered and transformed into challenging, verifiable instances, each consisting of a question x and a ground-truth answer y∗. A medical verifier is employed to assess the correctness of model responses. The framework proceeds to Stage One, where the LLM is trained to generate complex reasoning trajectories. Given a problem x, an initial chain-of-thought (CoT) e0 and answer y0 are generated. The verifier checks if y0 matches y∗. If incorrect, the model iteratively refines the answer by applying one of four search strategies: exploring new paths, backtracking, verification, or corrections. This iterative search continues until the answer is verified as correct or a maximum number of iterations is reached. The successful reasoning trajectories are then reformatted into a coherent, natural language complex CoT (e^), which is used to train the model via SFT to produce a formal response (y^) for the question. This stage teaches the model to engage in deep, exploratory reasoning before providing a final answer.
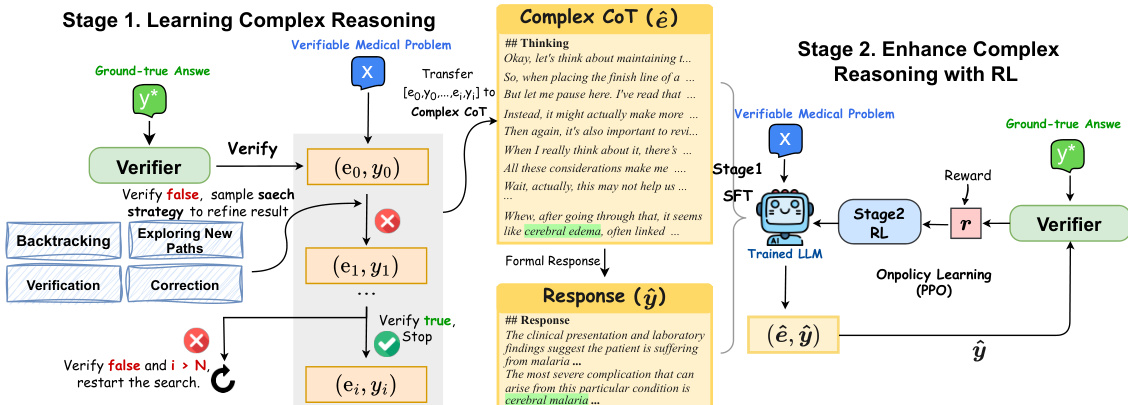

Stage Two further refines the model's reasoning skills using on-policy reinforcement learning. The fine-tuned model from Stage One serves as the initial policy πθ. The training objective is to improve the generation of complex CoT reasoning. The reward function is designed to guide the model towards correct and thorough reasoning. It assigns a high reward of 1 for a correct answer, a low reward of 0.1 for an incorrect answer, and a reward of 0 for responses that lack a think-before-answering behavior. To stabilize training with sparse rewards, the total reward combines this function score with the Kullback-Leibler (KL) divergence between the learned policy πθ and the initial policy πref, scaled by a coefficient β. The Proximal Policy Optimization (PPO) algorithm is used for RL training, where the policy samples responses, computes the reward, and updates its parameters.


Experiment
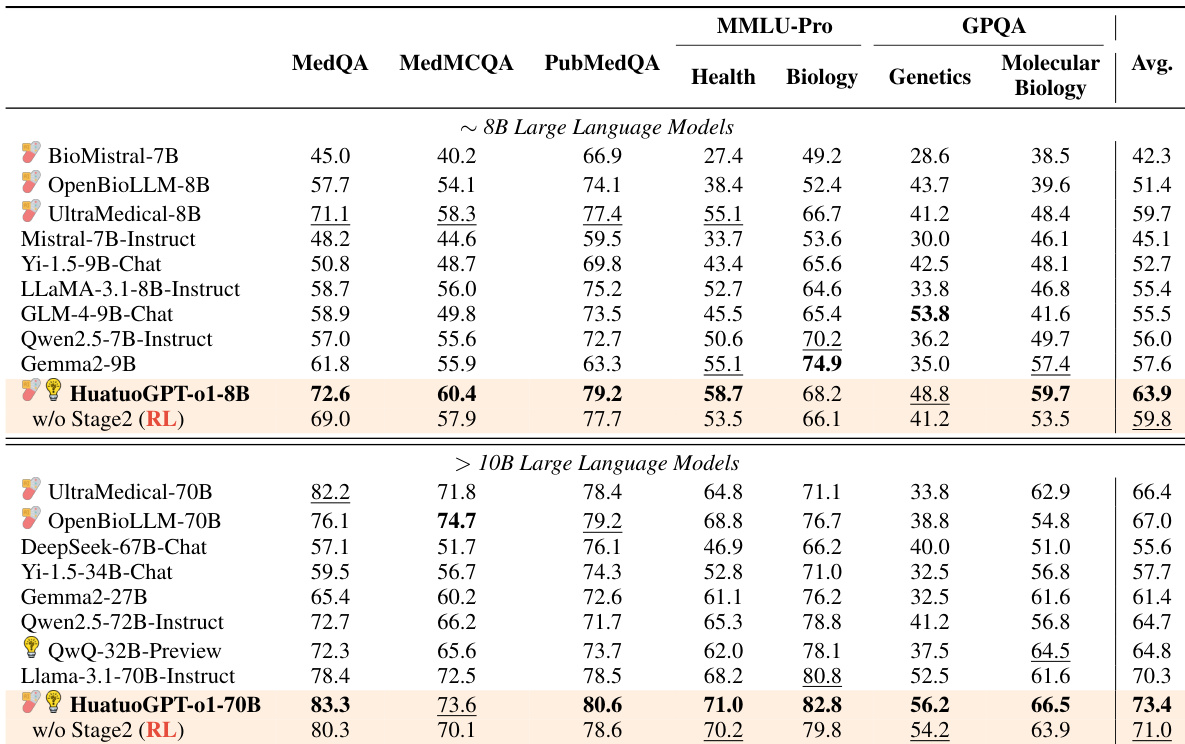
The evaluation assesses HuatuoGPT-o1 across traditional and challenging medical benchmarks to demonstrate its superiority over existing medical-specific and reasoning-focused models. Ablation studies validate that a two-stage training strategy incorporating complex chain-of-thought reasoning and PPO-based reinforcement learning significantly enhances problem-solving capabilities compared to simple fine-tuning. Additionally, the framework proves robust through high verifier reliability and successful adaptation to the Chinese medical domain, confirming the generalizability of the proposed approach.
The authors evaluate various large language models on medical benchmarks, showing that their model, HuatuoGPT-o1, achieves strong results across multiple datasets. The 8B and 70B versions outperform other open-source models, particularly on challenging tasks requiring reasoning and medical knowledge. HuatuoGPT-o1 models outperform other open-source LLMs on most medical benchmarks The 70B version surpasses models specifically designed for advanced reasoning capabilities Performance improvements are attributed to a two-stage training strategy involving complex chain-of-thought and reinforcement learning
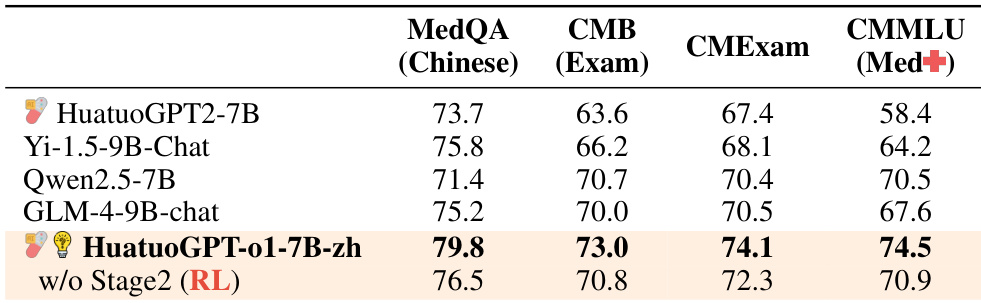
The authors compare the performance of various Chinese medical models on multiple benchmarks, including MedQA, CMB, CMEExam, and CMMLU. Results show that HuatuoGPT-o1-7B-zh achieves the highest scores across all evaluated datasets, demonstrating strong performance in the Chinese medical domain. HuatuoGPT-o1-7B-zh outperforms other Chinese medical models across all evaluated benchmarks. The model achieves the highest score on the CMMLU (Med+) benchmark among all compared models. The results demonstrate the effectiveness of the training approach in adapting to the Chinese medical domain.
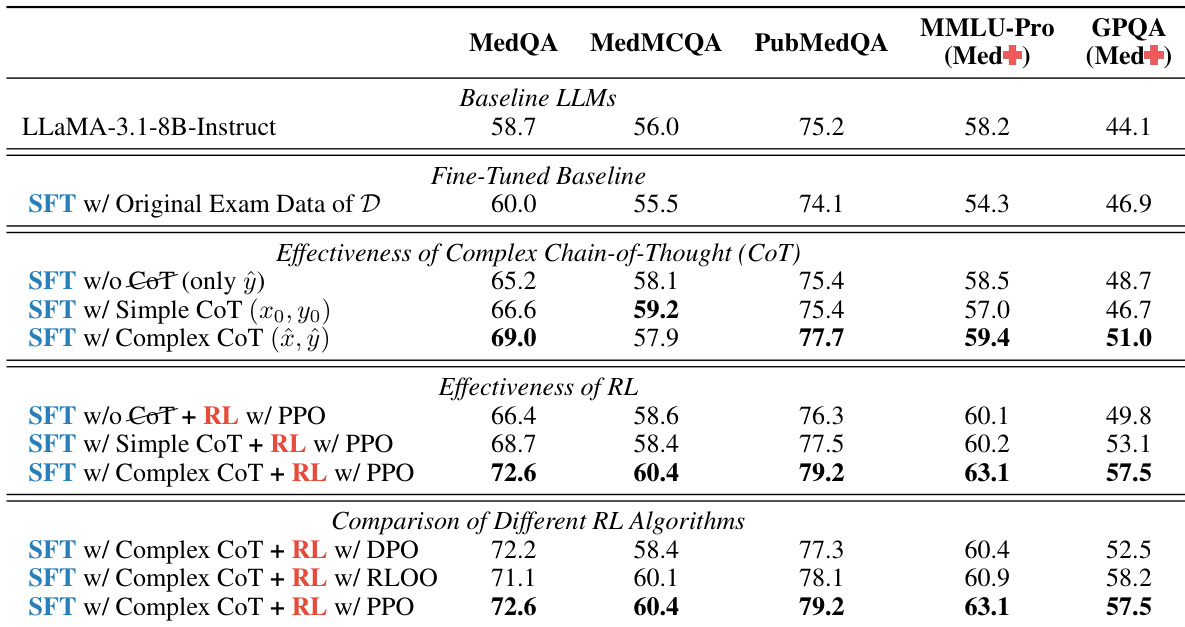
The authors conduct an ablation study to evaluate the effectiveness of different reasoning strategies and reinforcement learning algorithms on medical language models. Results show that Complex Chain-of-Thought reasoning and PPO-based reinforcement learning significantly improve performance compared to simpler methods. Complex CoT reasoning leads to substantial performance gains over simple CoT and direct learning PPO outperforms other reinforcement learning algorithms like DPO and RLOO The combination of Complex CoT and PPO yields the highest performance across all benchmarks
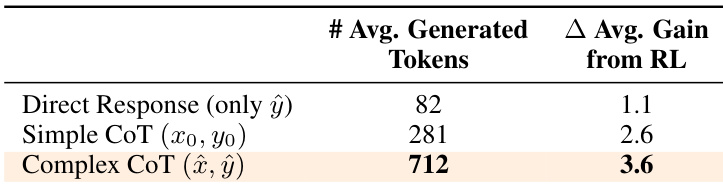
The the the table compares different reasoning strategies in terms of average generated tokens and performance gain from reinforcement learning. Results show that Complex CoT generates the most tokens and achieves the highest gain, indicating its effectiveness in enhancing model performance. Complex CoT generates significantly more tokens than other strategies. Complex CoT achieves the highest performance gain from reinforcement learning. Direct response results in the lowest token generation and minimal gain from reinforcement learning.
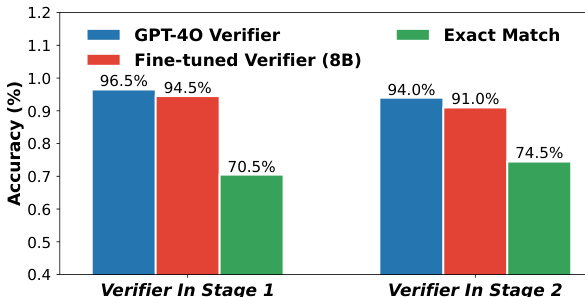
The authors compare the accuracy of two verifiers, GPT-4o and a fine-tuned 8B model, across two stages. Results show that GPT-4o achieves higher accuracy than the fine-tuned verifier in both stages, with a notable performance gap on the more challenging Stage 2 tasks. GPT-4o verifier outperforms the fine-tuned verifier in both stages The performance gap between the two verifiers widens in Stage 2 The fine-tuned verifier shows lower accuracy, particularly in Stage 2
The authors evaluate HuatuoGPT-o1 across general and Chinese-specific medical benchmarks, demonstrating superior performance over existing open-source models particularly in reasoning-intensive tasks. Ablation studies confirm that these gains are driven by a two-stage training strategy combining Complex Chain-of-Thought reasoning with PPO-based reinforcement learning. Additionally, verifier comparisons indicate that GPT-4o maintains higher accuracy than fine-tuned alternatives, especially on challenging evaluation stages.