Command Palette
Search for a command to run...
Allegro: Open the Black Box of Commercial-Level Video Generation Model
Allegro: Open the Black Box of Commercial-Level Video Generation Model
Yuan Zhou Qiuyue Wang Yuxuan Cai Huan Yang
Abstract
Significant advancements have been made in the field of video generation, with the open-source community contributing a wealth of research papers and tools for training high-quality models. However, despite these efforts, the available information and resources remain insufficient for achieving commercial-level performance. In this report, we open the black box and introduce Allegro, an advanced video generation model that excels in both quality and temporal consistency. We also highlight the current limitations in the field and present a comprehensive methodology for training high-performance, commercial-level video generation models, addressing key aspects such as data, model architecture, training pipeline, and evaluation. Our user study shows that Allegro surpasses existing open-source models and most commercial models, ranking just behind Hailuo and Kling. Code: https://github.com/rhymes-ai/Allegro , Model: https://huggingface.co/rhymes-ai/Allegro , Gallery: https://rhymes.ai/allegro_gallery .
One-sentence Summary
The authors from Rhymes AI propose Allegro, a high-performance video generation model that achieves commercial-level quality and temporal consistency through a comprehensive training methodology encompassing optimized data, architecture, and evaluation, outperforming most open-source models and nearing top commercial systems in user studies.
Key Contributions
- The paper addresses the gap in open-source video generation by introducing Allegro, a high-performance model that achieves commercial-level quality and temporal consistency, overcoming key challenges in data modeling, text-video alignment, and control precision that hinder prior systems.
- Allegro's methodology includes a novel data curation pipeline producing a 106M-image and 48M-video dataset with aligned captions, along with architectural improvements to the VAE and Diffusion Transformer for better video generation efficiency and fidelity.
- In user studies and benchmark evaluations across six dimensions, Allegro outperforms all existing open-source models and most commercial systems, ranking just behind Hailuo and Kling in overall quality while excelling in video-text relevance and visual coherence.
Introduction
The authors leverage diffusion-based models to address the growing demand for automated, high-quality video generation, particularly in applications like digital content creation, advertising, and entertainment. While open-source text-to-image models have reached commercial parity, text-to-video generation lags due to unresolved challenges in modeling long-range temporal dynamics, aligning video content with complex textual prompts, and scaling training data with accurate semantic annotations. Prior work often lacks transparency in data curation, model design, and evaluation, limiting reproducibility and performance. The authors introduce Allegro, a commercial-level text-to-video model that achieves state-of-the-art results through a comprehensive pipeline: a curated dataset of 106M images and 48M videos with aligned captions, a redesigned VAE and DiT architecture optimized for video, and a multi-dimensional evaluation framework including user studies. Allegro outperforms existing open-source models and rivals top commercial systems in quality and relevance, with future extensions focusing on image-to-video generation with text conditioning and fine-grained motion control.
Dataset
- The dataset is built from a large pool of raw images and videos sourced from public collections including WebVid, Panda-70M, HD-VILA, HD-VG, and OpenVid-1M, forming the foundation for diverse and extensive video data.
- A systematic data curation pipeline processes this raw data through seven sequential filtering steps: duration and resolution filtering (retaining clips ≥2 seconds, ≥360p resolution, ≥23 FPS), scene segmentation (splitting videos into single-scene clips, removing first and last 10 frames), low-level metrics filtering (evaluating brightness, clarity via DOVER, semantic consistency via LPIPS, and motion amplitude via UniMatch), aesthetics filtering (using LAION Aesthetics Predictor), content-irrelevant artifacts filtering (removing watermarks, text, black borders via detection tools), coarse-grained captioning (using Tag2Text on middle frames), and CLIP similarity filtering (retaining samples with high caption-visual alignment).
- All video clips are re-encoded to H.264 at 30 FPS, with final clips ranging from 2 to 16 seconds, single-shot, and high quality.
- After filtering, data is annotated with both coarse- and fine-grained captions using Aria, a finetuned video captioning model. Fine-grained captions include spatial details (subjects, background, style), temporal dynamics (motion, interactions), and explicit camera control cues (e.g., "Camera [MOTION_PATTERN]").
- The data is stratified into three training-stage-specific subsets:
- Text-to-image pre-training: 107M image-text pairs from 412M raw images, used to train image generation from text.
- Text-to-video pre-training: 48M video clips at 360p and 18M at 720p, used to learn temporal consistency from text.
- Text-to-video fine-tuning: 2M high-quality video clips, selected for final optimization of video generation quality and coherence.
- Data distribution analysis shows progressive refinement: pre-training stages use balanced durations (short, medium, long), while fine-tuning focuses exclusively on medium to long-duration videos (6–16 seconds) with moderate motion and semantic variation.
- For VideoVAE training, only data with shortest side ≥720 pixels is used, resulting in 54.7K videos and 3.73M images. Spatial augmentation uses only random cropping; temporal augmentation applies random frame sampling intervals from [1, 3, 5, 10] to accelerate temporal layer convergence.
- Training uses L1 and LPIPS loss (weights 1.0 and 0.1), with a two-stage process: joint training of image and video data (16-frame videos + 4 images per batch) followed by freezing image VAE spatial layers and fine-tuning temporal layers on 24-frame videos.
- The filtering pipeline significantly improves data quality, eliminating blurry, poorly focused, or artifact-laden content, while preserving sharp, aesthetically pleasing, and semantically rich samples such as dynamic scenes of nature, human activities, and detailed interactions.
Method
The authors leverage a Video Variational Auto-Encoder (VideoVAE) to enable efficient modeling of high-dimensional video data within a compressed latent space. The VideoVAE architecture is built upon an existing image VAE, specifically the Playground v2.5 model, to retain its strong spatial compression capabilities. To extend this foundation for video, the authors incorporate temporal modeling layers. The framework begins by applying a 1D temporal CNN layer at the input and output of the image VAE's encoder and decoder, respectively. Additionally, a temporal block, composed of four 3D CNN layers, is inserted after every ResNet block in the VAE. This design allows the model to capture temporal dependencies and perform temporal compression. Temporal downsampling is achieved through strided convolution with a stride of 2, while upsampling is performed by frame repetition followed by a deconvolution operation. The final VideoVAE model, with a parameter count of 174.96M, achieves a compression ratio of 4×8×8 in the temporal, height, and width dimensions, respectively, resulting in a latent representation of shape T/ST×Cl×H/SH×W/SW from an input video of shape T×3×H×W. The latent space retains a channel dimension of Cl=4 from the base image VAE.
The VideoVAE is a critical component of the overall video generation framework, which is built around a Video Diffusion Transformer (VideoDiT). The VideoDiT framework, as illustrated in the figure below, consists of three primary modules that work in concert to generate videos from text. The first module is a text encoder, which converts natural language descriptions into text embeddings. The authors replace the original mT5 text encoder with the T5 encoder to improve text-to-video alignment and enhance the quality and coherence of the generated videos. The second module is the VideoVAE, which encodes the input video frames into a compressed latent space, enabling efficient diffusion modeling. The third and central module is the video Transformer network, which processes both the visual tokens from the VideoVAE and the text embeddings to predict the noise for the diffusion process.
The core of the VideoDiT is a video Transformer composed of multiple Diffusion Transformer (DiT) blocks. Each DiT block contains a self-attention module with 3D RoPE, which models video tokens across both spatial and temporal dimensions, a cross-attention module that injects textual conditions to guide generation, a feed-forward layer, and AdaLN-single modules that incorporate information from the diffusion timestep. The use of 3D attention is a key design choice, as it enables the model to capture full spatio-temporal dependencies, leading to improved video consistency and dynamic motion compared to methods that use separate 2D and 1D attention. The model is trained using a multi-stage strategy to progressively build capabilities. The first stage is text-to-image pre-training, which establishes a mapping between text and images. The second stage is text-to-video pre-training, which is conducted in three sub-stages of increasing complexity: first with 40 frames at 368×640 resolution, then scaling to 720×1280 resolution with the same frame count, and finally increasing the video length to 88 frames at 720×1280 resolution. The final stage is text-to-video fine-tuning, which uses a batch of high-quality dynamic videos to further enhance the model's ability to generate high-quality, diverse videos.
Experiment
- Evaluated VideoVAE against open-source 3D VAEs (Open-Sora v1.2, Open-Sora-Plan v1.2.0) on a 100-video validation set (120 frames, 720p), achieving PSNR of 31.25 and SSIM of 0.8553, outperforming all competitors with reduced flickering and better detail preservation.
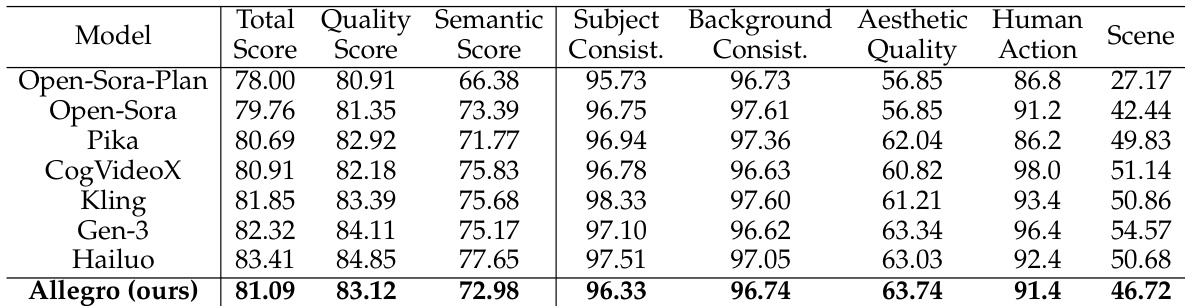
- Evaluated Allegro model on VBench using 4,730 videos generated from 946 text prompts, achieving top performance among open-source models and ranking just behind Gen-3, Kling, and Hailuo in overall score.
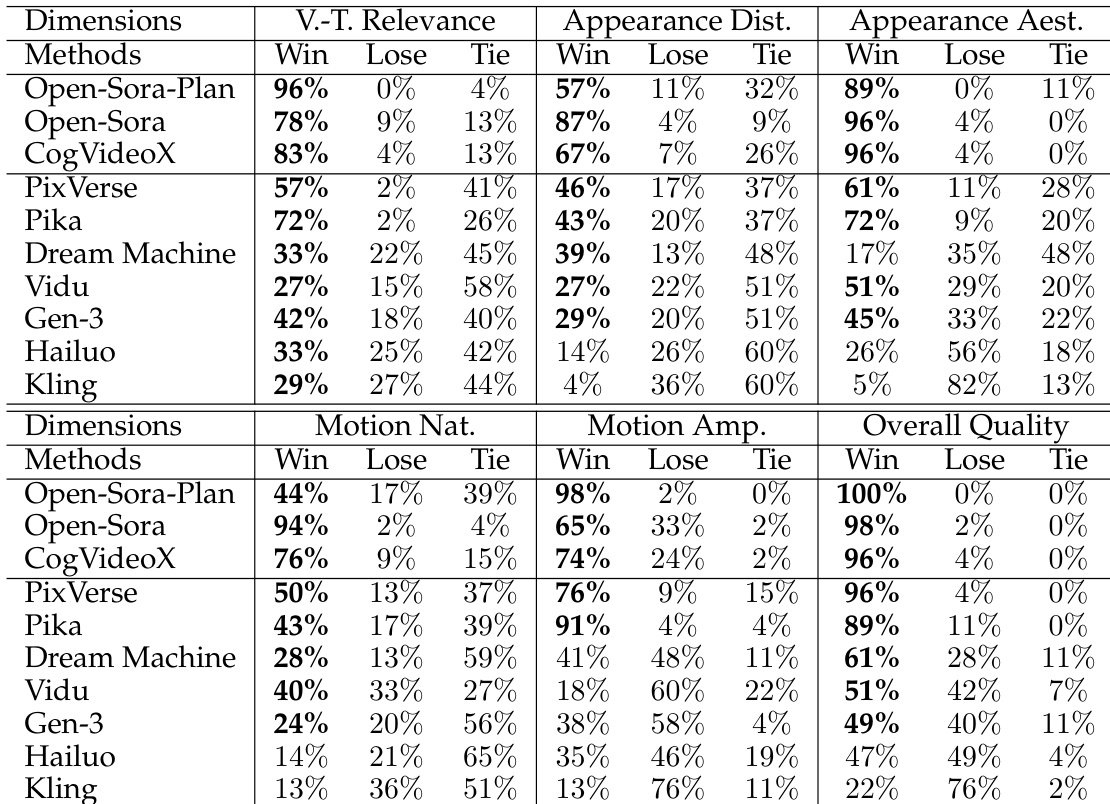
- User study on 46 diverse prompts showed Allegro outperforms all open-source models and most commercial models across six dimensions: video-text relevance, appearance distortion, appearance aesthetics, motion naturalness, motion amplitude, and overall quality, with superior text-to-video alignment.
- Ablation studies confirm that using a fine-tuned T5 text encoder significantly improves semantic fidelity over mT5, and multi-stage training (from 40×368×640 to 88×720×1280) enables progressive enhancement in motion quality and visual realism.
The authors use a multi-stage training approach to improve video generation, starting with low-resolution frames and gradually increasing resolution and frame count to enhance motion quality and visual detail. Results show that the final fine-tuning stage significantly improves aesthetics, motion naturalness, and text-video alignment, with the model achieving strong performance across all evaluation dimensions.

The authors use a validation set of 100 videos to evaluate the performance of their VideoVAE model against existing open-source VideoVAEs, measuring reconstruction quality using PSNR and SSIM. Results show that their VideoVAE achieves higher PSNR and SSIM values than Open-Sora and Open-Sora-Plan, with scores of 31.25 and 0.8553 respectively, indicating superior reconstruction quality and reduced flickering and distortion.

The authors conduct a user study comparing their Allegro model with several open-source and commercial video generation models across six evaluation dimensions. Results show that Allegro outperforms all open-source models and achieves strong performance against commercial models, particularly excelling in video-text relevance and overall quality, though it lags behind top commercial models in motion amplitude.
The authors use a multi-stage training approach for their model, starting with a T2I pre-trained model and progressively increasing resolution and frame count. Results show that the final T2V fine-tune stage achieves the highest performance with the lowest number of steps and data, indicating efficient training.

The authors evaluate their Allegro model against several open-source and commercial video generation models using the VBench benchmark. Results show that Allegro outperforms all open-source models and ranks among the top commercial models, achieving the highest scores in video-text relevance and overall quality while demonstrating strong performance across all evaluated dimensions.