Command Palette
Search for a command to run...
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Abstract
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024×1024 resolution image. Sana enables content creation at low cost. Code and model will be publicly released.
One-sentence Summary
The authors, from NVIDIA, MIT, and Tsinghua University, propose Sana, a compact text-to-image framework leveraging a 32× deep compression autoencoder, linear DiT, and a decoder-only text encoder with in-context learning to achieve high-resolution (up to 4096×4096) image generation with strong text alignment. By integrating Flow-DPM-Solver and efficient training, Sana-0.6B delivers performance comparable to 12B-scale models while being 20× smaller and over 100× faster, enabling real-time, low-cost image synthesis on consumer GPUs.
Key Contributions
- Sana addresses the challenge of generating high-resolution (up to 4096×4096) images efficiently, enabling real-time, low-cost image synthesis on consumer hardware like laptop GPUs, in contrast to large-scale models that require expensive cloud infrastructure.
- The framework introduces a deep compression autoencoder with 32× compression, linear DiT with O(N) complexity replacing quadratic attention, and a decoder-only LLM (Gemma) as the text encoder with complex human instruction prompting, significantly improving efficiency and text-image alignment.
- Sana-0.6B achieves over 100× faster throughput than FLUX for 4K generation and under 1 second for 1024×1024 images on a 16GB GPU, while maintaining competitive performance on benchmarks and enabling deployment via quantization on edge devices.
Introduction
The authors leverage recent advances in diffusion transformers and large language models to address the growing challenge of high computational cost in high-resolution text-to-image generation. While state-of-the-art models like FLUX and Playground v3 achieve impressive results, they require massive parameters and expensive hardware, limiting accessibility for real-time or edge deployment. Prior work has focused on scaling up model size and improving architectures, but few have prioritized efficiency at ultra-high resolutions—especially 4K—without sacrificing quality. The authors introduce Sana, a system that achieves 4K image synthesis with a 0.6B parameter model by combining a deep compression autoencoder (AE-F32) that reduces latent token count by 16×, a linear diffusion transformer with Mix-FFN that cuts computational complexity from O(N²) to O(N), and a decoder-only LLM (Gemma) as a text encoder to enhance prompt understanding. They further optimize training with multi-VLM captioning and a clipscore-based selection strategy, and accelerate inference using a Flow-DPM-Solver. The result is a 106× speedup over FLUX for 4K generation and sub-second inference on consumer GPUs, enabling efficient, high-quality image synthesis on both cloud and edge devices.
Dataset
- The dataset comprises image-caption pairs sourced from curated visual content, with captions generated by multiple models including VILA-3B and InternVL2-26B, alongside original human-written captions.
- Each caption is evaluated using ClipScore, with the highest-scoring versions selected for inclusion; the provided examples reflect high-quality, semantically rich descriptions of a Valentine’s Day chocolate cake.
- The image features a round chocolate cake with glossy ganache, red heart-shaped decorations, chocolate shavings, and the text "HAPPY VALENTINE" in red icing, set against a dark wooden background.
- The dataset uses a training split where image-caption pairs are combined in a mixture ratio favoring model-generated captions with high ClipScore, ensuring alignment with visual content.
- No explicit cropping is applied; instead, the full image composition is preserved to maintain contextual integrity.
- Metadata is constructed around object positions, color contrasts, and thematic cues (e.g., Valentine’s Day), enabling fine-grained understanding of scene elements.
- The authors use this data to train and evaluate multimodal models, leveraging the detailed, consistent captions to improve alignment between visual and textual representations.
Method
The authors leverage a comprehensive framework designed to achieve high-resolution, high-quality text-to-image generation with exceptional efficiency. The core of the Sana system is built upon a deep compression autoencoder, a linear DiT architecture, a decoder-only text encoder enhanced with complex human instruction, and a flow-based inference method. The overall architecture is illustrated in Figure 5(a), which provides a high-level overview of the training pipeline. The process begins with a user prompt, which is processed by a small decoder-only language model (LLM) to generate an enhanced prompt through a complex human instruction (CHI) mechanism. This enhanced prompt, along with a time embedding, is fed into the Linear DiT, which operates in the latent space produced by the deep compression autoencoder. The autoencoder, which compresses the input image by a factor of 32, is trained to produce a latent representation that the DiT can effectively denoise. The Linear DiT, detailed in Figure 5(b), is the central generative component, designed for efficiency at high resolutions. It replaces the standard self-attention mechanism with linear attention, which reduces computational complexity from O(N2) to O(N) by computing shared terms that are reused for each query. This is achieved by replacing the softmax attention with ReLU linear attention, as shown in the equation for the output Oi. To further improve training efficiency and performance, the authors employ a Mix-FFN block, which replaces the standard MLP-FFN. This block incorporates a 3×3 depth-wise convolution to better capture local information, compensating for the weaker local information-capturing ability of ReLU linear attention. A key design choice in the DiT is the complete omission of positional embeddings (NoPE), which is enabled by the use of 3×3 convolutions that implicitly incorporate position information. The text encoder is a small decoder-only LLM, such as Gemma-2, which is chosen for its strong instruction-following capabilities. To stabilize training, the authors apply RMSNorm to the text embeddings and use a small learnable scale factor to normalize their variance. The complex human instruction (CHI) is a critical component for enhancing text-image alignment, as it guides the LLM to generate more detailed and relevant descriptions from a simple user prompt. This is demonstrated in Figure 7, where the use of CHI leads to more stable and detailed generations compared to the baseline. The training process is further optimized through a multi-stage approach, starting from 512px and gradually fine-tuning to higher resolutions, and an efficient data curation pipeline that uses multiple VLMs for auto-labeling and a CLIP-score-based sampler to select high-quality captions. The inference process is accelerated by a flow-based DPM-Solver, which is adapted from DPM-Solver++ to use velocity prediction and operates on a redefined time-step range. This method converges in significantly fewer steps than traditional samplers, as shown in Figure 8, where the Flow-DPM-Solver achieves better results with 14-20 steps compared to the Flow-Euler's 28-50 steps. The entire system is designed to be highly efficient, enabling the generation of 4096×4096 images on a 16GB laptop GPU.
Experiment
- On-device deployment with W8A8 quantization achieved a 2.4× speedup on a laptop GPU for 1024px image generation, reducing inference time to 0.37 seconds while maintaining near-lossless image quality, enabled by CUDA C++ GEMM kernel fusion and optimized activation layout.
- Sana-0.6B and Sana-1.6B demonstrated 5× and 39× higher throughput than PixArt-Σ and 23× faster than Sana-1.6B at 512px and 1024px resolutions, respectively, outperforming state-of-the-art models in FID, CLIP-Score, GenEval, and DPG-Bench, with competitive performance against FLUX-dev despite smaller size.
- Replacing DiT’s attention and FFN with linear attention and Mix-FFN reduced latency by 14% at 1024px, and Triton kernel fusion further improved speed by ~10%, with MACs reduced by 4× when upgrading from AE-F8C4P2 to AE-F32C32P1, enabling faster inference at higher resolutions.
- Gemma-2B text encoder achieved better performance than T5-large at similar speed and comparable results to T5-XXL, while enabling zero-shot generation from Chinese and Emoji prompts despite English-only training, demonstrating strong cross-lingual generalization.
- Sana-1.6B generated 1K×1K images in under 1 second on a laptop GPU, and 4K images showed significantly more detail than 1K, validating high-resolution scalability and real-world deployability.
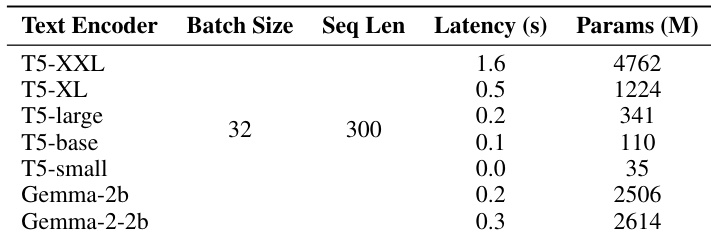
The authors use the table to present the architectural specifications of two Sana models, Sana-0.6B and Sana-1.6B, showing that the larger model has greater width, depth, and parameter count. Results show that Sana-1.6B has a significantly larger number of parameters and a deeper architecture compared to Sana-0.6B, reflecting a more complex model design.

Results show that Sana-0.6B and Sana-1.6B achieve competitive performance on 512×512 resolution, with Sana-1.6B outperforming PixArt-Σ in overall metrics. At 1024×1024 resolution, Sana models maintain strong performance, with Sana-0.6B and Sana-1.6B achieving higher overall scores than several larger models, including LUMINA-Next and SDXL, while also demonstrating superior efficiency.
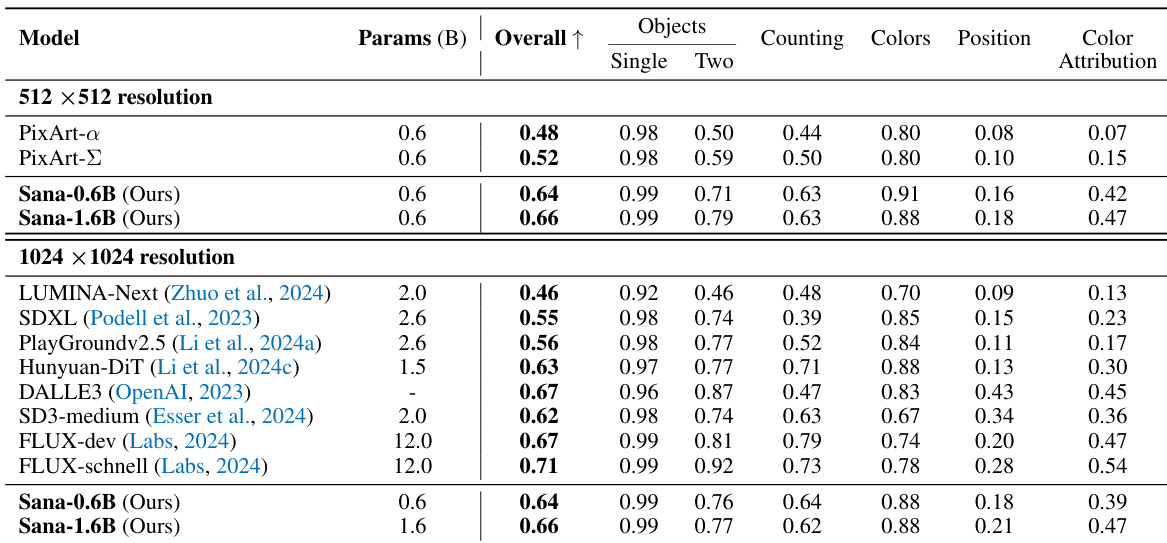
The authors use a series of optimizations to reduce the model size and improve inference speed while maintaining performance. Results show that the final Sana model achieves a 106x speedup compared to Flux-dev, with a parameter count reduced from 12B to 0.6B, and only a minor drop in GenEval and DPG-Bench scores.
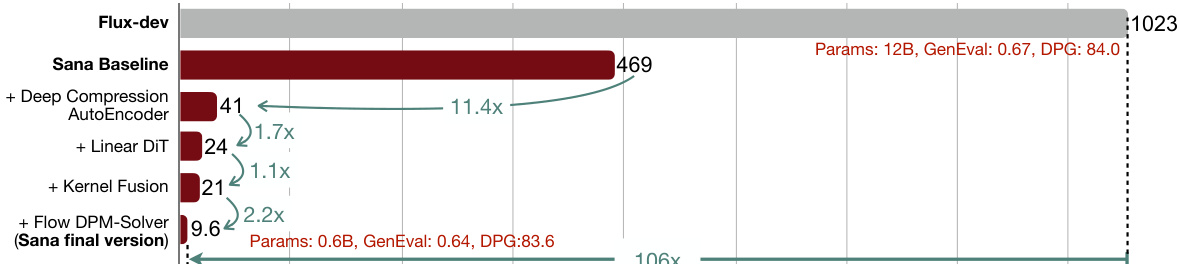
The authors compare Sana models with other text-to-image diffusion models at 512×512 and 1024×1024 resolutions, showing that Sana-0.6B achieves 5× faster throughput than PixArt-Σ at 512×512 and 39× faster than FLUX-dev at 1024×1024 while maintaining competitive image quality. At 1024×1024 resolution, Sana-0.6B and Sana-1.6B achieve significantly higher throughput than most models with fewer than 3B parameters, with Sana-0.6B reaching 1.7 samples per second and Sana-1.6B reaching 1.0 samples per second, outperforming larger models in inference speed.
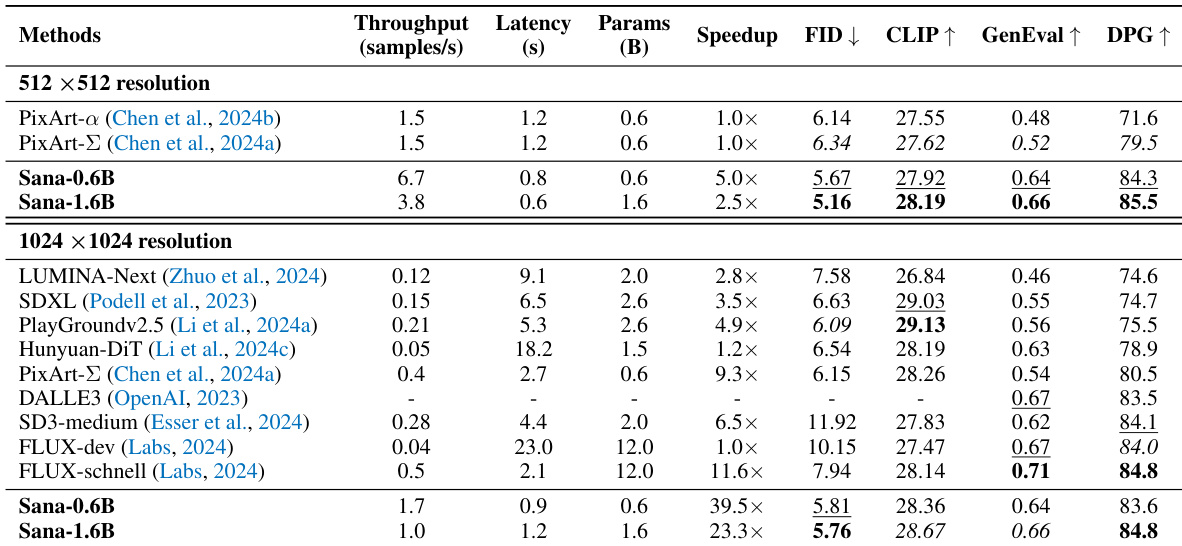
The authors compare different text encoders in terms of latency and model parameters, showing that Gemma-2b and Gemma-2-2b achieve similar or lower latency than T5 models while having significantly larger parameter counts. Gemma-2b demonstrates a balance of efficiency and performance, outperforming T5-large in speed and matching T5-XXL in quality despite having fewer parameters.