Command Palette
Search for a command to run...
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Jiaxiang Tang Zhaoxi Chen Xiaokang Chen Tengfei Wang Gang Zeng Ziwei Liu
Abstract
3D content creation has achieved significant progress in terms of both quality and speed. Although current feed-forward models can produce 3D objects in seconds, their resolution is constrained by the intensive computation required during training. In this paper, we introduce Large Multi-View Gaussian Model (LGM), a novel framework designed to generate high-resolution 3D models from text prompts or single-view images. Our key insights are two-fold: 1) 3D Representation: We propose multi-view Gaussian features as an efficient yet powerful representation, which can then be fused together for differentiable rendering. 2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operating on multi-view images, which can be produced from text or single-view image input by leveraging multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our approach. Notably, we maintain the fast speed to generate 3D objects within 5 seconds while boosting the training resolution to 512, thereby achieving high-resolution 3D content generation.
One-sentence Summary
Peking University, Nanyang Technological University, and Shanghai AI Lab propose LGM, a feed-forward framework that generates high-resolution 3D Gaussians in under 5 seconds by fusing multi-view images from text or single-view inputs via an asymmetric U-Net backbone, overcoming prior limitations in resolution and efficiency by leveraging Gaussian splatting and robust data augmentation, enabling fast, high-fidelity 3D content creation for applications in gaming, VR, and film.
Key Contributions
-
The paper addresses the challenge of high-resolution 3D content creation by introducing LGM, a feed-forward framework that generates detailed 3D Gaussians from single-view images or text prompts, overcoming the resolution limitations of prior feed-forward methods that rely on low-resolution triplane representations.
-
LGM proposes a novel asymmetric U-Net backbone operating on multi-view images to efficiently predict and fuse 3D Gaussian features, enabling end-to-end differentiable rendering and training at a resolution of 512—significantly higher than previous methods—while maintaining fast inference speeds of under 5 seconds.
-
The method demonstrates superior performance on both text-to-3D and image-to-3D tasks, achieving high-fidelity results with up to 65,536 Gaussians, and includes data augmentations to bridge the domain gap between real and synthesized multi-view images, along with a general mesh extraction pipeline for downstream applications.
Introduction
The authors leverage 3D Gaussian splatting as a high-fidelity, efficient representation to enable fast, high-resolution 3D content generation from text or single-view images. Prior feed-forward methods rely on triplane-based NeRF or transformer backbones, which limit resolution due to memory constraints and inefficient rendering, while optimization-based approaches like SDS are slow despite higher detail. The key contribution is a novel framework using an asymmetric U-Net to regress dense 3D Gaussians from multi-view inputs, enabling end-to-end training at 512×512 resolution and generating high-quality 3D models in under 5 seconds. The method integrates multi-view diffusion models for input synthesis, applies targeted data augmentations to handle domain gaps, and includes a general mesh extraction pipeline, achieving state-of-the-art speed and resolution in both text-to-3D and image-to-3D tasks.
Dataset
- The dataset is derived from Objaverse, a large-scale 3D object repository, with filtering applied using a predefined list of words to exclude unwanted or low-quality scenes.
- The filtering keywords include: flying, mountain, trash, featuring, a set of, a small, numerous, square, collection, broken, group, ceiling, wall, various, elements, splatter, resembling, landscape, stair, silhouette, garbage, debris, room, preview, floor, grass, house, beam, white, background, building, cube, box, frame, roof, structure.
- For each scene, 100 camera views are generated along a spiral path on a spherical surface, ensuring diverse and uniform spatial coverage.
- The camera radius is fixed at 1.5 units, and the vertical field-of-view is set to 49.1 degrees to maintain consistent perspective and depth.
- The authors use these filtered and rendered views as part of the training data, combining them with other datasets in a carefully balanced mixture ratio.
- No explicit cropping is applied; instead, the full rendered image is used, with metadata such as camera pose and scene ID constructed during the rendering pipeline to support training and evaluation.
Method
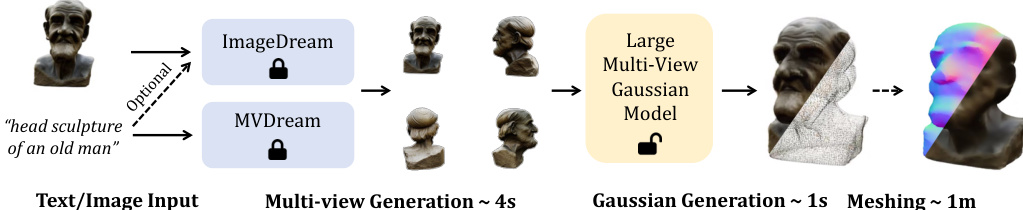
The authors leverage a two-step pipeline for high-resolution 3D content generation, beginning with the synthesis of multi-view images from text or image inputs using off-the-shelf models. Specifically, MVDream is employed for text-to-multi-view generation, while ImageDream handles image (and optionally text) inputs, both producing four orthogonally oriented views at a fixed elevation. These multi-view images serve as input to a core U-Net-based model designed to predict and fuse 3D Gaussians. The overall framework is illustrated in the pipeline diagram, where the initial multi-view generation step is followed by Gaussian generation and optional mesh extraction.
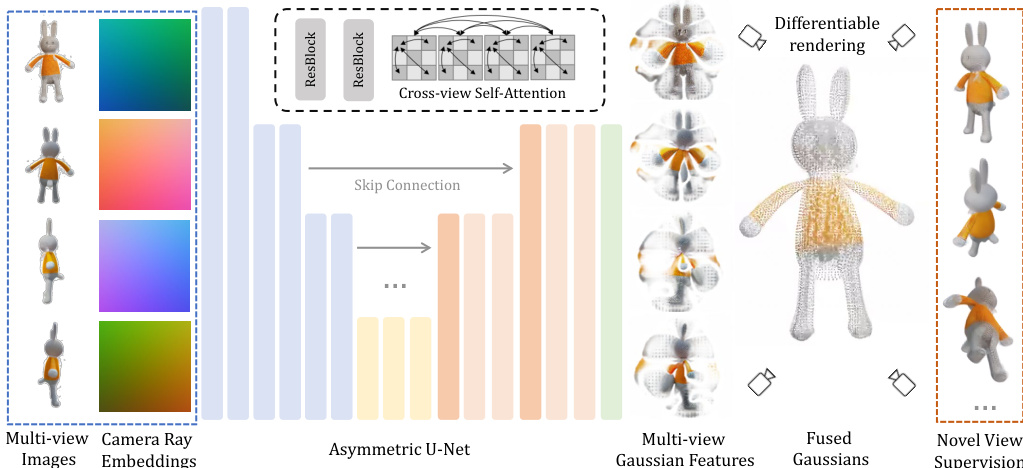
The central component of the framework is an asymmetric U-Net architecture, as shown in the detailed architecture diagram. This network takes four input images and their corresponding camera ray embeddings as input. The RGB values and ray embeddings are concatenated to form a 9-channel feature map for each pixel, which is then processed through the U-Net. The architecture incorporates residual layers and self-attention mechanisms, with self-attention applied at deeper layers to reduce memory consumption. To enable cross-view information propagation, the features from the four input views are flattened and concatenated before self-attention is applied. The output of the U-Net is a feature map with 14 channels, which is interpreted as the parameters of 3D Gaussians. The network is designed to be asymmetric, with a lower output resolution than the input, allowing for higher-resolution inputs while limiting the number of output Gaussians. The predicted Gaussian parameters, including position, scale, rotation, opacity, and color, are fused across the four views to form the final 3D Gaussian representation.
To ensure robustness during training, the authors implement a data augmentation strategy to bridge the domain gap between training data (rendered from the Objverse dataset) and inference data (synthesized by diffusion models). This includes grid distortion, where three of the four input views are randomly distorted to simulate the inconsistencies inherent in multi-view diffusion outputs, and orbital camera jitter, where the camera poses of the last three views are randomly rotated around the scene center to account for inaccuracies in ray embeddings. The model is trained using a differentiable renderer to supervise the generated Gaussians. At each training step, images are rendered from eight views—four input views and four novel views—and the loss is computed using mean square error on both the RGB and alpha images. Additionally, a VGG-based LPIPS loss is applied to the RGB images to improve perceptual quality.
Experiment
- Image-to-3D: Compared with [47, 62], our method generates 3D Gaussians with higher visual quality and better content preservation, enabling smooth textured meshes with minimal quality loss. Multi-view setting effectively reduces blur in back views and flat geometry, improving detail in unseen views.
- Text-to-3D: Outperforms [16, 47] in realism and efficiency, achieving better text alignment and avoiding multi-face issues due to multi-view diffusion modeling.
- Diversity: Demonstrates high diversity in 3D generation from ambiguous text or single-view images, producing varied plausible objects across different random seeds.
- User Study (Table 1): On 30 images, 20 volunteers rated 600 samples; our method scored highest in image consistency and overall quality, outperforming DreamGaussian [47] and TriplaneGaussian [62].
- Ablation Study: Single-view input leads to poor back-view reconstruction and blurriness; data augmentation improves 3D consistency and camera pose accuracy; higher training resolution (512×512) yields finer details than 256×256.
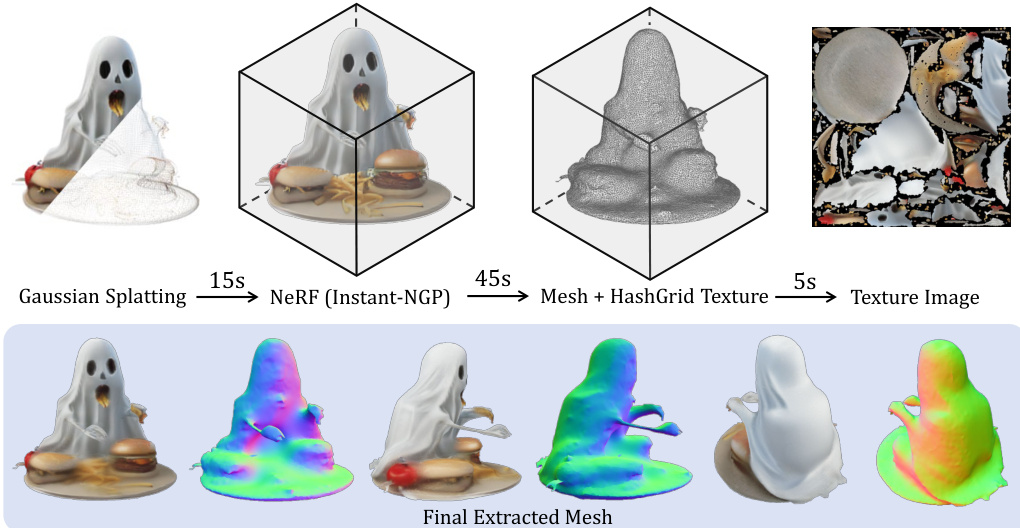
- Meshing: Our meshing method produces smoother surfaces than DreamGaussian [47], independent of underlying Gaussians, and is advantageous for relighting.
- Limitations: Failures mainly stem from low-resolution (256×256) multi-view images, leading to inaccuracies in slender structures and issues with high elevation angles.
Results show that the proposed method, LGM, achieves the highest ratings in both image consistency and overall quality compared to DreamGaussian and TriplaneGaussian. The authors use a user study to evaluate the generated 3D Gaussians, where LGM outperforms the baselines, demonstrating superior alignment with the input image content and better overall model quality.
