Command Palette
Search for a command to run...
GLM-ASR-Nano Intelligent Speech Recognition
1. Tutorial Introduction

GLM-ASR-Nano-2512 is an open-source speech recognition model launched by ZhipuAI in December 2024, with a parameter scale of 1.5 billion (1.5B). Designed specifically for handling complex real-world scenarios, it boasts a small footprint yet outperforms OpenAI Whisper V3 in multiple benchmark tests. This model supports standard Mandarin and English, and demonstrates remarkable robustness in dialect recognition and whispered/low-voice scenarios. As an edge-friendly, high-performance model, it employs advanced training strategies to accurately capture extremely low-volume speech details, filling the gaps in traditional ASR models for dialects and complex acoustic environments. For example, in noisy meeting recordings or privacy-preserving whispered conversations, GLM-ASR-Nano provides extremely accurate transcription results.
This tutorial uses Grado + Transformers to deploy GLM-ASR-Nano-2512 as a demonstration, employing the following computing resources: Single RTX 5090 .
2. Project Examples
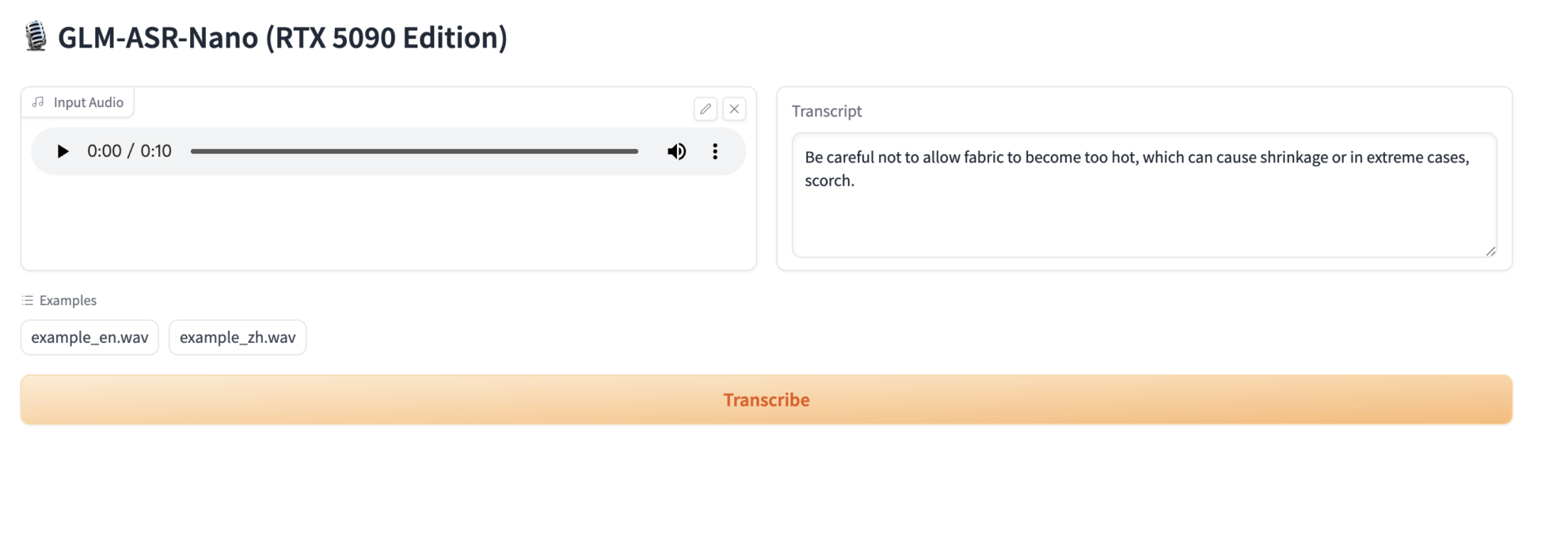
3. Operation steps
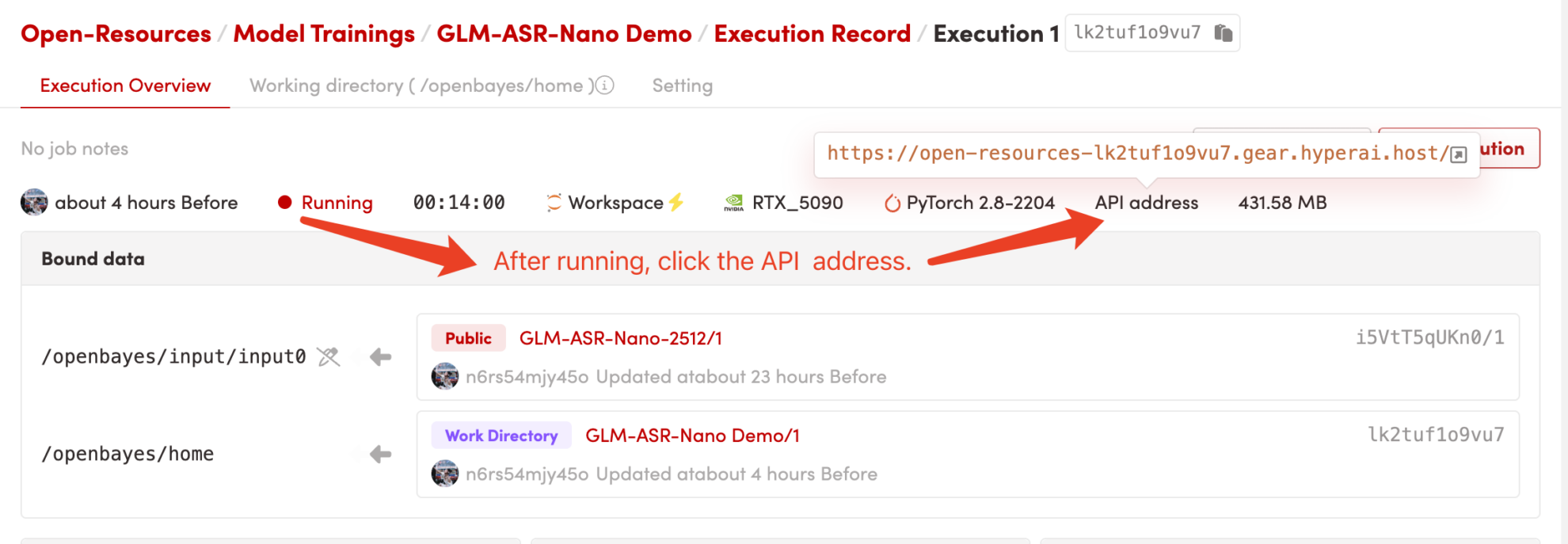
1. After starting the container, click the API address to enter the Web interface
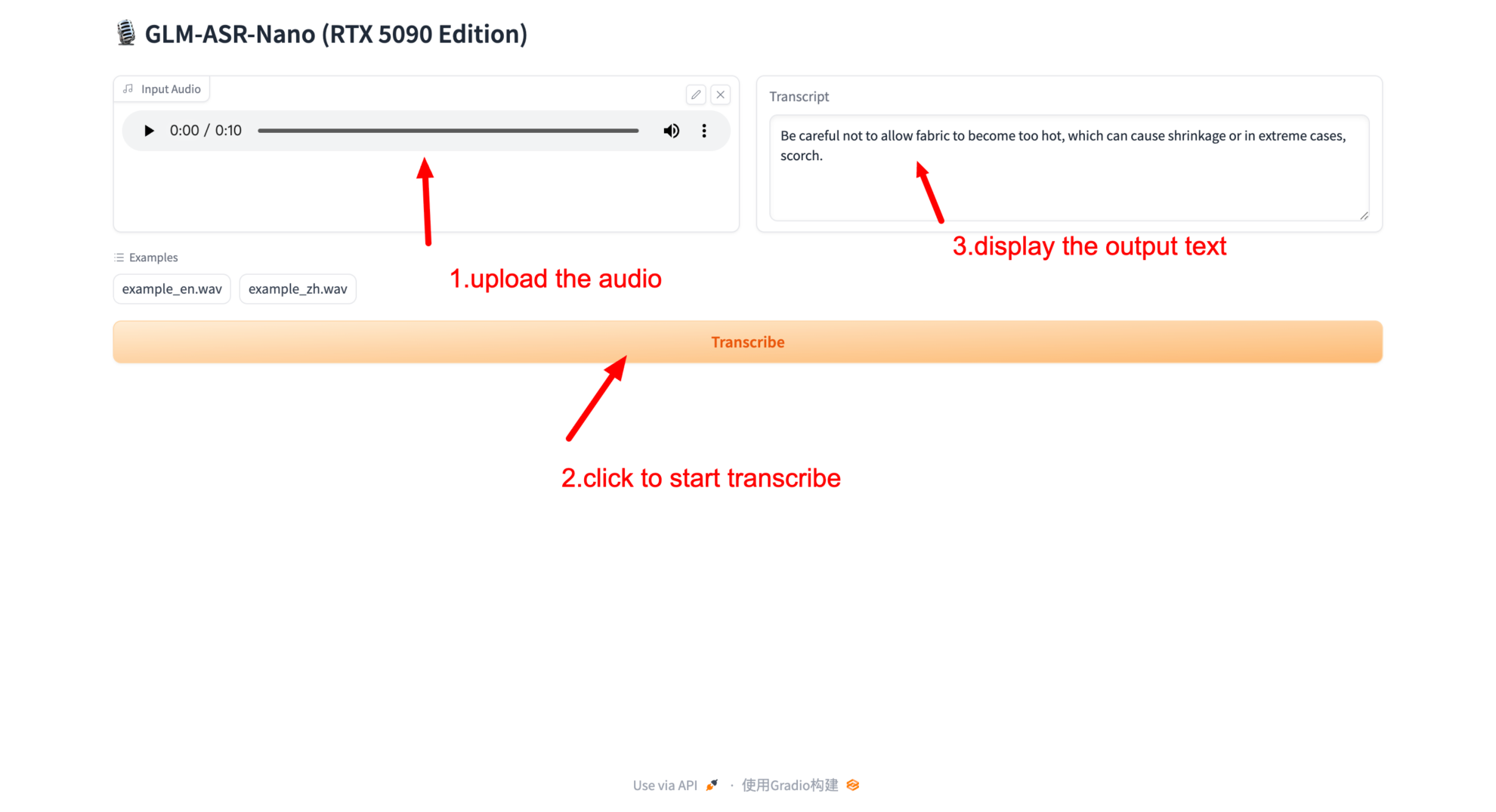
2. Once you access the webpage, you can upload audio or recordings for recognition!
If displayed Bad Gateway This means the model is loading. Please wait about 2-3 minutes and then refresh the page.
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
Citation Information
@misc{glm-asr-nano-2512,
title={GLM-ASR-Nano: A Robust and Compact Speech Recognition Model},
author={ZhipuAI},
year={2024},
publisher={Hugging Face},
url={[https://huggingface.co/zai-org/GLM-ASR-Nano-2512](https://huggingface.co/zai-org/GLM-ASR-Nano-2512)}
}Notebook Overview
Level
Topic
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.