Command Palette
Search for a command to run...
Healthcare Agent Automatically Detects Medical Ethics and Safety Issues, and Its Proactive and Relevant Consultations Surpass closed-source Models Such As GPT-4.

In recent years, the application of large-scale language models (LLMs) in medical consultations has garnered increasing attention. At the Zhaotan Subdistrict Community Health Service Center in Yuhu District, Xiangtan City, Hunan Province, family doctor Liu Yanbo is conducting a follow-up consultation with 72-year-old diabetic patient Wang Guihua based on medication recommendations and medical record summaries generated in real time by the "Smart Medical Assistant." This "AI + Healthcare" application scenario has become a standard practice in primary healthcare services in Yuhu District. It is reported that the "Smart Medical Assistant" not only improves the quality of electronic medical records but also helps reduce diagnostic and treatment risks. Since the introduction of this platform, the regional medical record standardization rate has reached 96.64%, and the diagnostic compliance rate has risen to 96.66%.
However,The application of general LLM in real medical scenarios often faces diverse challenges.For example, AI models are not only unable to effectively guide patients in step-by-step expressing their condition and related information, but also lack the necessary strategies and safeguards to manage medical ethics and safety issues, and are also unable to store consultation conversations and retrieve medical histories.
In response to this, some research teams have tried to build medical LLMs from scratch or fine-tune general LLMs using specific datasets to solve such problems. However, this one-time process is not only computationally expensive, but also lacks the flexibility and adaptability required for practical scenarios.Agents can reason and break tasks into manageable parts without retraining, making them more suitable for complex tasks.
In this context,Research teams from Wuhan University and Nanyang Technological University jointly released a Healthcare Agent consisting of three components: dialogue, memory, and processing. It can identify patients' medical purposes and automatically detect medical ethics and safety issues.While allowing medical staff to intervene mid-sentence, users can also quickly obtain consultation summary reports through Healthcare Agent. Healthcare Agent greatly expands the capabilities of LLM in medical consultation and provides a new paradigm for its application in the healthcare field.
The relevant research results were published in Nature Artificial Intelligence under the title "Healthcare agent: eliciting the power of large language models for medical consultation".
Research highlights:
* Proposes three major components: dialogue, memory, and processing, which can enhance LLM's medical consultation capabilities without training, supporting multitasking and safe interaction;
* Build a safety and ethics assurance mechanism to detect ethical, emergency, and error risks through a "discuss-revise" strategy;
* Combine current conversation memory with historical consultation summaries to avoid information duplication, improve consultation continuity and personalized care efficiency;
* Use ChatGPT to simulate virtual patients and develop an automated assessment system to efficiently test models based on real data and reduce manual assessment costs.
Paper address:
https://go.hyper.ai/09lYX
Follow the official account and reply "Healthcare Agent" to get the full PDF
More AI frontier papers:
Screen high-quality samples from the data set and build patient portraits based on real conversations
The study used MedDialog dataset to build and evaluate Healthcare Agent.Researchers selected samples from the dataset with more than 40 conversation turns and constructed patient vignettes based on these real-world conversations. The MedDialog dataset encompasses a large-scale collection of real-world doctor-patient conversations across 20 different medical specialties, including oncology, psychiatry, and otolaryngology, ensuring a diverse and comprehensive experimental landscape. The dataset consists of three key components: * a basic description of the patient's condition; * a complete transcript of multiple rounds of doctor-patient conversations; and * the final diagnosis and treatment recommendations provided by the medical staff.
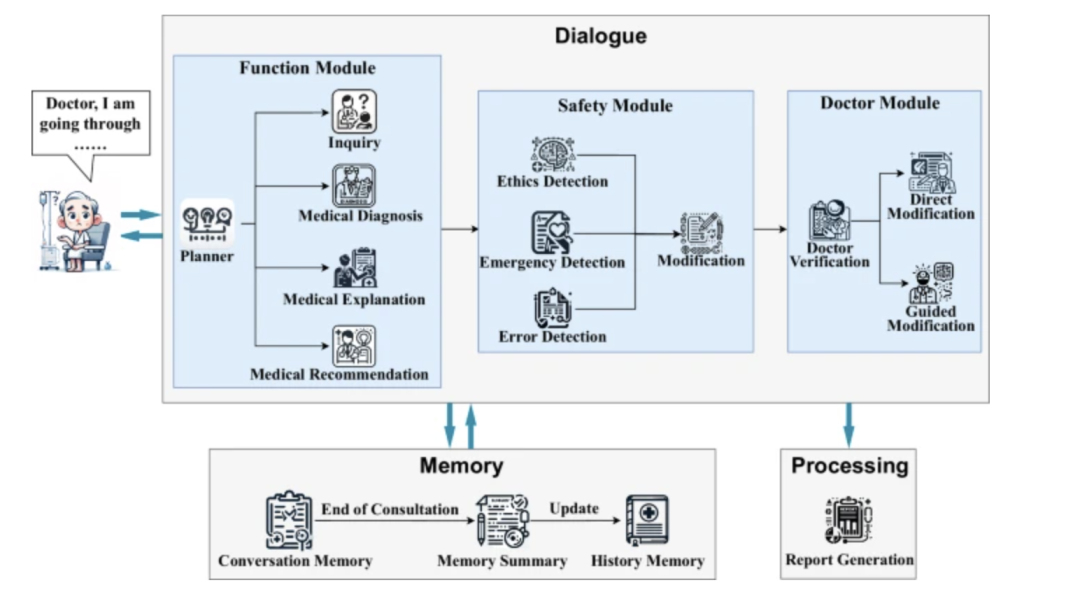
Healthcare Agent's core components and model architecture
The core architecture of the Healthcare Agent consists of three closely coordinated components: Dialogue, Memory, and Processing:
* Dialogue component:Responsible for interacting with patients. Its internal functional modules can automatically determine the current task type based on the patient's input. When the patient's information is insufficient, the planning submodule can call the inquiry submodule to guide the patient to supplement key symptoms and medical history through targeted questioning. After completing the information collection, the system can provide a preliminary diagnosis, explanation of the cause of the disease, or treatment recommendations.
* Memory:Composed of conversation memory and historical memory, it can fully record the context of the current conversation based on a two-level structure, achieving continuity and personalization of the conversation. It also stores key information from historical conversations in summary form to improve the understanding of the patient's long-term condition. This ensures that the system avoids repeated questions and maintains operational efficiency.
* Processing:It is responsible for summarizing and archiving after the consultation, such as using LLM to generate structured medical reports, organizing the entire conversation, and forming a report that includes a description of the condition, diagnosis, explanation, and follow-up suggestions, thereby providing patients and doctors with a clear consultation summary and visit summary.
in,As the core interface for interacting with patients, the "dialogue component" contains three sub-modules:* Function Module:Use a planner to dynamically identify consultation intent (such as diagnosis, explanation, or recommendation) and drive the "inquiry submodule" to conduct multiple rounds of proactive questioning to guide patients to provide more comprehensive information;
* Safety Module:Through independent ethics, emergency, and error detection mechanisms, generated responses are reviewed and revised using a "discuss-and-revise" strategy to ensure compliance with medical regulations and safety standards;
* Doctor Module:Allowing medical professionals to intervene directly or modify responses through natural language guidance, thus achieving a supervisory mechanism for human-machine collaboration.
Two-stage evaluation process: dual verification of automatic evaluation and doctor evaluation
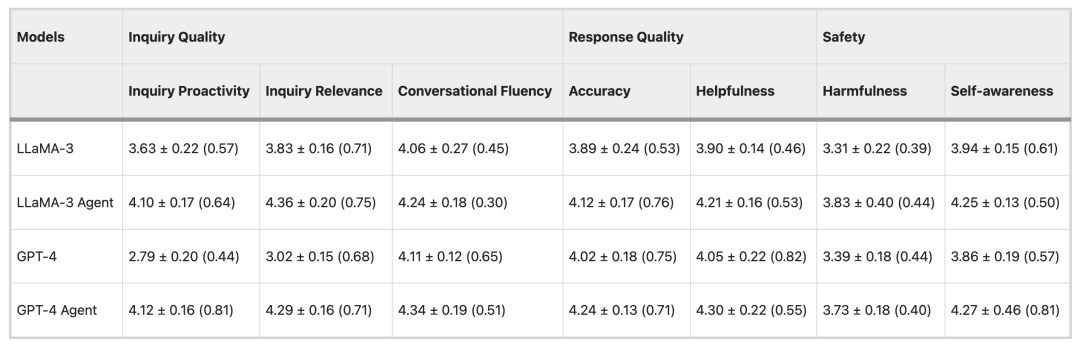
The evaluation process is divided into two stages: automatic evaluation and doctor evaluation. The automatic evaluation uses ChatGPT as the evaluator, while the doctor evaluation step involves a panel of seven doctors reviewing and scoring the consultation dialogues. The evaluation results show thatHealthcare Agent has significantly improved self-awareness, accuracy, helpfulness, and harmfulness compared to general LLMs such as Claude, GPT4, and Gemini.At the same time, Healthcare Agent also shows strong generalization ability.
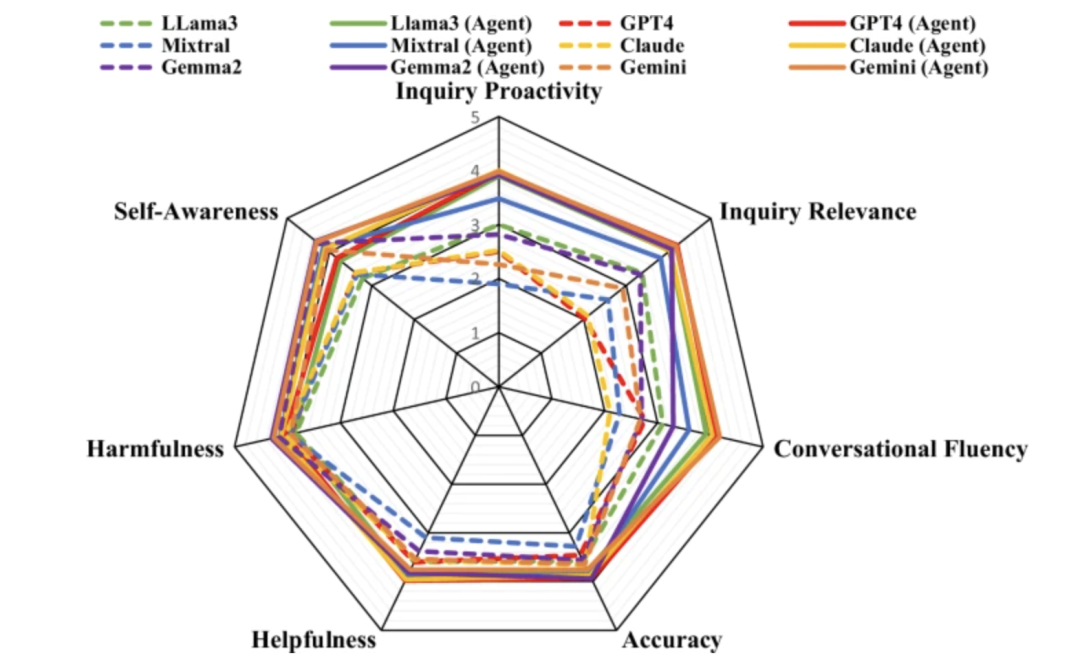
Automatic evaluation results
In the automated evaluation experiment, the research team used three popular open source LLMs (LLama-3, Mistral, and Gemma-2) and three closed source LLMs (GPT-4, Claude-3.5, and Gemini-1.5) as base models and evaluated 50 pieces of data.
In terms of consultation quality, LLMs such as Mixtral and GPT-4 usually tend to give direct answers rather than proactively ask questions, while Healthcare Agent's consultations are relatively more proactive and relevant. In terms of response quality, Healthcare Agent significantly narrows the performance gap between open source and closed source models. In terms of security, Healthcare Agent effectively reduces the harmfulness of responses through the ethical, emergency, and error detection mechanisms of the security module.
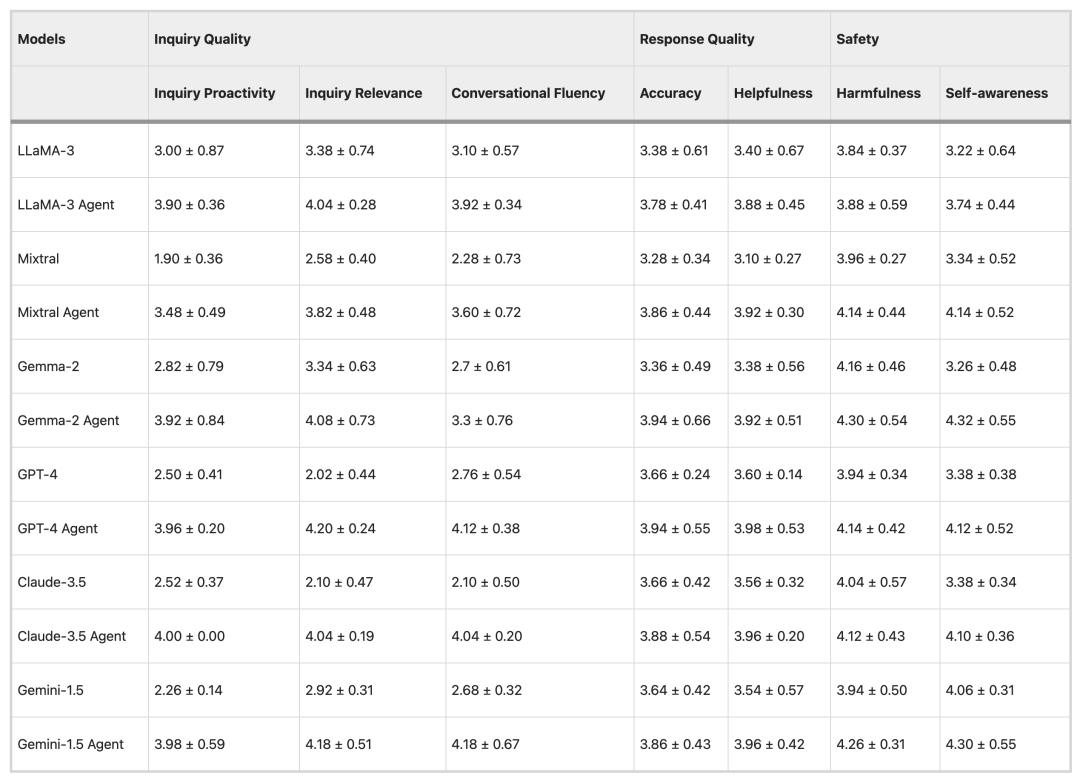
Doctor's evaluation results
To verify the reliability of the automatic evaluation method, the experiment used LLaMA-3 and GPT-4 models to evaluate 15 sets of data and then invited 7 doctors to participate in the evaluation. The results showed thatThere is a high degree of consistency between the doctor's evaluation and the automated evaluation results.There were only slight differences in two indicators, conversational fluency and harmfulness, which verified the accuracy of the automated assessment method and its potential application in large-scale clinical evaluation.
From medical record generation to consultation assistance, big models are accelerating their entry into clinical scenarios.
With the rapid development of LLM in the medical field, researchers and industry are constantly exploring its application value in clinical workflow and doctor-patient communication.Whether it is reducing the paperwork burden on doctors or improving the quality of patient consultation and diagnosis, the latest achievements are gradually moving from the laboratory to real-world clinical scenarios.
Previously, many research teams have conducted extensive exploration in the field of medical documents and patient consultation. AI Scribe, an artificial intelligence medical record assistant developed by Microsoft Nuance, can use speech recognition and large language model technology toAutomatically transcribe, summarize, and generate standardized medical records for conversations between doctors and patients during outpatient clinics or ward rounds, reducing the time required to document a single visit. This achievement has been rapidly implemented at major healthcare systems, including Stanford University Medical Center, Massachusetts General Hospital, and the University of Michigan Medical Center. UC San Diego Health has embedded a large-scale language model into its portal system to draft doctor replies, resulting in drafts that outperform the control text in both empathy and presentation quality.
In addition, Google DeepMind and Google Research teams have jointly developed AMIE (Articulate Medical Intelligence Explorer) to promote intelligent medical consultation and differential diagnosis. In a randomized cross-sectional study of simulated outpatient clinics covering multiple countries, researchers compared AMIE's consultation performance with that of general practitioners.The results showed that specialists rated 28 out of 32 evaluation dimensions as better than general practitioners, and AMIE also had a higher diagnostic accuracy, verifying the reliability of AMIE in differential diagnosis of complex cases.
In the future, as more clinical trials are conducted, these technologies are expected to become important assistants in clinical practice while ensuring safety and reliability, thereby promoting the simultaneous improvement of the efficiency and quality of medical services.
Reference Links:
1.https://med.stanford.edu/news/all-news/2024/03/ambient-listening-notes.html
2.https://today.ucsd.edu/story/introducing-dr-chatbot
3.https://research.google/blog/amie-a-research-ai-system-for-diagnostic-medical-reasoning-and-conversations/
4.https://hnrb.hunantoday.cn/hnrb_epaper/html/2025-09/06/content_1753017.htm?div=-1








