Command Palette
Search for a command to run...
SeniorTalk Chinese Speech Dataset for Elderly people's Conversations
Date
Size
Publish URL
Paper URL
The SeniorTalk dataset is the world's first Chinese super-elderly conversation speech dataset released by Nankai University and Beijing Zhiyuan Artificial Intelligence Research Institute in March 2025. The related paper results are:SeniorTalk: A Chinese Conversation Dataset with Rich Annotations for Super-Aged SeniorsThe project aims to provide valuable support for in-depth research on voice signals for the elderly and optimization of voice interaction systems for the elderly, and to promote the development of related industries such as equipment adaptation for the elderly, health management, and assistive elderly care robots. This dataset contains 55.53 hours of speech data from 202 very elderly individuals. The data includes multi-dimensional, detailed annotations, including speaker information, conversation transcriptions, timestamps (at both sentence and word levels), and accent labels.
Key Features:
- Wide geographical coverage: Data is collected from 16 provinces and cities, covering different regional accents.
- Natural and real interaction: It adopts spontaneous dialogue between two people, covering topics such as retirement, health, and life, which is close to real communication scenarios.
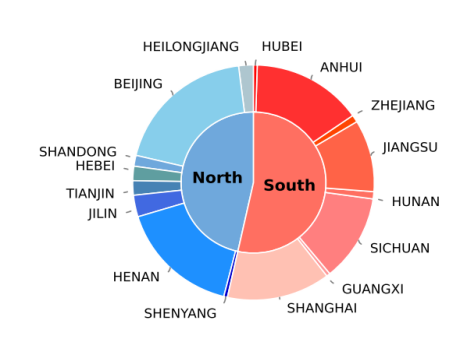
Geographical distribution of the elderly 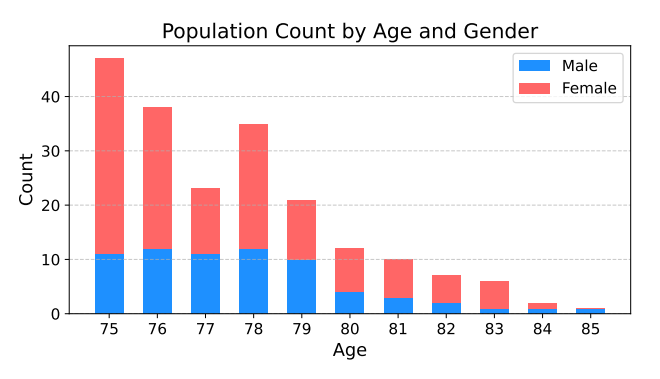
Age and gender statistics of the elderly
Citation
@misc{chen2025seniortalkchineseconversationdataset, title={SeniorTalk: A Chinese Conversation Dataset with Rich Annotations for Super-Aged Seniors}, author={Yang Chen and Hui Wang and Shiyao Wang and Junyang Chen and Jiabei He and Jiaming Zhou and Xi Yang and Yequan Wang and Yonghua Lin and Yong Qin}, year={2025}, eprint={2503.16578}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2503.16578}, }
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.