Command Palette
Search for a command to run...
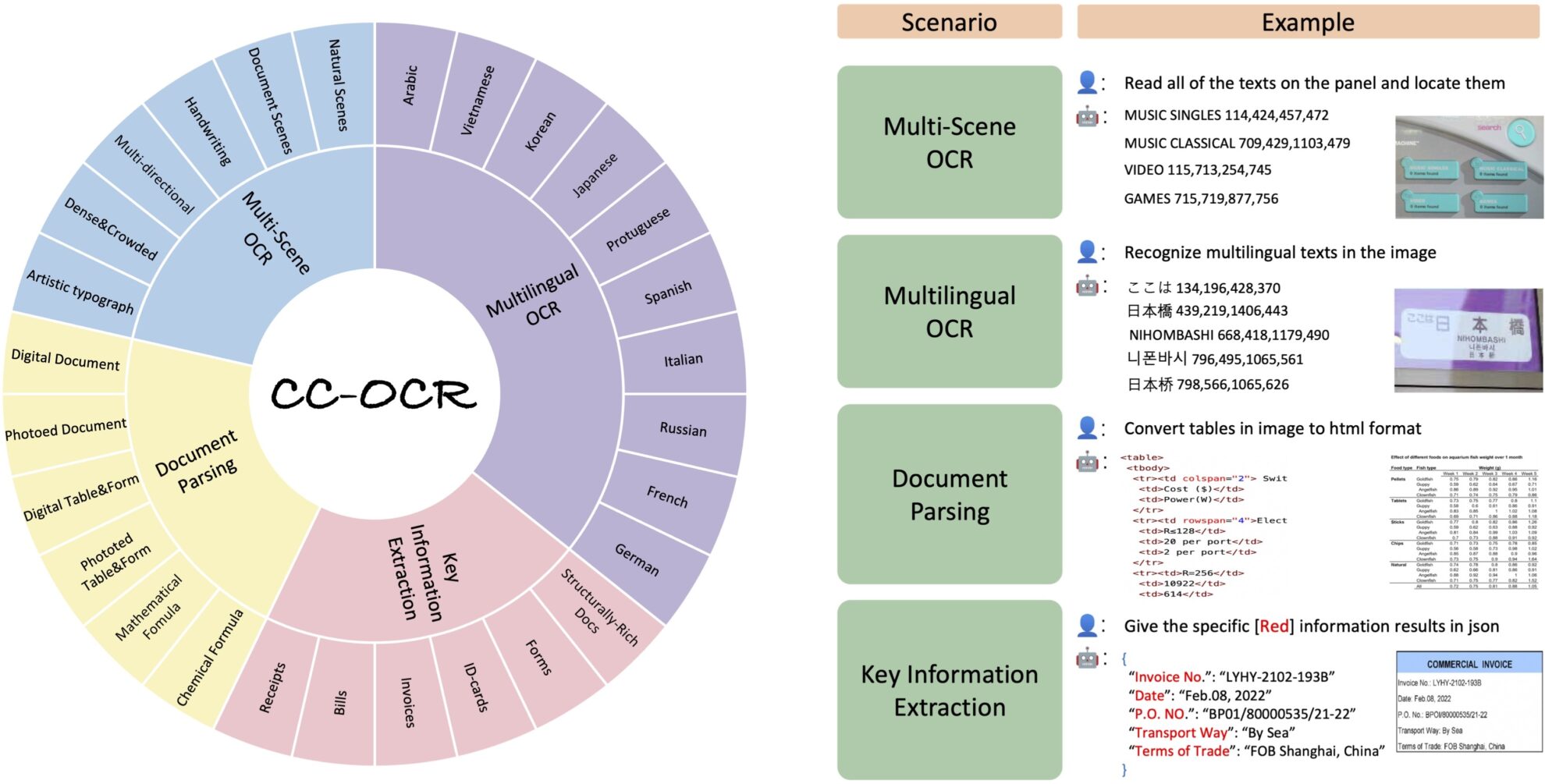
CC-OCR Text Recognition Dataset
The CC-OCR dataset was jointly developed by Alibaba Group, Huazhong University of Science and Technology, and South China University of Technology in 2024 to provide a comprehensive and challenging benchmark for evaluating the performance of large multimodal models in text recognition (OCR) tasks.CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy".
The dataset covers four core tasks: multi-scene text reading, multi-language text reading, document parsing, and key information extraction, and contains 39 subsets and 7,058 fully annotated images. The launch of CC-OCR fills the gap in the evaluation of current multimodal models in terms of complex structures and fine-grained visual challenges, and is of great significance to promoting the progress of multimodal models in practical applications.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.