Command Palette
Search for a command to run...
Mol-Instructions Large-scale Biomolecular Instruction Dataset
Date
Size
Organization
Publish URL
Paper URL
Mol-Instructions is a large-scale biomolecular instruction dataset designed for large language models. It was created by a research team from Zhejiang University in 2024. The related paper results are "Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models", has been accepted by ICLR 2024.
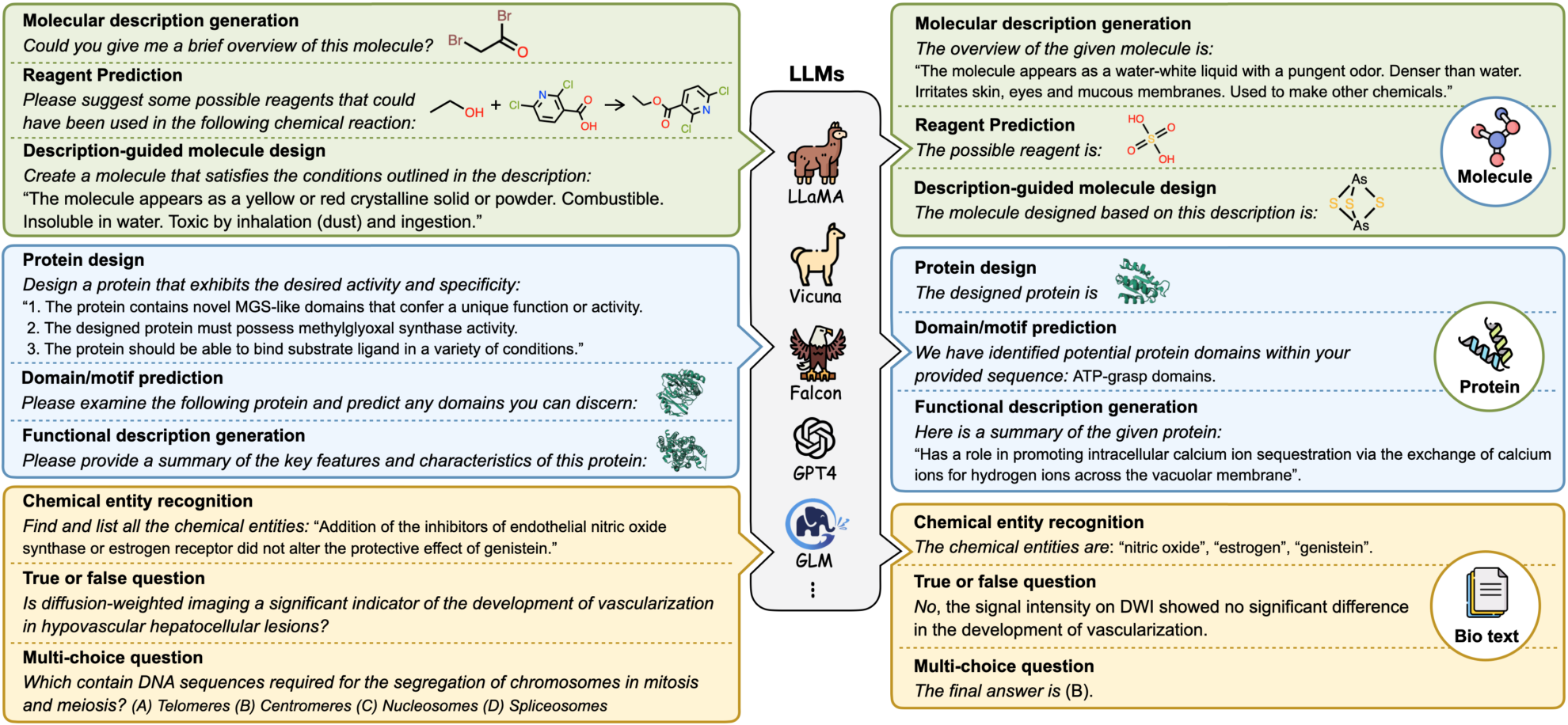
The dataset contains three types of instructions: molecule-oriented instructions, protein-oriented instructions, and biomolecule text instructions. It aims to provide rich instruction data to enhance the understanding and prediction capabilities of large language models in the biomolecule field.
The molecule-oriented instructions contain 148,400 instructions, covering the basic properties and behaviors of small molecules, involving a variety of chemical reactions and molecular design tasks. The protein-oriented instructions contain 505,000 instructions, involving protein structure, function and activity prediction, as well as protein design based on text instructions. The biomolecule text instructions contain 53,000 instructions, mainly used for natural language processing tasks in the fields of bioinformatics and cheminformatics.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.