Command Palette
Search for a command to run...
Persona Hub: A Dataset of 1 Billion Different Personas Automatically Curated From Web Data
Dataset Introduction
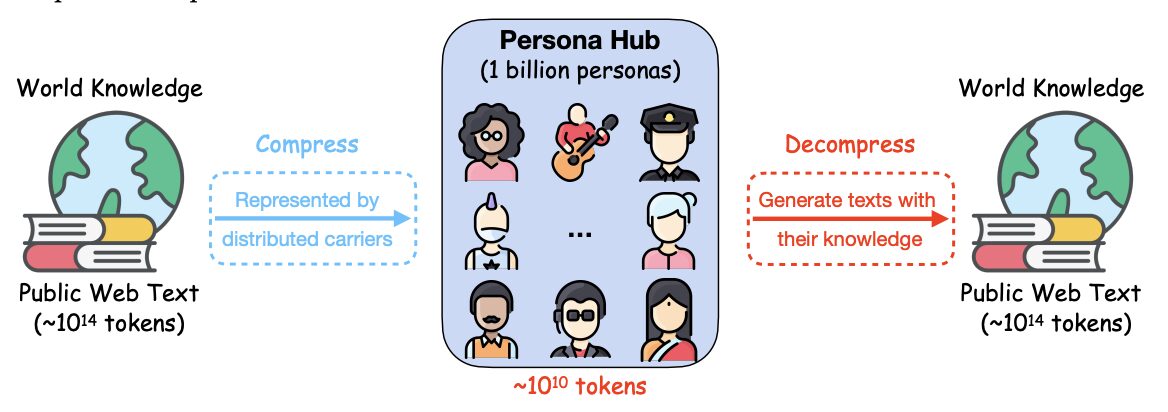
This dataset is a collection of 1 billion different characters automatically organized from web data launched by Tencent Seattle AI Lab in 2024. These 1 billion characters (about 13% of the world's total population) as distributed carriers of world knowledge can leverage almost all perspectives encapsulated in LLM, thereby facilitating the large-scale creation of diverse synthetic data for various scenarios. By demonstrating the use cases of PERSONA HUB in large-scale synthesis of high-quality mathematical and logical reasoning problems, instructions (i.e. user prompts), knowledge-rich texts, game NPCs, and tools (functions), the research team demonstrated that character-driven data synthesis is versatile, scalable, flexible, and easy to use, and has the potential to drive a paradigm shift in synthetic data creation and practical applications, which may have a profound impact on the research and development of LLM. The relevant paper isScaling Synthetic Data Creation with 1,000,000,000 Personas"
Dataset background
Tencent Seattle AI Lab has introduced a novel, persona-driven data synthesis approach that leverages multiple perspectives in large language models (LLMs) to create diverse synthetic data. The researchers introduced a system called "Persona Hub" that automatically curates 1 billion different personas (about 13% of the world's total population) from web data. These personas, as distributed carriers of world knowledge, are able to touch almost all perspectives contained in LLMs, thereby facilitating the creation of diverse synthetic data at scale for a variety of scenarios. This technical report also discusses the broad implications and ethical issues that may arise from the use of Persona Hub, such as data security, threats to the leading position of existing LLMs, and the possibility of simulating real society in virtual worlds.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.