Command Palette
Search for a command to run...
VisA Industrial Visual Anomaly Detection Dataset
Date
Size
Publish URL
Paper URL
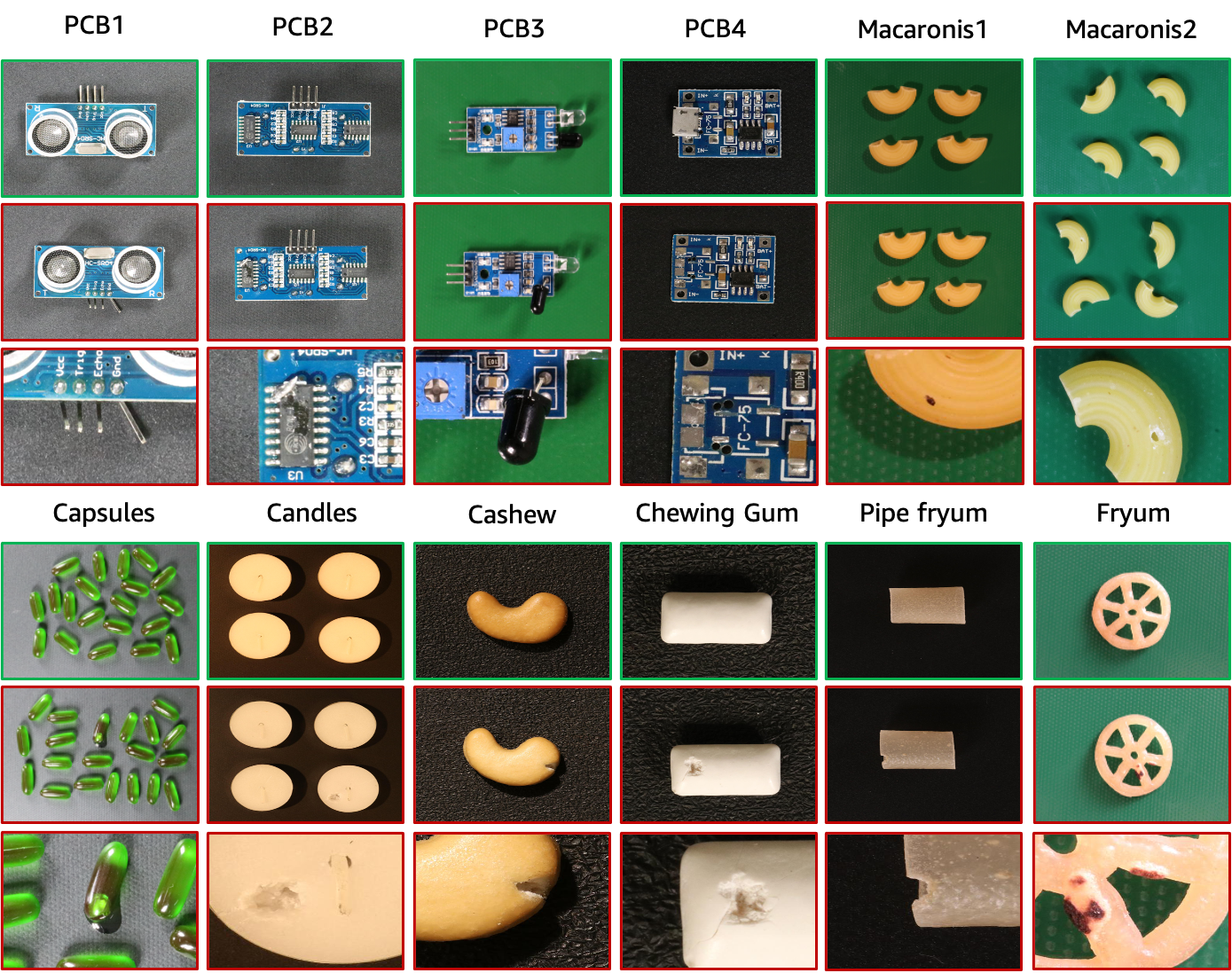
**The VisA dataset is a SPot-the-Difference self-supervised pre-training dataset for anomaly detection and segmentation.**It contains 12 subsets, corresponding to 12 different objects, as shown in the figure. There are 10,821 images, including 9,621 normal samples and 1,200 abnormal samples. The four subsets are different types of printed circuit boards (PCBs), whose structures are relatively complex, including transistors, capacitors, chips, etc. For the case of multiple instances in the view, we collect four subsets: Capsules, Candles, Macaroni1, and Macaroni2. The instances in Capsules and Macaroni2 are very different in position and pose. In addition, the research team also collected four subsets, including cashews, chewing gum, French fries, and pipe fries, in which the objects are roughly aligned. Abnormal images contain various defects, including surface defects such as scratches, dents, color spots, or cracks, as well as structural defects such as misplaced or missing parts.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.