Command Palette
Search for a command to run...
COIG-CQIA High-quality Chinese Instruction fine-tuning Dataset
Date
Size
Organization
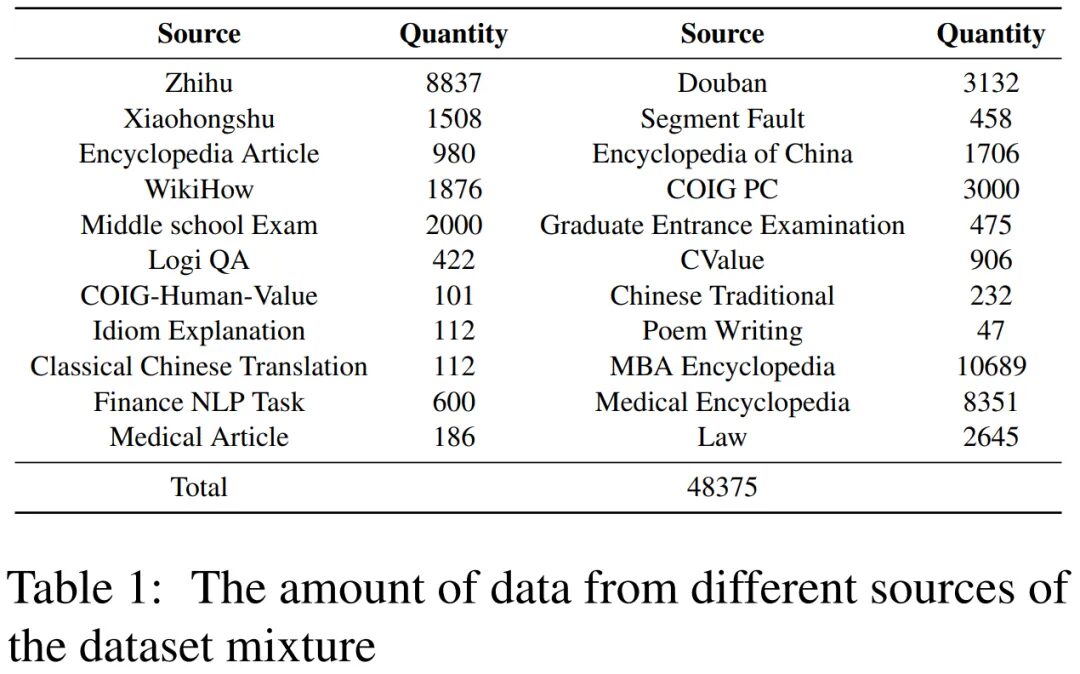
COIG-CQIA stands for Chinese Open Instruction Generalist – Quality is All You Need. It is an open source high-quality instruction fine-tuning dataset.Aims to provide the Chinese NLP community with high-quality instruction fine-tuning data that is consistent with human interaction behavior. COIG-CQIA uses questions and answers and articles obtained from the Chinese Internet as raw data, and is constructed after deep cleaning, reconstruction, and manual review. This project is inspired by studies such as LIMA: Less Is More for Alignment. Using a small amount of high-quality data, a large language model can learn human interaction behaviors. Therefore, in the data construction, great attention is paid to the source, quality and diversity of the data. For details of the dataset, please see the data introduction and the research team's paper. Data Collection
- The research team collected a lot of manually written text data from multiple sources on the Chinese Internet to ensure the diversity and richness of the data.
- The sources of data include not only question-and-answer communities (such as Zhihu, Sifou, Douban, Xiaohongshu, and Chiba), but also wiki-like knowledge platforms (such as Baidu Encyclopedia), various types of examination materials (such as middle and high school entrance examination questions, professional qualification examination questions), and existing NLP datasets.
- When collecting data, we focus on selecting relevant data that can reflect the real interaction patterns of Chinese users to enhance the model's understanding of real-world language usage.
Citation
@misc{bai2024coig,
title={COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning},
author={Bai, Yuelin and Du, Xinrun and Liang, Yiming and Jin, Yonggang and Liu, Ziqiang and Zhou, Junting and Zheng, Tianyu and Zhang, Xincheng and Ma, Nuo and Wang, Zekun and others},
year={2024},
eprint={2403.18058},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.