HyperAI
Command Palette
Search for a command to run...
Firefly Chinese Llama2 Incremental pre-training Dataset
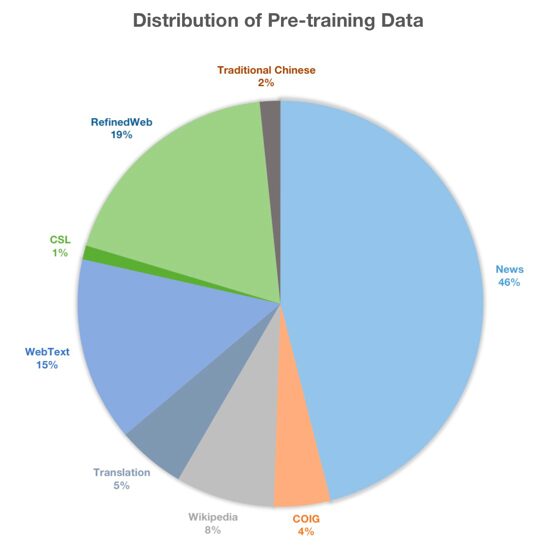
The dataset is Firefly-LLaMA2-Chinese project The incremental pre-training data totals about 22GB of text, mainly including open source data sets such as CLUE, ThucNews, CNews, COIG, Wikipedia, and ancient poems, prose, classical Chinese, etc. collected by the research team. The data distribution is shown in the figure below.
firefly-pretrain-dataset.torrent
Seeding 1Downloading 0Completed 169Total Downloads 278
This dataset is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at [email protected] for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
AI Co-coding
Ready-to-use GPUs
Best Pricing
HyperAI Newsletters
Subscribe to our latest updates
We will deliver the latest updates of the week to your inbox at nine o'clock every Monday morning
Powered by MailChimp