Command Palette
Search for a command to run...
VoxCeleb2 Speech Recognition Dataset
Date
Size
Publish URL
Paper URL
License
CC BY 4.0
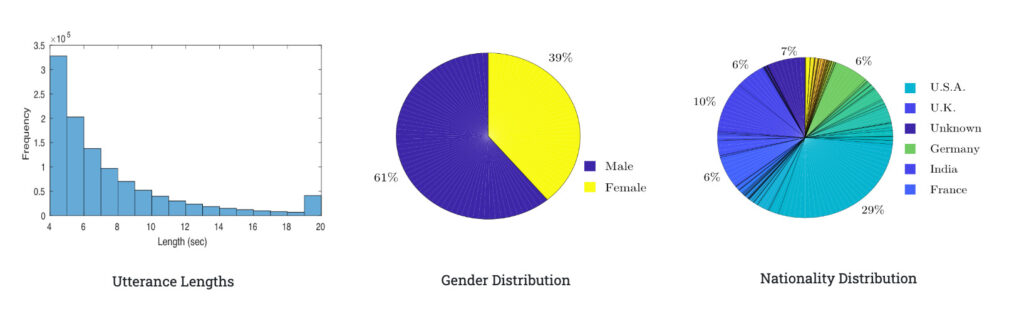
VoxCeleb2 is a large-scale speaker recognition dataset derived from open source media, consisting of one million corpora from more than 6,000 speakers. Since the dataset is collected in natural scenes, there is no lack of interference in the voice clips, such as laughter, conversation, channel effects, music, etc.
The corpus in VoxCeleb2 is multilingual, with speakers from 145 countries, covering a wide range of accents, ages, races, and languages. The dataset includes both audio and video, and is also suitable for solving problems such as visual speech synthesis, speech separation, face-voice cross-modal conversion, and video face recognition.
Dataset details:
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.