Command Palette
Search for a command to run...
Nanonets-OCR-s: Tool Zur Extraktion Von Dokumentinformationen Und Zum Benchmarking
1. Einführung in das Tutorial

Nanonets-OCR-s ist ein Modell zur optischen Zeichenerkennung (OCR), das am 10. Juni 2025 von Nanonets veröffentlicht wurde. Herkömmliche OCR-Technologie konzentriert sich hauptsächlich auf die Extraktion von Klartext aus Bildern, während Nanonets-OCR-s einen Schritt weiter geht. Es kann mehrere Elemente in Dokumenten erkennen, wie mathematische Formeln, Bilder, Signaturen, Wasserzeichen, Kontrollkästchen und Tabellen, und diese in einem strukturierten Markdown-Format organisieren. Diese Fähigkeit ermöglicht eine hohe Leistung bei der Verarbeitung komplexer Dokumente wie akademischer Arbeiten, juristischer Dokumente oder Geschäftsberichte. Die Ergebnisse sind nicht nur für Menschen leicht lesbar, sondern bieten auch eine solide Grundlage für die nachfolgende automatisierte Verarbeitung.
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource. Es enthält zwei Funktionen: 1. Informationen aus Dokumenten extrahieren. 2. Bilder und PDFs in Markdown konvertieren.
2. Projektbeispiele
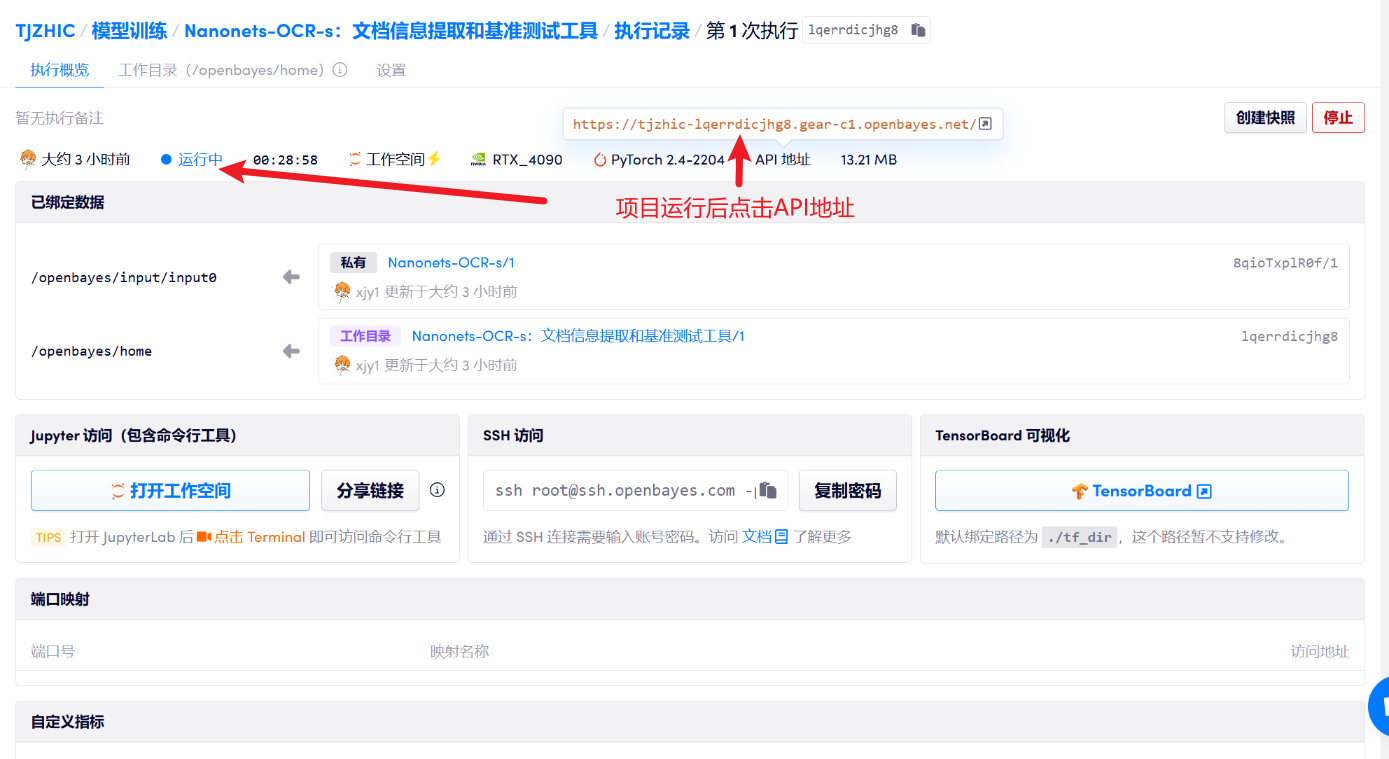
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
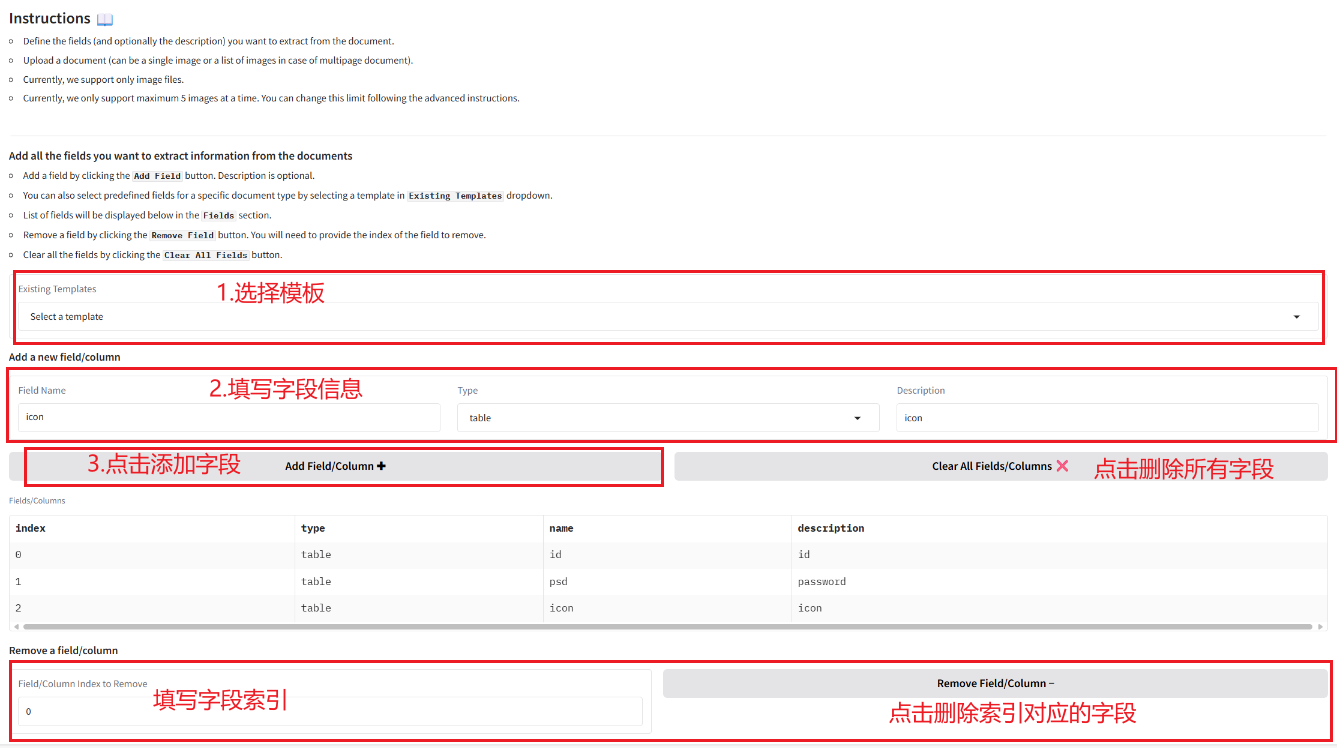
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
2.1 Informationen aus Dokumenten extrahieren
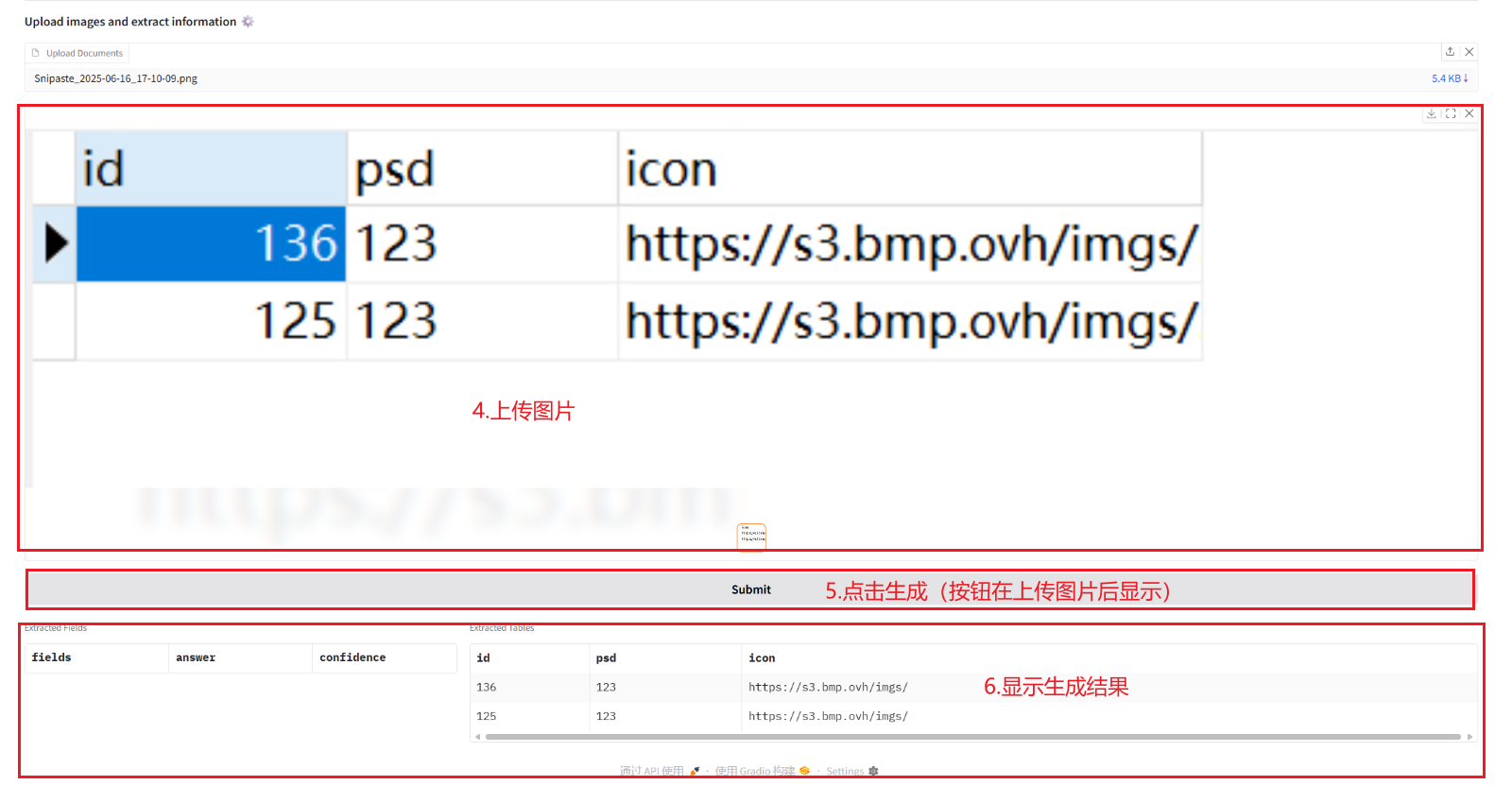
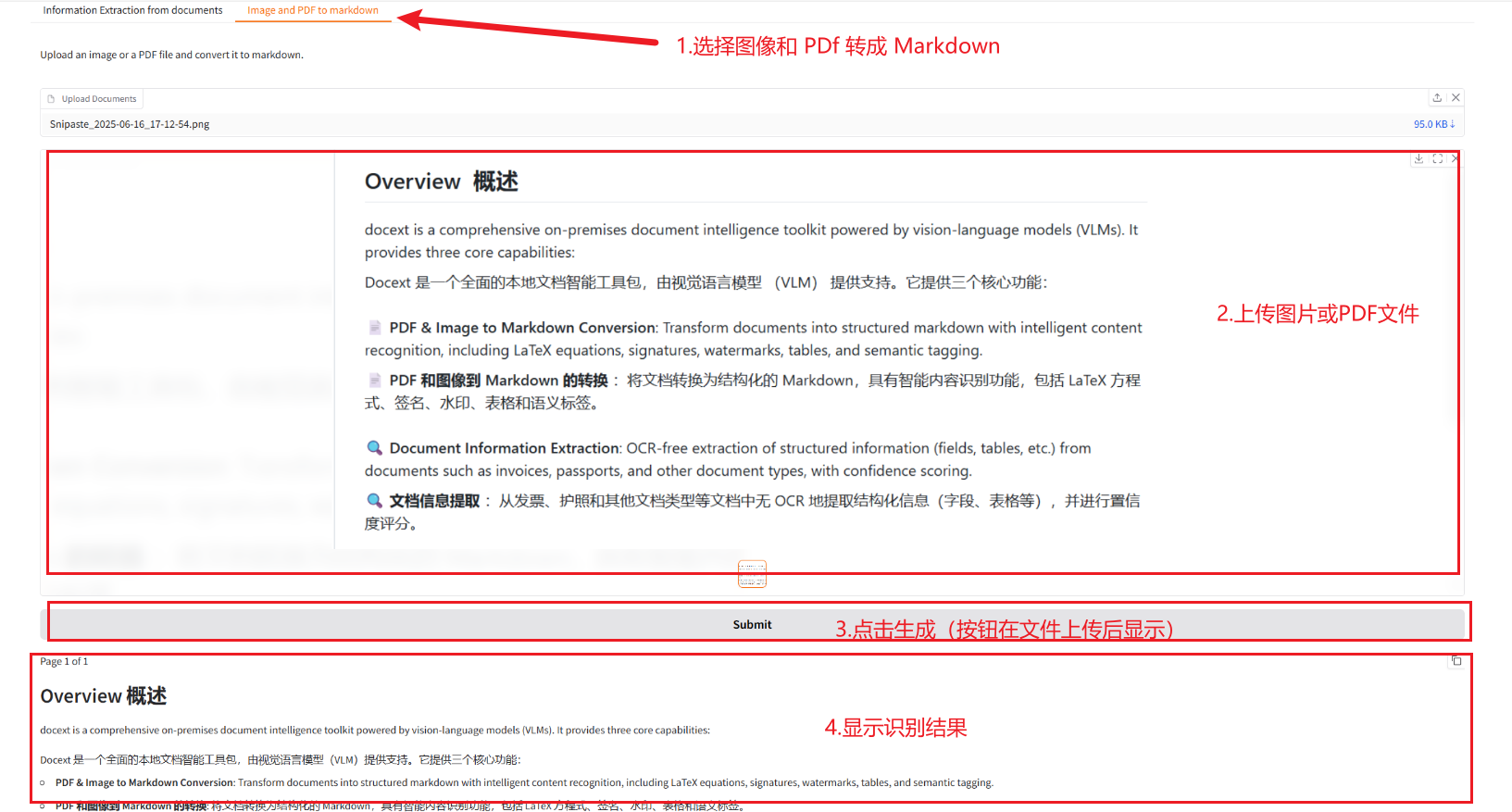
2.2 Bilder und PDF in Markdown konvertieren
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.