Command Palette
Search for a command to run...
Ein-Klick-Bereitstellung Von YOLOv12
1. Einführung in das Tutorial 📖

YOLOv12 wurde 2025 von Forschern der University at Buffalo und der University of Chinese Academy of Sciences ins Leben gerufen. Die zugehörige Forschungsarbeit lautet wie folgt: YOLOv12: Aufmerksamkeitszentrierte Echtzeit-Objektdetektoren .
Die bahnbrechende Leistung von YOLOv12
- YOLOv12-N erreicht einen mAP von 40,6% mit einer Inferenzlatenz von 1,64 Millisekunden auf einer T4-GPU, was 2,1%/1,2% höher ist als YOLOv10-N/YOLOv11-N.
- YOLOv12-S schlägt RT-DETR-R18 / RT-DETRv2-R18, läuft 42% schneller, benötigt nur 36% Rechenzeit und reduziert die Parameter um 45%.
📜 YOLO-Entwicklungsgeschichte und zugehörige Tutorials
YOLO (You Only Look Once) ist seit seiner Einführung im Jahr 2015 führend in der Objekterkennung und Bildsegmentierung.Nachfolgend finden Sie die Entwicklung der YOLO-Reihe und der zugehörigen Tutorials:
- YOLOv2 (2016): Einführung von Batch-Normalisierung, Ankerboxen und Dimensionsclustering.
- YOLOv3 (2018): Verwendung effizienterer Backbone-Netzwerke, Multi-Anker und räumliches Pyramiden-Pooling.
- YOLOv4 (2020): Einführung der Mosaik-Datenerweiterung, des ankerfreien Erkennungskopfes und der neuen Verlustfunktion. → Anleitung:DeepSOCIAL realisiert Crowd Distance Monitoring basierend auf YOLOv4 und sortiert Multi-Target-Tracking
- YOLOv5 (2020): Hyperparameteroptimierung, Experimentverfolgung und automatische Exportfunktionen hinzugefügt. → Anleitung:YOLOv5_deepsort Echtzeit-Multi-Target-Tracking-Modell
- YOLOv6 (2022): Meituan Open Source, wird häufig in autonomen Lieferrobotern verwendet.
- YOLOv7 (2022): Unterstützt die Posenschätzung für den COCO-Keypoint-Datensatz. → Tutorial:So trainieren und verwenden Sie ein benutzerdefiniertes YOLOv7-Modell
- YOLOv8 (2023):Ultralytics veröffentlicht, unterstützt eine breite Palette visueller KI-Aufgaben. → Tutorial:Training von YOLOv8 mit benutzerdefinierten Daten
- YOLOv9 (2024): Einführung in Programmable Gradient Information (PGI) und Generalized Efficient Layer Aggregation Network (GELAN).
- YOLOv10 (2024): Es wurde von der Tsinghua-Universität eingeführt, führt einen End-to-End-Header ein und eliminiert die Anforderung der nicht maximalen Unterdrückung (NMS). → Anleitung:YOLOv10 Echtzeit-End-to-End-Objekterkennung
- YOLOv11(2024): Das neueste Modell von Ultralytics, das Erkennung, Segmentierung, Posenabschätzung, Verfolgung und Klassifizierung unterstützt. → Anleitung:Ein-Klick-Bereitstellung von YOLOv11
- YOLOv12 🚀 NEU (2025): Die doppelten Spitzenwerte bei Geschwindigkeit und Genauigkeit, kombiniert mit den Leistungsvorteilen des Aufmerksamkeitsmechanismus!
Dieses Tutorial verwendet RTX 4090 als Rechenressource.
2. Bedienungsschritte🛠️
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen

Die Ausgabe eines Objektdetektors besteht aus Begrenzungsrahmen, die die Objekte im Bild umschließen, sowie einer Klassenbezeichnung und einem Konfidenzwert für jeden Begrenzungsrahmen. Die Objekterkennung eignet sich gut, wenn Sie Objekte von Interesse in einer Szene identifizieren müssen, deren genaue Position oder Form Sie jedoch nicht kennen müssen.
Es gliedert sich in die folgenden zwei Funktionen:
- Bilderkennung
- Videoerkennung
2. Bilderkennung
Die Eingabe ist ein Bild und die Ausgabe ist ein Bild mit einer Beschriftung.
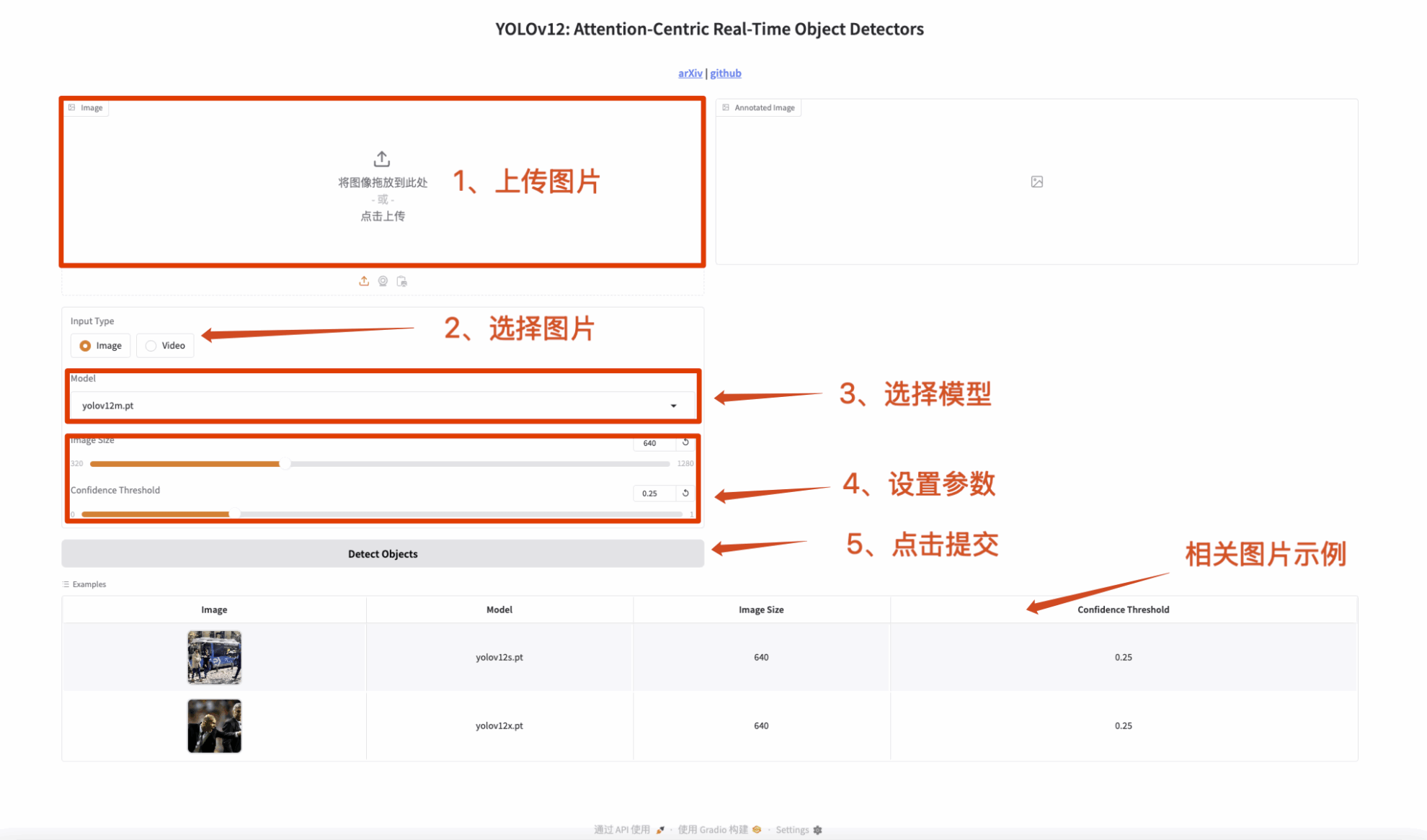

Abbildung 1 Bilderkennung
3. Videoerkennung
Die Eingabe ist ein Video und die Ausgabe ist ein Video mit Beschriftungen.
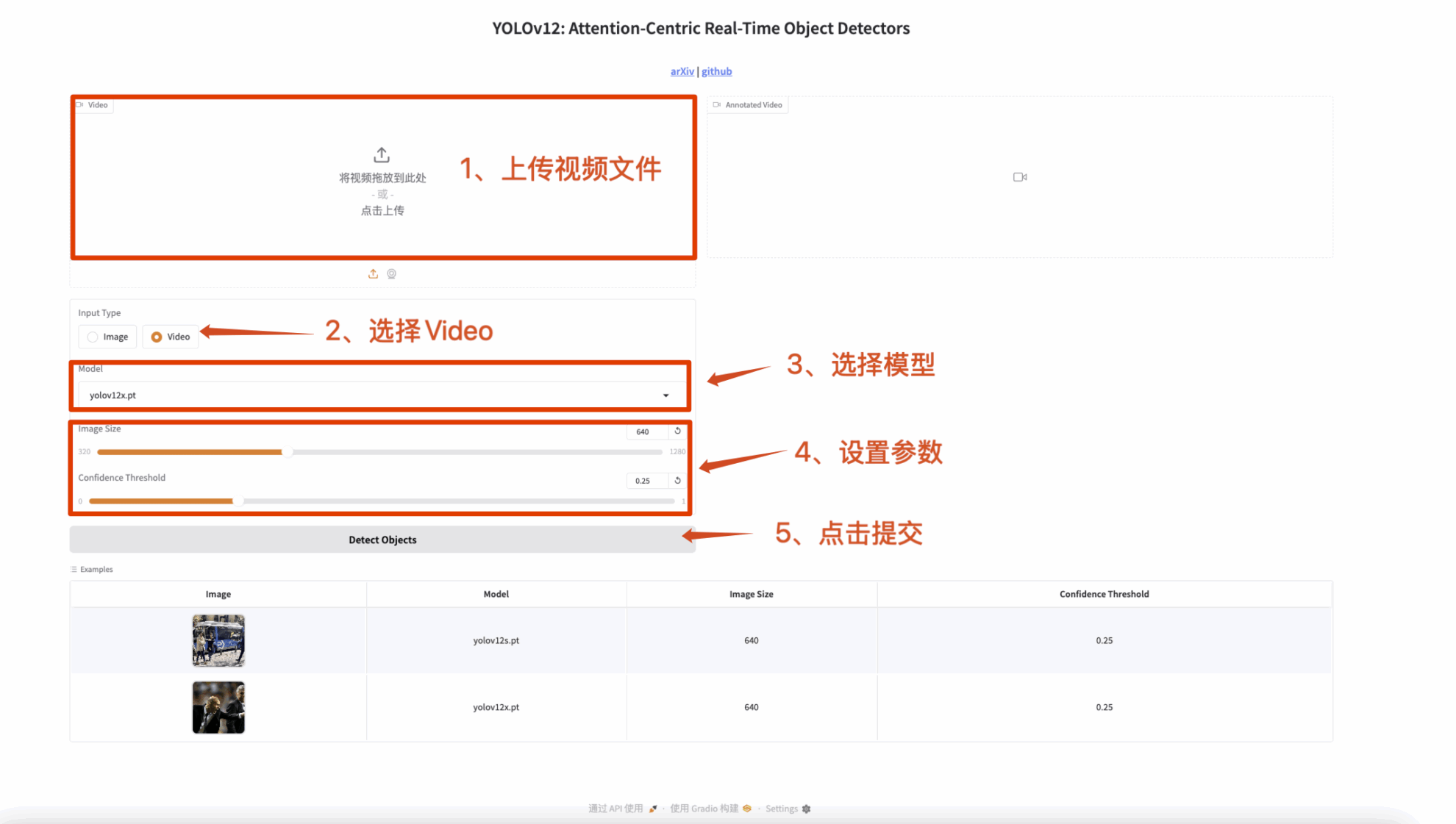
Abbildung 2 Videoerkennung
🤝 Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

YOLOv12 ist nicht nur ein technologischer Sprung, sondern auch eine Revolution im Bereich der Computer Vision! Kommen Sie und erleben Sie es! 🚀
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.