Command Palette
Search for a command to run...
TECHNISCHER BERICHT DER ARCEE TRINITY GROßE
TECHNISCHER BERICHT DER ARCEE TRINITY GROßE
Zusammenfassung
Wir präsentieren den technischen Bericht zu Arcee Trinity Large, einem sparsamen Mixture-of-Experts-Modell mit insgesamt 400 Milliarden Parametern und 13 Milliarden aktivierten Parametern pro Token. Zudem berichten wir über Trinity Nano und Trinity Mini: Trinity Nano verfügt über insgesamt 6 Milliarden Parameter mit 1 Milliarde aktivierten Parametern pro Token, während Trinity Mini insgesamt 26 Milliarden Parameter mit 3 Milliarden aktivierten Parametern pro Token aufweist. Die modernen Architekturmerkmale dieser Modelle umfassen abwechselnden lokalen und globalen Attention, gated Attention, depth-skalierte Sandwich-Norm sowie Sigmoid-Routing für das Mixture-of-Experts-Paradigma. Für Trinity Large führen wir zudem eine neue Load-Balancing-Strategie für MoE ein, die als Soft-clamped Momentum Expert Bias Updates (SMEBU) bezeichnet wird. Die Modelle wurden mit dem Muon-Optimierer trainiert. Alle drei Modelle erreichten den Trainingsabschluss ohne Verlustspitzen. Trinity Nano und Trinity Mini wurden auf 10 Billionen Tokens vortrainiert, während Trinity Large auf 17 Billionen Tokens vortrainiert wurde. Die Modell-Checkpoint-Dateien sind unter https://huggingface.co/arcee-ai verfügbar.
One-sentence Summary
Arcee AI and Prime Intellect present Arcee Trinity Large, a 400B-parameter sparse Mixture-of-Experts model activating 13B parameters per token, trained stably on 17 trillion tokens using the Muon optimizer and a novel Soft-clamped Momentum Expert Bias Updates (SMEBU) load balancing strategy, alongside Trinity Mini (26B total, 3B activated) and Trinity Nano (6B total, 1B activated), both trained on 10 trillion tokens, all featuring interleaved local and global attention, gated attention, depth-scaled sandwich norm, and sigmoid routing, with checkpoints available at https://huggingface.co/arcee-ai.
Key Contributions
- We introduce the Trinity family of open-weight Mixture-of-Experts models—Trinity Large (400B total, 13B active per token), Trinity Mini (26B total, 3B active), and Trinity Nano (6B total, 1B active)—featuring interleaved local/global attention and gated attention to support efficient inference and real-world deployment requirements.
- For Trinity Large, we propose Soft-clamped Momentum Expert Bias Updates (SMEBU), a novel MoE load balancing strategy, and train all models using the Muon optimizer to achieve higher sample efficiency and larger critical batch sizes than AdamW, resulting in stable training with zero loss spikes.
- Trinity Nano and Mini were pre-trained on 10 trillion tokens, Trinity Large on 17 trillion tokens from a mixed curated/synthetic corpus, with all checkpoints released for enterprise use, enabling full data provenance, licensing control, and evaluation across standard benchmarks.
Introduction
The authors leverage sparse Mixture-of-Experts (MoE) architectures and efficient attention mechanisms to build Trinity Large, a 400B-parameter open-weight LLM with only 13B activated per token, designed for scalable inference in real-world enterprise settings. Prior models often struggle with inference efficiency at scale, especially when handling long reasoning chains or large contexts, while also lacking transparency for regulated deployments. Trinity addresses this by combining interleaved local/global attention, gated attention for context comprehension, and the Muon optimizer for training stability and sample efficiency—all while maintaining open weights for auditability and on-premises deployment. Their work also introduces smaller variants (Nano, Mini) as validation steps toward the full-scale model, emphasizing practical scalability and hardware-aware training.
Dataset

-
The authors use two distinct pretraining data mixes curated by DatologyAI: a 10 trillion token mix for Trinity Nano and Mini, and a 20 trillion token mix (from which 17T were sampled) for Trinity Large. Both mixes are split into three phases, with increasing focus on high-quality, domain-specific data like code, math, and STEM over time.
-
The 10T mix reuses the AFM-4.5B dataset and adds substantial math and code content. The 20T mix for Trinity Large includes state-of-the-art programming, STEM, reasoning, and multilingual data targeting 14 languages including Arabic, Mandarin, Spanish, and Hindi.
-
A major component is synthetic data generation: over 8 trillion tokens were created using rephrasing techniques based on BeyondWeb. This includes 6.5T synthetic web tokens (via format/style/content restructuring), 1T multilingual tokens, and 800B synthetic code tokens—all derived from high-quality seed documents and enhanced for diversity and relevance.
-
The curation pipeline runs on scalable infrastructure using Ray and vLLM on Kubernetes, enabling efficient generation across heterogeneous GPU clusters.
-
Data is processed in three phases with shifting mixtures: later phases boost math and code content and prioritize higher-quality, more relevant data within each category. Tokenization is done on the fly with sequence packing, and documents are buffered to support efficient batching.
-
For Trinity Large, the authors introduce the Random Sequential Document Buffer (RSDB) during phase 3 to reduce intra-batch correlation caused by long documents. RSDB randomly samples from a buffer of tokenized documents, improving IID sampling and reducing batch heterogeneity without dropping tokens.
-
RSDB uses a buffer size of 8192 per GPU (with 4 workers), refilled efficiently to maintain performance. It cuts BatchHet by 4.23x and step-to-step loss variance by 2.4x compared to sequential packing, leading to more stable training and reduced gradient noise.
-
The authors measure batch imbalance via BatchHet—a metric capturing the difference between max and mean microbatch loss per step—and show RSDB significantly improves training stability, even outperforming larger batch baselines in loss variance control.
Method
The authors leverage a decoder-only sparse Mixture-of-Experts (MoE) transformer architecture, designed for efficient scaling and stable training across three model sizes: Trinity Nano, Mini, and Large. The core framework integrates interleaved local and global attention, gated attention, depth-scaled sandwich normalization, and sigmoid-based MoE routing. Each transformer layer follows a consistent pattern: input normalization, sublayer computation (attention or MoE), and output normalization, with residual connections throughout.
Refer to the framework diagram for a visual representation of the layer structure. The attention module begins with RMSNorm applied to the input, followed by linear projections for queries, keys, and values. QK-normalization is applied to stabilize attention logits, particularly under the Muon optimizer. Grouped-query attention (GQA) is employed to reduce KV-cache memory, mapping multiple query heads to a single key/value head via j(i)=⌊i⋅hqhkv⌋. Local layers use sliding window attention with rotary positional embeddings (RoPE), while global layers omit positional embeddings (NoPE), following a 3:1 local-to-global layer ratio. Gated attention is applied post-attention, using a sigmoid gate gt=σ(WGxt) to modulate the attention output before the final linear projection, improving long-context generalization and reducing training instability.
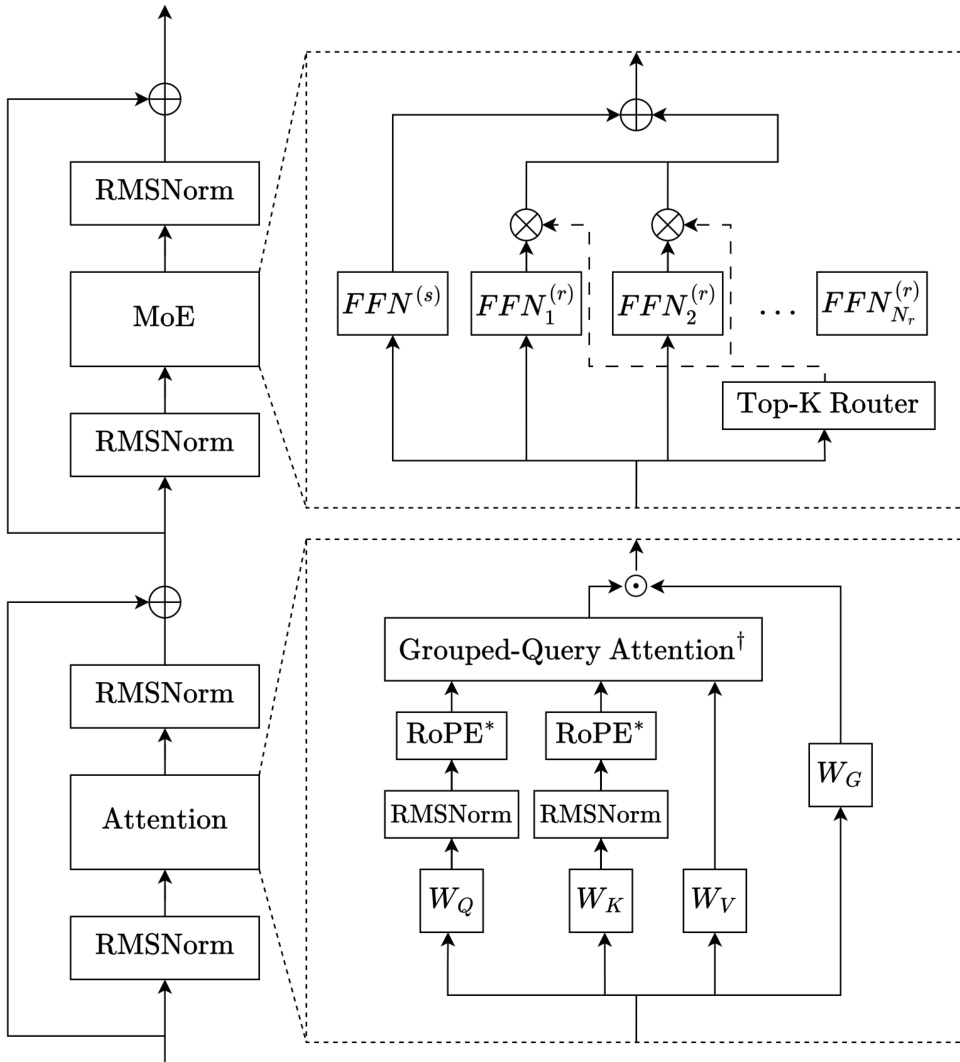
The MoE module follows the DeepSeekMoE design, incorporating one always-active shared expert and multiple routed experts, with SwiGLU as the activation function. The router computes sigmoid scores si,t=σ(ut⊤ei), which are normalized and combined with expert biases bi to select the Top-K experts. Gating scores gi,t are derived from the router scores without bias, ensuring decoupled expert bias updates. For Trinity Mini and Nano, load balancing is achieved via auxiliary-loss-free updates with re-centered expert biases. For Trinity Large, the authors introduce Soft-clamped Momentum Expert Bias Updates (SMEBU), replacing the sign-based update with a tanh-scaled, momentum-smoothed variant to stabilize convergence. The normalized violation vi=nˉnˉ−ni is soft-clamped via v~i=tanh(κvi), and momentum is applied to dampen oscillations near convergence.
Normalization is handled via depth-scaled sandwich RMSNorm: both input and output of each sublayer are normalized, with the second RMSNorm’s gain scaled by 1/L, where L is the total layer count. The final layer applies RMSNorm before the language modeling head. Initialization follows a zero-mean truncated normal distribution with σ=0.5/d, and embedding activations are scaled by d during the forward pass to match established practices in high-performance LLMs.
Experiment
Trinity models were trained on GPU clusters using customized frameworks like TorchTitan and Liger Kernels, with infrastructure optimized for H200 and B300 systems, employing FSDP, EP, and context parallelism for scalability and fault tolerance. Hyperparameters were tuned per model size using Muon and AdamW optimizers, with context extension validated via MK-NIAH benchmarks, where Trinity Large achieved 0.994 at 256K and 0.976 at 512K despite not being trained at the latter length. Post-training included supervised fine-tuning and brief RL with prime-rl, yielding Trinity Large Preview, which showed competitive performance on MMLU, GPQA Diamond, and AIME25 despite higher sparsity. Inference tests on 8xH200 with FP8 quantization demonstrated strong throughput, attributed to its sparse architecture and attention design.
The authors evaluate Trinity Large Base on a suite of capability benchmarks including coding, math, commonsense, knowledge, and reasoning tasks. Results show competitive performance against other open-weight base models, despite having higher sparsity and fewer active parameters. The model achieves strong scores on MMLU and TriviaQA but shows lower performance on GPQA Diamond. Scores 88.62 on MBPP+ for coding ability Achieves 82.58 on MMLU with 5-shot prompting Shows 43.94 on GPQA Diamond, indicating room for improvement in advanced reasoning

The Trinity Large Preview model was evaluated on several benchmarks after a light post-training phase. Results show strong performance on knowledge and reasoning tasks, with scores of 87.21 on MMLU and 75.25 on MMLU-Pro. The model also achieved 63.32 on GPQA Diamond, indicating competitive reasoning ability despite limited post-training. Scores 87.21 on MMLU, showing strong general knowledge Achieves 75.25 on MMLU-Pro, indicating advanced reasoning Reaches 63.32 on GPQA Diamond, reflecting robust expert-level reasoning

Trinity Large Base demonstrates competitive performance across coding, math, and knowledge benchmarks despite higher sparsity, achieving 88.62 on MBPP+ and 82.58 on MMLU, though it lags at 43.94 on GPQA Diamond. After light post-training, Trinity Large Preview shows improved reasoning and knowledge, scoring 87.21 on MMLU, 75.25 on MMLU-Pro, and 63.32 on GPQA Diamond, indicating stronger expert-level reasoning despite minimal fine-tuning.