Command Palette
Search for a command to run...
Bedingte Speicherung durch skalierbare Suche: Eine neue Dimension der Sparsamkeit für große Sprachmodelle
Bedingte Speicherung durch skalierbare Suche: Eine neue Dimension der Sparsamkeit für große Sprachmodelle
Zusammenfassung
Während Mixture-of-Experts (MoE) die Kapazität durch bedingte Berechnung skaliert, verfügt der Transformer über keine native primitive für Wissensabfrage und ist daher gezwungen, die Recherche ineffizient durch Berechnung zu simulieren. Um dies zu beheben, führen wir bedingten Speicher als ergänzende Sparsitätsachse ein, der mittels Engram, einem Modul, das die klassische N-Gramm-Embedding-Technik modernisiert und eine O(1)-Abfrage ermöglicht, realisiert wird. Durch die Formulierung des Sparsitätsallokationsproblems entdecken wir eine U-förmige Skalierungsgesetzmäßigkeit, die das Gleichgewicht zwischen neuronaler Berechnung (MoE) und statischem Speicher (Engram) optimiert.Angetrieben durch dieses Gesetz skalarisieren wir Engram auf 27 Milliarden Parameter und erreichen eine überlegene Leistung im Vergleich zu einer strikt iso-parametrischen und iso-FLOPs-basierten MoE-Benchmark. Besonders bemerkenswert ist, dass der Speichermodul zwar erwartungsgemäß die Wissensabfrage verbessert (z. B. MMLU +3,4; CMMLU +4,0), wir jedoch noch größere Verbesserungen in allgemeinen Schlussfolgerungsfähigkeiten (z. B. BBH +5,0; ARC-Challenge +3,7) und in den Bereichen Code und Mathematik (HumanEval +3,0; MATH +2,4) beobachten. Mechanistische Analysen zeigen, dass Engram die frühen Schichten des Hauptmodells von der statischen Rekonstruktion entlastet und so die Tiefe des Netzwerks effektiv für komplexe Schlussfolgerungen erhöht. Zudem entlastet die Delegation lokaler Abhängigkeiten an die Abfrage die Aufmerksamkeitskapazität für globale Kontextinformationen, wodurch die Leistung bei der Verarbeitung langer Kontexte erheblich steigt (z. B. Multi-Query NIAH: 84,2 → 97,0). Schließlich etabliert Engram eine effizienzorientierte Architektur: durch deterministische Adressierung ermöglicht es die vorab-Ladung (prefetching) aus dem Host-Speicher zur Laufzeit, wobei der Overhead vernachlässigbar gering ist. Wir sehen bedingten Speicher als unverzichtbares Modellierungsprimitiv für zukünftige sparsame Modelle. Der Quellcode ist verfügbar unter: https://github.com/deepseek-ai/Engram
One-Sentence Summary
Researchers from Peking University and DeepSeek-AI introduce Engram, a scalable conditional memory module with O(1) lookup that complements MoE by offloading static knowledge retrieval, freeing early Transformer layers for deeper reasoning and delivering consistent gains across reasoning (BBH +5.0, ARC-Challenge +3.7), code and math (HumanEval +3.0, MATH +2.4), and long-context tasks (Multi-Query NIAH: 84.2 → 97.0), while maintaining iso-parameter and iso-FLOPs efficiency.
Key Contributions
-
Conditional memory as a new sparsity axis. The paper introduces conditional memory as a complement to MoE, realized via Engram—a modernized N-gram embedding module enabling O(1) retrieval of static patterns and reducing reliance on neural computation for knowledge reconstruction.
-
Principled scaling via sparsity allocation. Guided by a U-shaped scaling law from the Sparsity Allocation problem, Engram is scaled to 27B parameters and surpasses iso-parameter and iso-FLOPs MoE baselines on MMLU (+3.4), BBH (+5.0), HumanEval (+3.0), and Multi-Query NIAH (84.2 → 97.0).
-
Mechanistic and systems insights. Analysis shows Engram increases effective network depth by offloading static reconstruction from early layers and reallocating attention to global context, improving long-context retrieval while enabling infrastructure-aware efficiency through decoupled storage and compute.
Introduction
Transformers often simulate knowledge retrieval through expensive computation, wasting early-layer capacity on reconstructing static patterns such as named entities or formulaic expressions. Prior approaches either treat N-gram lookups as external augmentations or embed them only at the input layer, limiting their usefulness in sparse, compute-optimized architectures like MoE.
The authors propose Engram, a conditional memory module that modernizes N-gram embeddings for constant-time lookup and injects them into deeper layers of the network to complement MoE. By formulating a Sparsity Allocation problem, they uncover a U-shaped scaling law that guides how parameters should be divided between computation (MoE) and memory (Engram). Scaling Engram to 27B parameters yields strong gains not only on knowledge benchmarks, but also on reasoning, coding, and math tasks.
Mechanistic analyses further show that Engram frees early layers for higher-level reasoning and substantially improves long-context modeling. Thanks to deterministic addressing, its memory can be offloaded to host storage with minimal overhead, making it practical at very large scales.
Method
Engram augments a Transformer by structurally decoupling static pattern storage from dynamic computation. It operates in two phases—retrieval and fusion—applied at every token position.
Engram is inserted between the token embedding layer and the attention block, and its output is added through a residual connection before MoE.
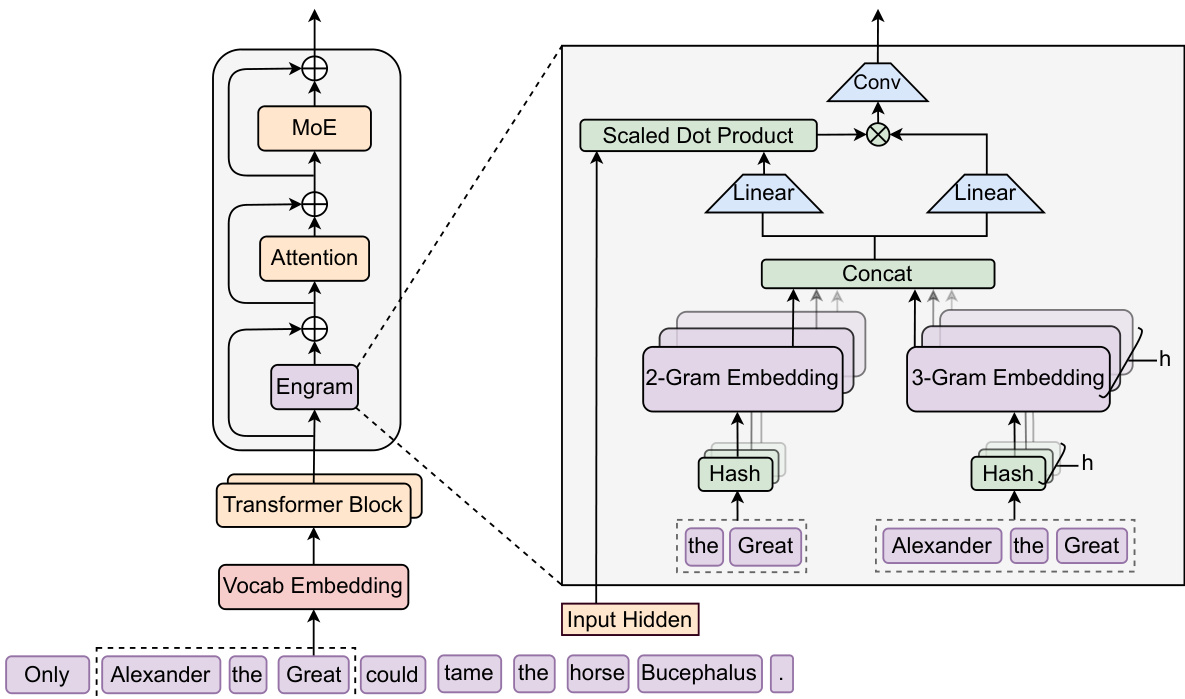
Retrieval Phase
-
Canonicalization.
Tokens are mapped to canonical IDs using a vocabulary projection layer P (e.g., NFKC normalization and lowercasing), reducing effective vocabulary size by 23% for a 128k tokenizer. -
N-gram construction.
For each position t, suffix N-grams gt,n are formed from canonical IDs. -
Multi-head hashing.
To avoid parameterizing the full combinatorial N-gram space, the model uses K hash functions varphin,k to map each N-gram into a prime-sized embedding table En,k, retrieving embeddings et,n,k. -
Concatenation.
The final memory vector is
Fusion Phase
The static memory vector et is modulated by the current hidden state ht:
kt=WKet,vt=WVet.A scalar gate controls the contribution:
αt=σ(dRMSNorm(ht)⊤RMSNorm(kt)).The gated value v~t=αt⋅vt is refined using a depthwise causal convolution:
Y=SiLU(Conv1D(RMSNorm(V~)))+V~.This output is added back to the hidden state before attention and MoE layers.
Multi-branch Parameter Sharing
For architectures with multiple branches:
- Embedding tables and WV are shared.
- Each branch (m) has its own WK(m):
Outputs are fused into a single dense FP8 matrix multiplication for GPU efficiency.
System Design
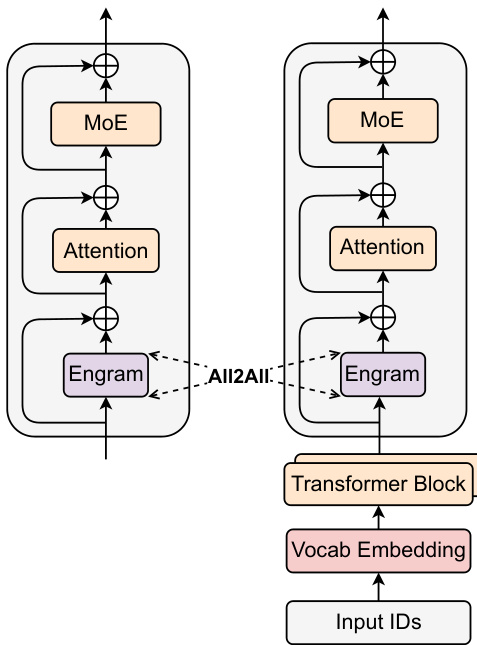
Training
Embedding tables are sharded across GPUs. Active rows are retrieved using All-to-All communication, enabling linear scaling of memory capacity with the number of accelerators.
Inference
Deterministic addressing allows embeddings to be offloaded to host memory:
- Asynchronous PCIe prefetch overlaps memory access with computation.
- A multi-level cache exploits the Zipfian distribution of N-grams.
- Frequent patterns remain on fast memory; rare ones reside on high-capacity storage.
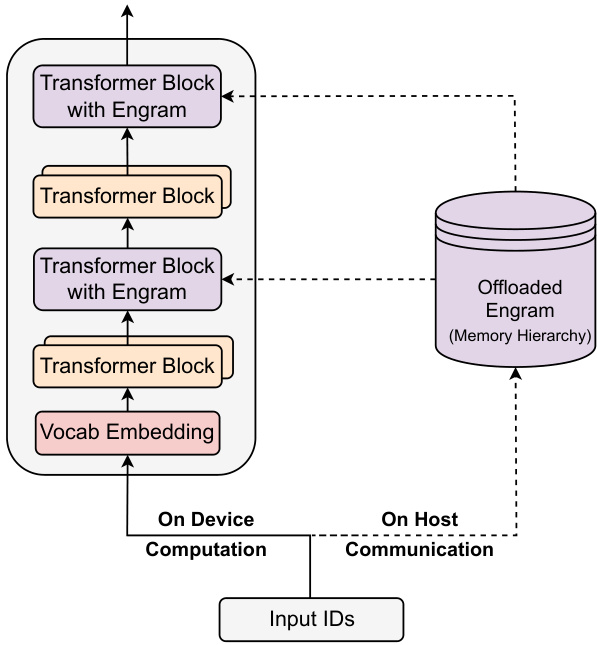
This design enables massive memory capacity with negligible impact on effective latency.
Experiments
Parameter Allocation
Under compute-matched settings, allocating 75–80% of sparse parameters to MoE and the remainder to Engram yields optimal results, outperforming pure MoE baselines:
- Validation loss at 10B scale: 1.7109 (Engram) vs. 1.7248 (MoE).
Scaling Engram’s memory under fixed compute produces consistent power-law improvements and outperforms OverEncoding.
Benchmark Performance
Engram-27B (26.7B parameters) surpasses MoE-27B under identical FLOPs:
- BBH: +5.0
- HumanEval: +3.0
- MMLU: +3.0
Scaling to Engram-40B further reduces pre-training loss to 1.610 and improves most benchmarks.
All sparse models (MoE and Engram) substantially outperform a dense 4B baseline under iso-FLOPs.

Long-Context Evaluation
Engram-27B consistently outperforms MoE-27B on LongPPL and RULER benchmarks:
- Best performance on Multi-Query NIAH and Variable Tracking.
- At 41k steps (82% of MoE FLOPs), Engram already matches or exceeds MoE.

Inference Throughput with Memory Offload
Offloading a 100B-parameter Engram layer to CPU memory incurs minimal slowdown:
- 4B model: 9,031 → 8,858 tok/s
- 8B model: 6,316 → 6,140 tok/s (2.8% drop)
Deterministic access enables effective prefetching, masking PCIe latency.

Conclusion
Engram introduces conditional memory as a first-class sparsity mechanism, complementing MoE by separating static knowledge storage from dynamic computation. It delivers:
- Strong gains in reasoning, coding, math, and long-context retrieval.
- Better utilization of early Transformer layers.
- Scalable, infrastructure-friendly memory via deterministic access and offloading.
Together, these results suggest that future large language models should treat memory and computation as independently scalable resources, rather than forcing all knowledge into neural weights.