Command Palette
Search for a command to run...
Halluzinationen untergraben das Vertrauen; Metakognition ist ein Weg nach vorn
Halluzinationen untergraben das Vertrauen; Metakognition ist ein Weg nach vorn
Gal Yona Mor Geva Yossi Matias
Zusammenfassung
Trotz erheblicher Fortschritte bei der faktischen Zuverlässigkeit bleiben Fehler – oft als Halluzinationen bezeichnet – ein erhebliches Anliegen für generative KI, insbesondere da an große Sprachmodelle (Large Language Models, LLMs) in immer komplexeren oder nuancierteren Szenarien erhöhte Erwartungen hinsichtlich ihrer Hilfestellung geknüpft werden. Doch selbst im einfachsten Setting, dem faktoiden Fragen-und-Antworten-Format mit klarer Ground Truth, halluzinieren modernste Modelle ohne externe Werkzeuge weiterhin.Wir argumentieren, dass die meisten faktischkeitsbezogenen Verbesserungen in diesem Bereich darauf zurückzuführen sind, dass die Wissensgrenzen der Modelle erweitert wurden (durch Codierung weiterer Fakten), anstatt das Bewusstsein für diese Grenzen zu schärfen (also das Unterscheiden von Bekanntem und Unbekanntem). Wir gehen davon aus, dass Letzteres prinzipiell schwer zu bewältigen ist: Modelle verfügen möglicherweise nicht über die erforderliche diskriminierende Leistungsfähigkeit, um Wahrheiten und Fehler perfekt voneinander zu trennen, was zu einem unvermeidlichen Zielkonflikt zwischen der Eliminierung von Halluzinationen und der Aufrechterhaltung der Nutzungsnützlichkeit führt.Dieser Zielkonflikt löst sich jedoch unter einer anderen Perspektive auf. Wenn wir Halluzinationen als selbstbewusste Fehler verstehen – also unrichtige Informationen, die ohne die erforderliche Qualifikation ausgegeben werden –, eröffnet sich ein dritter Weg jenseits der Dualität von „Antwort oder Enthaltung“: Der Ausdruck von Unsicherheit. Wir schlagen „faithful uncertainty“ (treue/gerechte Unsicherheit) vor: eine Ausrichtung der sprachlichen Unsicherheit auf die inhärente Unsicherheit. Dies ist eine Facette der Metakognition – der Fähigkeit, sich der eigenen Unsicherheit bewusst zu sein und entsprechend darauf zu reagieren. Im Kontext direkter Interaktion bedeutet das Handeln angesichts von Unsicherheit, diese ehrlich zu kommunizieren; in agentic systems (selbständigen Systemen) wird sie zur Steuerungsebene, die entscheidet, wann gesucht und wem vertraut werden soll. Metakognition ist daher entscheidend dafür, dass LLMs sowohl vertrauenswürdig als auch leistungsfähig sind. Wir schließen damit, dass weitere offene Probleme für Fortschritte in Richtung dieses Ziels hervorgehoben werden.
One-sentence Summary
The authors propose a metacognitive framework that mitigates large language model hallucinations by aligning linguistic uncertainty with intrinsic uncertainty, shifting focus from knowledge expansion to faithful uncertainty expression that enhances trustworthiness and utility in both direct conversational interfaces and autonomous agentic systems.
Key Contributions
- This work defines faithful uncertainty as a metacognitive objective that aligns linguistic expressions of doubt with a model’s intrinsic confidence state, ensuring accurate communication of limitations at the edge of model competence.
- The approach reframes hallucination mitigation by transcending the answer-or-abstain dichotomy, positioning calibrated uncertainty as a control layer that governs tool selection and verification in agentic systems.
- The study introduces process-based evaluation frameworks for AI agents that prioritize metacognitive reliability over end-to-end correctness, incorporating specific validation mechanisms to penalize inefficient searching and sycophantic source trust.
Introduction
Large language models are increasingly deployed in high-stakes applications where factual reliability directly impacts user trust and safety, yet they continue to generate confident errors known as hallucinations. Prior mitigation strategies have primarily focused on expanding internal knowledge or improving aggregate confidence calibration, but these approaches fail because models fundamentally lack the discriminative power to reliably separate correct answers from incorrect ones at the instance level. This limitation forces a strict trade-off between factual accuracy and practical utility, as eliminating errors typically requires aggressive answer refusal that suppresses valid information. The authors reframe hallucinations as confident errors and introduce faithful uncertainty as a metacognitive solution. By aligning linguistic hedging with a model's intrinsic confidence state, they enable systems to preserve useful information while honestly communicating doubt, ultimately establishing a reliable control layer for both direct interaction and agentic tool use.
Dataset

- Dataset Composition and Sources: The authors constructed a synthetic dataset of 25,000 samples designed to replicate the empirical confidence profiles documented by Nakkiran et al. (2025).
- Subset Details and Generation Rules: The dataset maintains a fixed 25% base hallucination rate. Confidence scores are generated using Beta distributions to simulate overlapping LLM behavior, drawing correct answers from Beta(1.8, 1.0) and incorrect answers from Beta(1.0, 1.3).
- Processing and Calibration: To ensure the observed trade-offs arise solely from distribution overlap rather than probability miscalibration, the team applied isotonic regression to the raw scores. This step achieved near-perfect calibration (smECE ≈ 0.014) and isolated discriminative power as the limiting factor.
- Usage and Evaluation Strategy: Rather than using the data for model training, the authors employ it to analyze utility-error curves. They sweep a rejection threshold across the calibrated scores to calculate the proportion of correctly answered versus incorrectly answered samples at each decision boundary.
Method
The authors propose a framework centered on the concept of faithful uncertainty, which reorients the objective of large language models (LLMs) from purely factual accuracy to the alignment between the model's internal confidence and its expressed uncertainty in responses. This approach directly addresses the utility–factuality tradeoff, where models are often forced to either abstain from uncertain claims—thereby sacrificing useful information—or generate confident but potentially incorrect answers. Faithful uncertainty allows models to preserve utility by generating responses while appropriately hedging uncertain claims, thus maintaining trust without sacrificing informativeness. The core idea is that models should not only be knowledgeable but also reliably communicate their uncertainty, where the goal is not to eliminate hallucinations entirely but to ensure that any uncertainty in the output accurately reflects the model’s intrinsic confidence.
Refer to the framework diagram 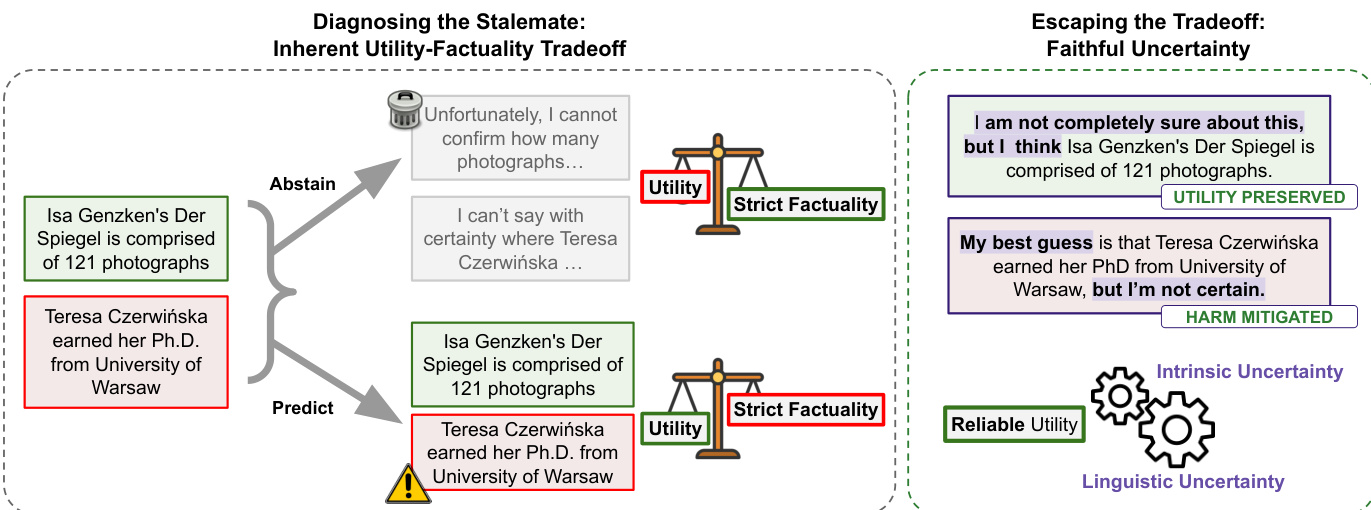 . This diagram illustrates the inherent tradeoff between utility and factuality under strict factuality constraints, where models must either abstain from uncertain claims or predict, leading to potential errors that reduce trust. In contrast, the faithful uncertainty paradigm enables models to preserve utility by expressing uncertainty linguistically while still providing answers, thereby mitigating harm through appropriate hedging. This framework mirrors how human experts communicate, where confidence in a statement is explicitly reflected in language, enhancing trust without sacrificing the provision of useful information.
. This diagram illustrates the inherent tradeoff between utility and factuality under strict factuality constraints, where models must either abstain from uncertain claims or predict, leading to potential errors that reduce trust. In contrast, the faithful uncertainty paradigm enables models to preserve utility by expressing uncertainty linguistically while still providing answers, thereby mitigating harm through appropriate hedging. This framework mirrors how human experts communicate, where confidence in a statement is explicitly reflected in language, enhancing trust without sacrificing the provision of useful information.
The operationalization of faithful uncertainty relies on two key measures: intrinsic uncertainty and linguistic uncertainty. Intrinsic uncertainty is defined as the model's internal confidence in a given assertion, quantified by the likelihood of generating conflicting answers under repeated sampling. For a query Q and assertion A, intrinsic confidence confM(A) is computed as 1−k1∑i=1k1[A contradicts Ai], where A1,…,Ak are the assertions generated by the model. Linguistic uncertainty, on the other hand, is measured by decisiveness—the degree to which an assertion is conveyed confidently or hedged in the output. This is captured as dec(A;R,Q)=Pr[A is True∣R,Q], estimated using an LLM-as-a-judge. Faithful uncertainty is then defined as the alignment between these two measures, with a faithfulness score computed as 1−∣A(R)∣1∑A∈A(R)∣dec(A;R,Q)−confM(A)∣. A score of 1 indicates perfect alignment, while lower values indicate systematic over- or under-hedging.
As shown in the figure below: 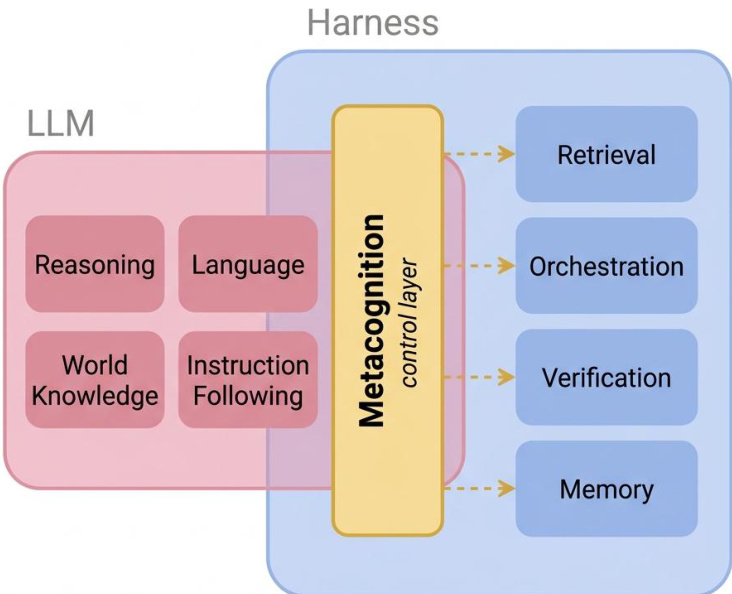 , the proposed architecture integrates a metacognitive control layer that acts as a harness for the LLM. This layer supervises and modulates the model’s behavior by accessing internal states such as reasoning, language, world knowledge, and instruction following. It routes outputs to external components like retrieval, orchestration, verification, and memory, enabling the model to dynamically assess and express uncertainty. This modular design allows the system to separate factual reasoning from metacognitive evaluation, facilitating the extraction and utilization of confidence signals.
, the proposed architecture integrates a metacognitive control layer that acts as a harness for the LLM. This layer supervises and modulates the model’s behavior by accessing internal states such as reasoning, language, world knowledge, and instruction following. It routes outputs to external components like retrieval, orchestration, verification, and memory, enabling the model to dynamically assess and express uncertainty. This modular design allows the system to separate factual reasoning from metacognitive evaluation, facilitating the extraction and utilization of confidence signals.
The authors argue that faithful uncertainty is a feasible and practical objective because it bypasses the limitations of mapping finite parameters to an infinite external world. Instead, it treats the problem as a closed-loop system where the ground truth for faithfulness is internal—specifically, the model's own confidence signals. These signals are inherently computable and can be exploited through architectural improvements, data modifications, and better training recipes. The framework further supports the idea that intrinsic uncertainty signals are already present and accessible, as evidenced by recent work in mechanistic interpretability and the use of such signals in reinforcement learning to enhance diversity and reasoning.
Refer to the framework diagram 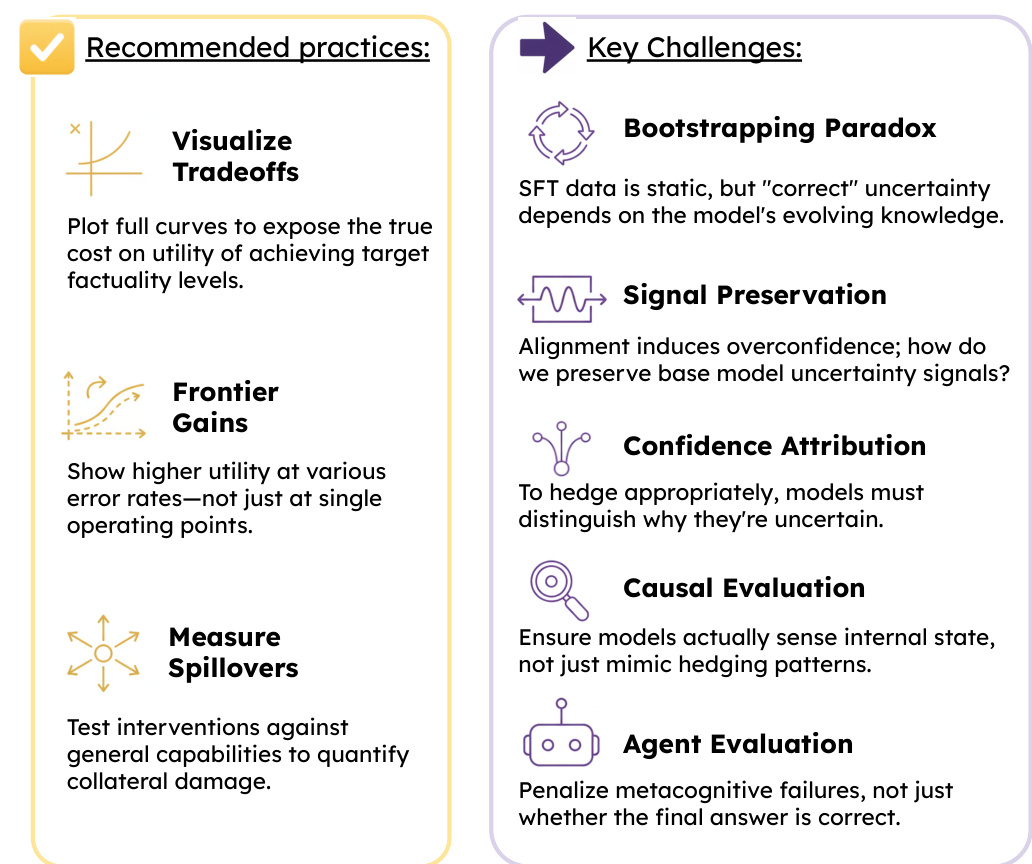 . This diagram outlines recommended practices and key challenges in implementing faithful uncertainty. Recommended practices include visualizing tradeoffs through full curves to expose the true cost of factuality, showing frontier gains at various error rates, and measuring spillovers to test interventions against general capabilities. Key challenges include the bootstrapping paradox, where SFT data is static but uncertainty depends on evolving knowledge; signal preservation, where alignment may induce overconfidence; confidence attribution, requiring models to distinguish why they are uncertain; causal evaluation, ensuring models sense internal states rather than mimic hedging patterns; and agent evaluation, which penalizes metacognitive failures rather than just incorrect answers. These considerations highlight the complexity of aligning internal confidence with linguistic expression and the need for robust evaluation methods.
. This diagram outlines recommended practices and key challenges in implementing faithful uncertainty. Recommended practices include visualizing tradeoffs through full curves to expose the true cost of factuality, showing frontier gains at various error rates, and measuring spillovers to test interventions against general capabilities. Key challenges include the bootstrapping paradox, where SFT data is static but uncertainty depends on evolving knowledge; signal preservation, where alignment may induce overconfidence; confidence attribution, requiring models to distinguish why they are uncertain; causal evaluation, ensuring models sense internal states rather than mimic hedging patterns; and agent evaluation, which penalizes metacognitive failures rather than just incorrect answers. These considerations highlight the complexity of aligning internal confidence with linguistic expression and the need for robust evaluation methods.
Experiment
Evaluation on the SimpleQA Verified dataset reveals a fundamental bifurcation where models must choose between broad coverage with high hallucination rates or reduced utility to ensure factuality. This analysis validates an inherent capability gap, demonstrating that current language models cannot reliably distinguish their own errors from accurate knowledge and thus leave the ideal performance region unpopulated. Consequently, the experiments conclude that standard metrics obscure the unavoidable utility tax of hallucination mitigation, establishing the need for evaluation frameworks that track full utility-error tradeoffs, verify genuine capability improvements, and assess collateral impacts on general model helpfulness.