Command Palette
Search for a command to run...
Trennung von Intelligenz und Ausführung: Eine Workflow-Engine für das Model Context Protocol
Trennung von Intelligenz und Ausführung: Eine Workflow-Engine für das Model Context Protocol
Abhinav Singh Parmar
Zusammenfassung
Agenten großer Sprachmodelle (LLMs) interagieren zunehmend über Tool-Calling-Protokolle wie das Model Context Protocol (MCP) mit externen Systemen. In vorherrschenden Architekturen muss der Agent in jeder Sitzung jede Tool-Ausführung begründen, was Token verbraucht, die proportional zur Anzahl der ausgeführten Aktionen sind – selbst wenn die Aufgabe bereits zuvor gelöst wurde. Wir stellen die MCP Workflow Engine vor, eine neuartige, MCP-native Orchestrierungsschicht, die Intelligenz (Entscheidung darüber, was zu tun ist) von der Ausführung (Durchführung) entkoppelt. Ein Agent führt die Begründung einmal durch, um einen deklarativen Workflow-Blueprint zu erzeugen – ein JSON-Dokument, das eine gerichtete Sequenz von MCP-Tool-Aufrufen mit parametrisierten Vorlagen, Schleifen, parallelen Zweigen und Daten-Piping spezifiziert. Folgende Ausführungen werden durch einen einzigen Aufruf des run_workflow-Tools ausgelöst, wobei unabhängig von der internen Komplexität des Blueprints nur ein Aufruf äquivalenter Token verbraucht wird. Wir formalisieren das architekturbedingte Muster des MCP Mediators – einen MCP-Server, der gleichzeitig als Client gegenüber nachgelagerten MCP-Servern agiert – und implementieren es in TypeScript gegen das MCP SDK. Wir evaluieren die Engine an einer Produktionsumgebung für die Synchronisierung einer Kubernetes-Konfigurationsdatenbank (CMDB), die 67 orchestrierte Schritte über 2 MCP-Server, 38 Namespaces, 13 Worker-Knoten und 22 unterschiedliche Ressourcentypen umfasste. Die Engine reduziert die Token-Kosten pro Ausführung um über 99 %, stellt den vollständigen Cluster-Graphen – bestehend aus mehr als 1.200 Knoten und mehr als 2.800 Beziehungen über 20 Beziehungstypen – in weniger als 45 Sekunden her und erzielt deterministische, idempotente Ausführungen ohne jegliche Agentenbeteiligung zur Laufzeit.
One-sentence Summary
The MCP Workflow Engine decouples LLM intelligence from execution by compiling agent tasks into declarative JSON blueprints featuring parameterized templates, loops, parallel branches, and data piping, enabling a single run_workflow call to trigger complex sequences while consuming only one invocation’s worth of tokens, and its efficacy is validated on a production-scale Kubernetes CMDB synchronization task spanning 67 steps across two MCP servers, 38 namespaces, 13 worker nodes, and 22 resource types.
Key Contributions
- The work introduces the MCP Workflow Engine and formalizes the MCP Mediator architectural pattern, establishing an orchestration layer that explicitly decouples AI-driven planning from automated task execution.
- An agent generates a single declarative JSON blueprint specifying parameterized templates, loops, parallel branches, and data piping, after which the engine executes the entire pipeline using only one invocation's worth of tokens regardless of internal complexity.
- The TypeScript implementation against the MCP SDK is evaluated on a production-scale Kubernetes CMDB synchronization task, successfully orchestrating 67 steps across two MCP servers, 38 namespaces, 13 worker nodes, and 22 distinct resource types without further model inference.
Introduction
The authors address the growing reliance on tool-augmented LLM agents for automating complex, multi-step operations across heterogeneous systems using standardized interfaces like the Model Context Protocol. While these agents enable powerful software automation, existing architectures force the model to reason through every single execution step, causing quadratic token growth, high latency, and prohibitive costs for recurring tasks. Traditional workflow engines avoid this expense but require manual developer-authored graphs, while multi-agent frameworks keep the LLM trapped in the execution loop. To bridge this gap, the authors introduce the MCP Workflow Engine, which formally separates one-time planning from repeated execution. The model generates a declarative JSON workflow blueprint during an initial design phase, after which the engine executes the steps deterministically without any further LLM involvement, drastically reducing inference costs while maintaining full automation.
Dataset

- Dataset composition and sources: The authors generate a cluster management database (CMDB) graph by synchronizing live Kubernetes cluster resources through a structured workflow blueprint.
- Key details for each subset: The resulting dataset contains over 1,200 nodes and 2,800 relationships, organized into 16 node labels and 20 relationship types. The workflow processes these resources across three distinct phases, including cluster-scoped creation, namespace-scoped iteration, and cross-resource relationship mapping.
- Data usage and processing: The authors execute the synchronization pipeline to validate the graph generation process, expanding 67 top-level steps into approximately 2,000 MCP tool invocations via loop iterations. The pipeline processes the data sequentially, completing with zero errors and consuming zero agent tokens.
- Metadata and structural details: The graph schema is constructed with the Cluster node as the root, branching into Namespace and Node as primary children. The authors enforce a strict phase-based execution order and explicitly define relationship types to maintain consistent metadata topology across the synchronized cluster.
Method
The MCP Workflow Engine employs a novel architectural pattern, the MCP Mediator, which decouples the reasoning phase of an LLM agent from the execution phase of tool calls. This design enables the engine to function simultaneously as an MCP server, exposing workflow management tools to agents, and as an MCP client, connecting to downstream MCP servers to execute tool invocations. The system operates in a two-phase lifecycle. During Phase 1a, the agent explores the environment by discovering downstream MCP servers through tool listings and making trial calls to learn the schema of available tools and their response structures. In Phase 1b, the agent reasons about the required resource types, relationships, and step ordering to construct a declarative workflow blueprint—a reusable JSON document. This blueprint is then stored and can be executed repeatedly. Refer to the framework diagram for a visual representation of the system's architecture, which illustrates the distinct layers and components involved.
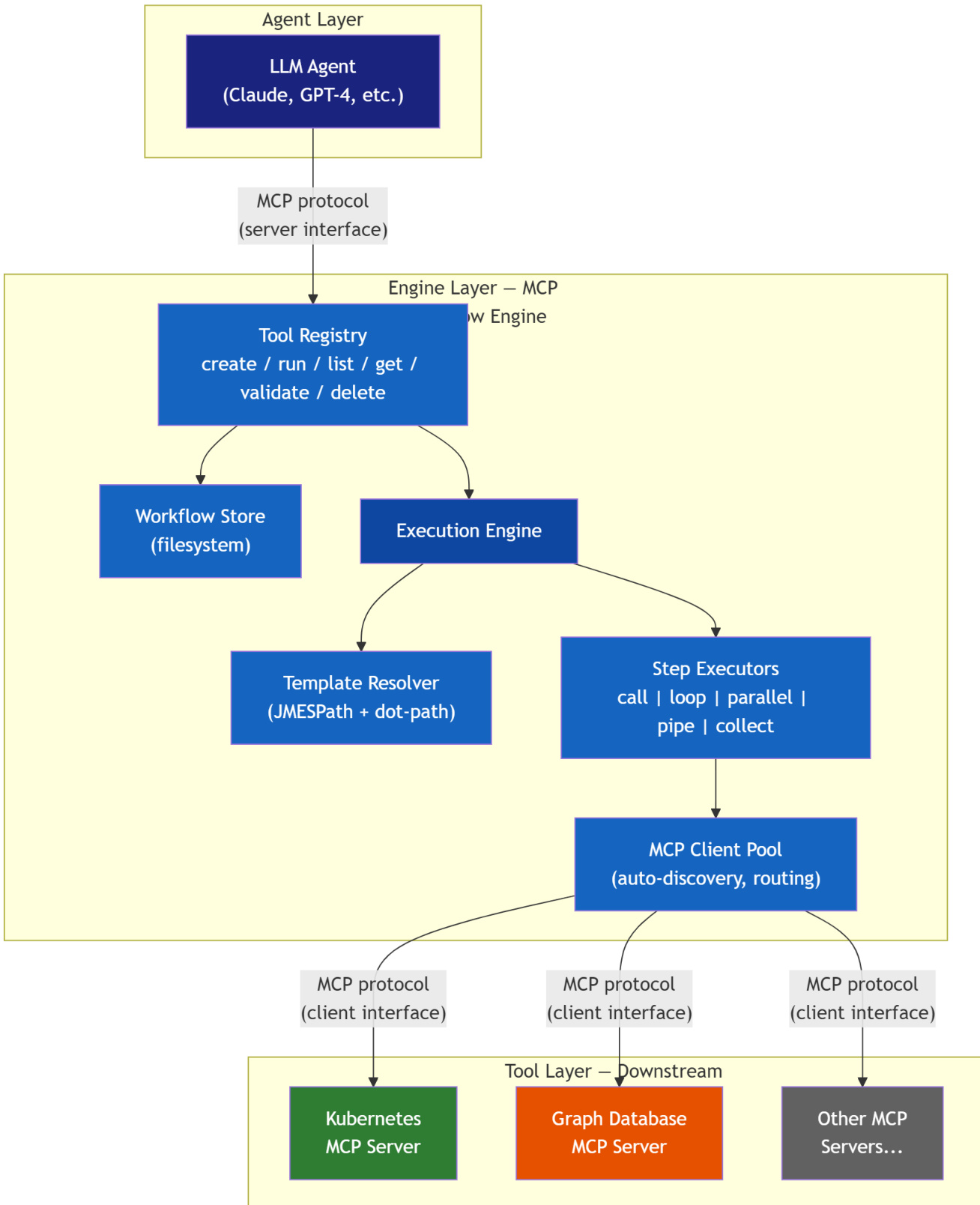
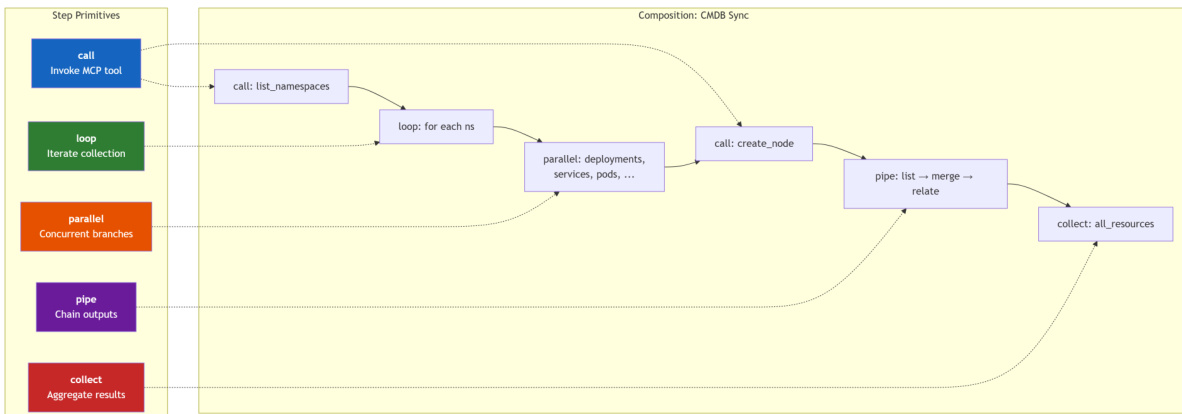
The workflow blueprint is the central artifact of the system, designed to be a portable, versionable, and human-readable JSON document. It specifies an identifier, description, parameterized inputs, an error handling strategy, and a sequence of steps. The engine's execution is driven by a minimal, five-primitive Domain-Specific Language (DSL) for orchestrating these steps. The first primitive is call, which invokes a specific MCP tool on a downstream server. The loop primitive iterates over a collection, executing a sub-step for each item and injecting per-item context. The parallel primitive executes multiple independent branches concurrently, maximizing throughput. The pipe primitive enables a sequential data transformation pipeline, where the output of one step becomes the input for the next. Finally, the collect primitive aggregates results from a sub-workflow, facilitating hybrid agent-engine patterns where the agent reviews a batch of results. The design intentionally omits constructs like conditionals and variables to maintain simplicity and predictability, preventing the DSL from evolving into an accidental programming language. As shown in the diagram below, these primitives are composed to form a complete workflow, such as a Kubernetes CMDB synchronization process.

The execution engine relies on a robust template resolution pipeline to process parameterized inputs. This pipeline performs multi-pass substitution, resolving loop variables and step references to produce fully resolved commands. It supports JMES.Path expressions for structured data extraction and a dot-path fallback for simple property access. A critical design decision ensures that when a value is a single template expression, the resolver returns the raw value (preserving arrays and objects) rather than a stringified version, enabling type-safe data flow between steps. The engine's client pool manages connections to downstream MCP servers, automatically discovering tools and building a routing table. It supports three error strategies: abort, continue, and retry, with an option to accumulate errors for partial-success workflows. The engine performs two-tier validation: structural errors block blueprint saving, while tool warnings are non-blocking. The two-phase lifecycle, illustrated in the sequence diagram, shows that the agent is only involved in the initial exploration and blueprint construction phases. Subsequent executions are handled entirely by the engine, consuming a fixed, minimal number of tokens regardless of the blueprint's complexity.
Experiment
Evaluated on a production Kubernetes cluster for CMDB synchronization, the experiments validate a deterministic workflow engine against a probabilistic agent-in-the-loop baseline across efficiency, reliability, and scalability dimensions. The setup demonstrates that the engine maintains stable token consumption and drastically reduces execution times regardless of cluster scale, effectively mitigating the agent baseline's rapidly escalating context costs and high latency. Reliability tests confirm that deterministic execution eliminates hallucination risks while robust error handling ensures consistent state convergence. Finally, component ablation and cross-domain evaluations verify that template resolution and parallel processing are critical for performance, and that the orchestration pattern generalizes seamlessly to other repeated multi-step tool workflows.
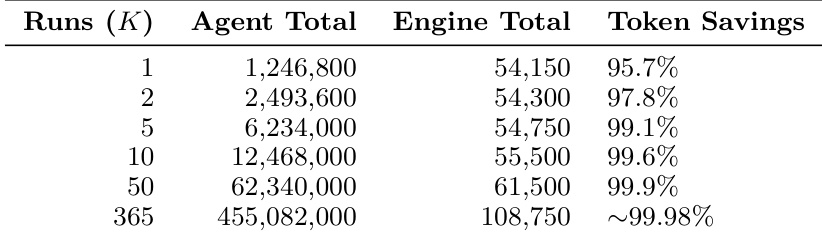
The authors analyze the token consumption of a system for CMDB synchronization, comparing a baseline agent-in-the-loop approach with a workflow engine. The workflow engine significantly reduces total token usage and execution time while ensuring deterministic and reliable behavior. Results show that the workflow engine's cost remains stable as the cluster scales, unlike the baseline which exhibits super-linear growth due to context accumulation. The workflow engine reduces total token consumption compared to the agent-in-the-loop baseline by decoupling design from execution. Execution under the workflow engine is faster and deterministic, avoiding the probabilistic failures common in agent-based approaches. Token costs scale linearly with cluster size under the workflow engine, whereas the baseline shows super-linear growth due to context accumulation.

The authors compare token consumption between an agent-in-the-loop baseline and a workflow engine across multiple runs, showing that the engine consistently achieves higher token savings as the number of runs increases. Results indicate that the engine's cost grows linearly with runs while the agent baseline's cost increases super-linearly due to context accumulation, leading to diminishing returns in efficiency. The workflow engine achieves higher token savings as the number of runs increases, with savings approaching 100% at scale. Agent-in-the-loop token costs grow super-linearly due to context accumulation, while engine costs grow linearly. The workflow engine shows significant efficiency gains, especially in large-scale repeated executions.
The authors evaluate a workflow engine against an agent-in-the-loop baseline, showing that the engine achieves faster execution and higher reliability. Removing key components such as template resolution or error handling leads to failures, while parallel execution improves performance. The engine's design enables consistent and scalable behavior across different configurations. The workflow engine completes tasks faster and with zero errors compared to the agent-in-the-loop baseline. Removing template resolution causes all steps to fail, highlighting its essential role. Without error handling, the system halts on the first failure, demonstrating the importance of robust recovery strategies.

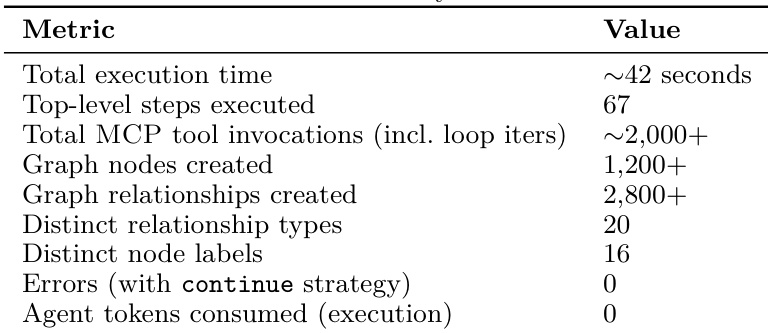
The authors evaluate a workflow engine on a Kubernetes cluster synchronization task, measuring execution time, tool invocations, and graph creation metrics. The engine achieves fast execution with no errors and minimal agent token consumption, demonstrating efficiency and reliability compared to an agent-in-the-loop baseline. The workflow engine completes the task in approximately 42 seconds with over 2,000 tool invocations and creates over 1,200 graph nodes. Execution is reliable, with zero errors when using the continue strategy and no agent tokens consumed during the process. The engine scales efficiently, maintaining consistent performance across different cluster sizes without increasing token costs.
The experiment involves a CMDB synchronization task with 67 steps across multiple phases, including cluster-scoped, namespace-scoped, and relationships phases, each involving different resource types and operations. The workflow engine demonstrates significant improvements in efficiency and reliability compared to the agent-in-the-loop baseline, particularly in reducing token consumption and execution time while maintaining deterministic behavior. The task is structured into three phases with varying resource types and operations, totaling 67 steps. The workflow engine achieves substantial improvements in execution time and reliability compared to the agent-in-the-loop approach. Token cost scales super-linearly with cluster size under the agent baseline but remains stable under the workflow engine.

The experiments evaluate a workflow engine against an agent-in-the-loop baseline for Kubernetes CMDB synchronization tasks to assess scalability, reliability, and resource efficiency. The setup validates that decoupling design from execution yields a deterministic architecture capable of maintaining stable performance across varying cluster sizes and repeated runs. Qualitative findings indicate that the workflow engine significantly outperforms the baseline by preventing context accumulation, ensuring robust error recovery, and achieving consistent efficiency without the super-linear token costs that hinder agent-based approaches.