Command Palette
Search for a command to run...
PRISM: Pre-Alignment durch Black-Box On-Policy Distillation für Multimodales Reinforcement Learning
PRISM: Pre-Alignment durch Black-Box On-Policy Distillation für Multimodales Reinforcement Learning
Zusammenfassung
Das Standard-Post-Training-Protokoll für große multimodale Modelle (LMMs) beinhaltet zunächst eine überwachungsfeinabgestimmte Schulung (SFT) mit kuratierten Demonstrationen, gefolgt von Verstärkungslernen mit überprüfbaren Belohnungen (RLVR). Die SFT führt jedoch zu einer Verteilungsdrift, die weder die ursprünglichen Fähigkeiten des Modells bewahrt noch die Überwachungsverteilung treu abbildet. Dieses Problem wird im Bereich des multimodalen Reasonings weiter verstärkt, da Wahrnehmungsfehler und Reasoning-Versagen unterschiedlichen Drift-Mustern folgen, die sich während des nachfolgenden RL-Vergütungsprozesses addieren. Wir stellen PRISM vor, eine dreistufige Pipeline, die diese Drift mildert, indem sie zwischen SFT und RLVR eine explizite Verteilungs-Ausrichtungsphase einschiebt. Basierend auf dem Prinzip des on-policy distillation (OPD) formuliert PRISM die Ausrichtung als black-box, response-level adversarial game zwischen der Policy und einem Mixture-of-Experts (MoE) Diskriminator mit dedizierten Wahrnehmungs- und Reasoning-Experten, wodurch entkoppelte Korrektursignale bereitgestellt werden, die die Policy zur Überwachungsverteilung steuern, ohne Zugriff auf Teacher-Logits zu benötigen. Während 1.26 Millionen öffentliche Demonstrationen für eine breite SFT-Initialisierung ausreichen, erfordert die Verteilungsausrichtung eine höherwertige Aufsicht; daher kuratieren wir 113.000 zusätzliche Demonstrationen aus Gemini 3 Flash, die dichtes visuelles Grounding und schrittweises Reasoning bei den schwierigsten ungelösten Problemen bieten. Experimente an Qwen3-VL zeigen, dass PRISM die nachgelagerte RLVR-Leistung konsistent über mehrere RL-Algorithmen (GRPO, DAPO, GSPO) und diverse multimodale Benchmarks verbessert, mit einer durchschnittlichen Genauigkeitssteigerung um +4.4 bzw. +6.0 Punkte gegenüber der SFT-zu-RLVR-Baseline auf 4B bzw. 8B. Unser Code, unsere Daten und Modell-Checkpoints sind öffentlich unter https://github.com/XIAO4579/PRISM verfügbar.
One-sentence Summary
PRISM is a three-stage post-training pipeline that mitigates distributional drift in large multimodal models by inserting black-box on-policy distillation between supervised fine-tuning and reinforcement learning with verifiable rewards, leveraging a Mixture-of-Experts discriminator with dedicated perception and reasoning experts to generate disentangled corrective signals without teacher logits for robust multimodal reasoning.
Key Contributions
- This work introduces PRISM, a three-stage post-training pipeline that inserts an explicit distribution-alignment phase between supervised fine-tuning and reinforcement learning with verifiable rewards to mitigate heterogeneous drift in large multimodal models.
- The alignment mechanism operates as a logit-free adversarial game in which a Mixture-of-Experts discriminator with dedicated vision and reasoning modules provides disentangled corrective signals to steer policy rollouts toward the target supervision distribution.
- A curated collection of 113,000 high-fidelity demonstrations featuring dense visual grounding and step-by-step reasoning supports this alignment stage, and extensive evaluations on Qwen3-VL confirm consistent performance gains over standard pipelines while substantially narrowing the post-fine-tuning distributional gap.
Introduction
Large multimodal models typically rely on a post-training pipeline that combines supervised fine-tuning with reinforcement learning to enhance reasoning capabilities, yet this standard approach faces critical initialization challenges that limit downstream performance. Prior work demonstrates that supervised fine-tuning often induces distributional drift, causing models to lose their native reasoning strengths while failing to accurately match the target supervision distribution, a degradation that is exacerbated in multimodal settings where perception errors and reasoning failures follow distinct patterns that compound during optimization. The authors propose PRISM, a three-stage framework that inserts an explicit pre-alignment phase between fine-tuning and reinforcement learning to repair this drift before policy refinement begins. The authors leverage black-box on-policy distillation structured as an adversarial game between the policy and a Mixture-of-Experts discriminator with dedicated perception and reasoning experts, enabling the generation of disentangled corrective signals that steer the model toward the supervision distribution without requiring access to teacher logits. This method effectively closes the distributional gap inherited from supervised fine-tuning, delivering consistent accuracy gains across multiple reinforcement learning algorithms and model scales.
Dataset
-
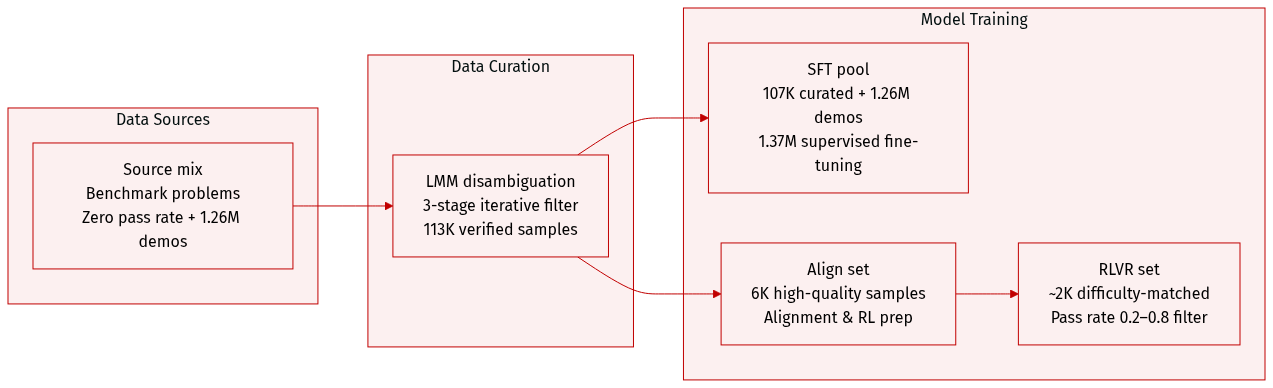
Dataset Composition and Sources: The authors construct a multimodal reasoning corpus sourced from public benchmarks covering mathematical reasoning, scientific diagram understanding, chart interpretation, and spatial reasoning. They initially select problems that achieve a zero pass rate on strong contemporary models to guarantee high difficulty. To expand coverage and stability, they supplement this curated set with 1.26 million publicly available demonstrations generated by the same Gemini model family.
-
Subset Details and Filtering Rules: The core collection contains 113,000 verified samples. Before generation, an LMM disambiguates images containing multiple sub-questions by identifying the exact prompt-answer pair and discarding irrelevant parts to enforce a strict one-to-one mapping. Gemini 3 Flash then generates detailed solutions using a strict template. The raw outputs undergo an iterative three-stage filter: a truncation and failure check, a format validation requiring non-empty content inside
<caption>,<thought>, and<answer>tags, and an LLM-as-judge correctness verification. Samples failing the first two filters are regenerated, while correctness failures are re-submitted with the ground truth appended to guide the model before re-filtering. -
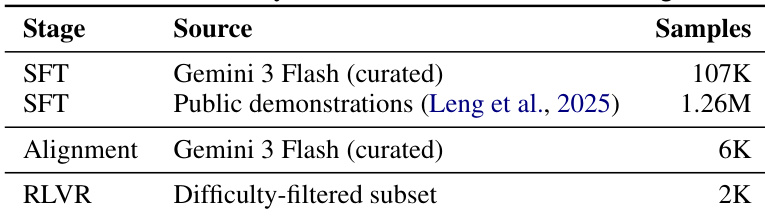
Training Splits and Usage: From the 113,000 verified samples, 107,000 are assigned to the supervised fine-tuning pool and the highest-quality 6,000 are reserved for alignment and reinforcement learning. The authors merge the 107,000 curated samples with the 1.26 million supplemental demonstrations to create a 1.37 million sample SFT corpus, which trains the model's initial multimodal reasoning policy. For reinforcement learning with verifiable rewards, they apply a difficulty-based filter that retains approximately 2,000 problems where the post-alignment policy achieves a pass rate between 0.2 and 0.8 across 16 rollouts.
-
Metadata Construction and Processing: The pipeline prioritizes structured metadata and precise visual grounding. Every training example is formatted with explicit XML-like tags to separate visual grounding (
<caption>), chain-of-thought reasoning (<thought>), and the final output (<answer>). The iterative regeneration strategy and difficulty-matched sampling ensure the model trains on high-fidelity trajectories that are neither trivial nor overwhelmingly difficult, providing a stable foundation for subsequent distribution-level correction.
Method
The PRISM framework employs a three-stage post-training pipeline that augments the conventional SFT→RLVR paradigm by introducing an intermediate alignment stage. This stage serves as a dedicated intermediate step to mitigate distributional drift introduced by SFT before the model enters the final RLVR optimization. The pipeline begins with standard supervised fine-tuning (SFT) on a high-quality, curated multimodal reasoning corpus to obtain an initial policy. This initial policy is then refined through adversarial on-policy distillation with a Mixture-of-Experts (MoE) discriminator, which provides disentangled corrective signals for perception and reasoning errors. The resulting checkpoint is used to initialize the final reinforcement learning with verifiable rewards (RLVR) stage, where the policy is further improved using outcome-based rewards.
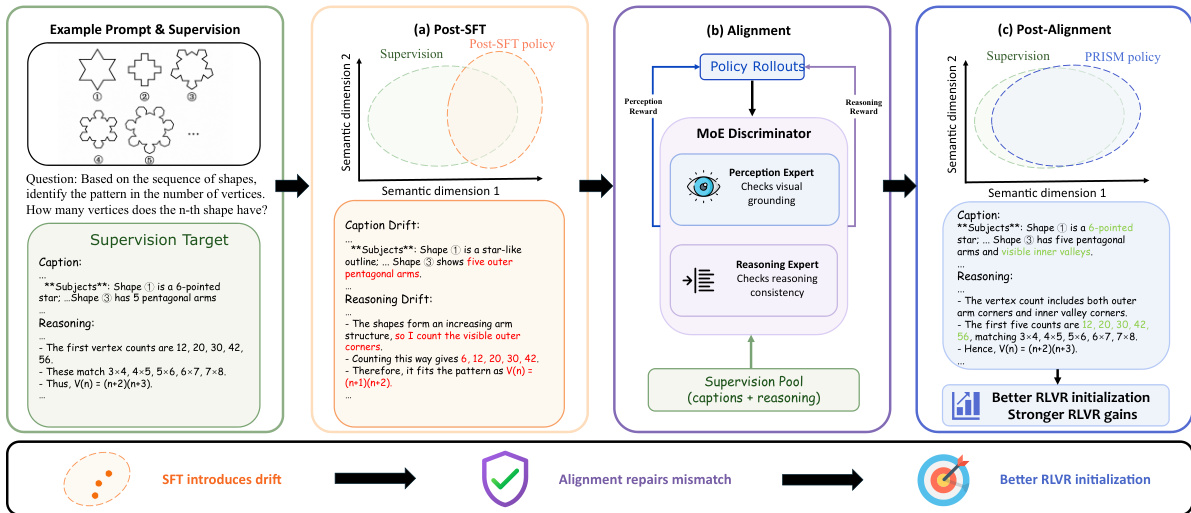
As shown in the figure below, the alignment stage is designed to repair the distributional mismatch between the post-SFT policy and the supervision distribution. The framework leverages an MoE discriminator that decomposes the alignment task into two specialized experts. The perception expert evaluates the visual description component of a response to measure its grounding in the input image, while the reasoning expert assesses the step-by-step reasoning trace for logical consistency and validity. The overall discriminator score is a weighted combination of the two expert scores, where the trade-off parameter α controls the relative influence of perceptual and reasoning feedback. This design provides a finer-grained basis for the adversarial alignment objective, enabling targeted correction of heterogeneous errors that arise from visual grounding failures and reasoning failures.
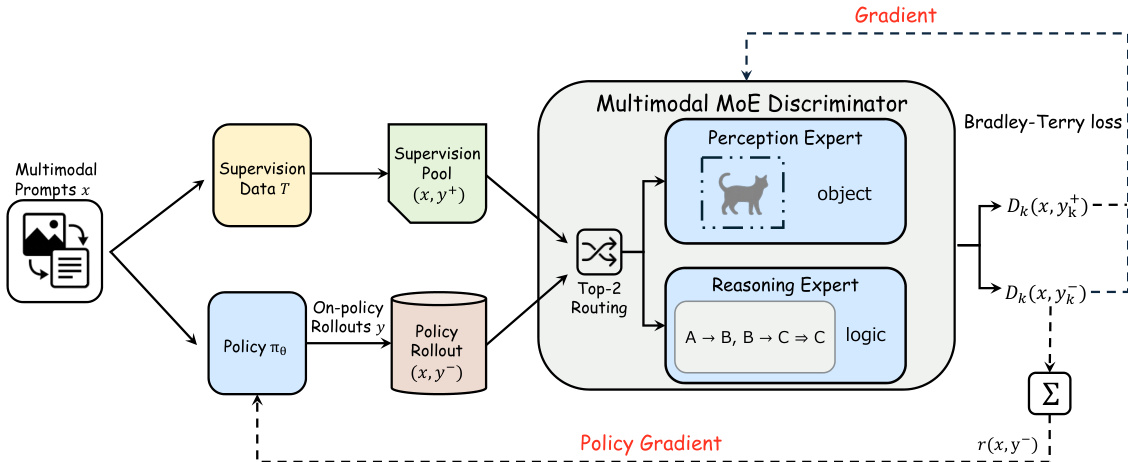
The adversarial on-policy distillation process is formulated as a minimax game between the policy and the MoE discriminator. The policy is optimized to generate responses that increasingly resemble high-quality reference demonstrations, while the discriminator is trained to distinguish between supervision data and policy rollouts. The discriminator is trained using a Bradley-Terry loss, which encourages it to assign higher scores to reference responses and lower scores to policy-generated responses. The policy is updated via policy gradient, using the MoE discriminator's reward as the learning signal. This reward is computed as a weighted sum of the perception and reasoning expert scores for each policy rollout. The policy optimization is performed using GRPO, with group-wise advantage normalization to encourage the policy to improve its relative ranking among multiple responses for the same prompt. Notably, the KL regularization term, which typically anchors the policy near its initialization, is removed to allow for a more substantial correction of SFT-induced distributional drift.

Both the policy and the MoE discriminator are initialized prior to the adversarial phase to prevent the discriminator from saturating due to a large capability gap. The policy is initialized from the SFT checkpoint, which provides a sufficiently close approximation of the supervision distribution. The MoE discriminator is initialized from the same pretrained backbone and is warm-started on its designated components: the perception expert on preference pairs from visual descriptions, and the reasoning expert on preference pairs from reasoning traces. An auxiliary load-balancing loss is applied to prevent expert collapse during this initialization stage. The alignment stage runs for a fixed number of steps, after which the final checkpoint is used to initialize the RLVR stage. The final RLVR stage uses a deterministic verifiable reward that combines answer accuracy and format compliance, and the policy is optimized using standard RL algorithms such as GRPO, DAPO, or GSPO.
Experiment
Evaluated across multiple model scales and reinforcement learning algorithms using standard multimodal benchmarks, the PRISM framework integrates supervised fine-tuning, distributional alignment, and reinforcement learning to enhance multimodal reasoning. Qualitative analysis demonstrates that the alignment stage effectively repairs the distributional drift inherent in standard fine-tuning, particularly for larger models, by establishing a robust initialization that significantly enhances downstream performance. Ablation studies further validate that the MoE discriminator's specialized experts, joint vision-language processing, and complementary data scaling are essential for maintaining stable adversarial training and preventing degenerative policy outputs. Ultimately, the framework consistently yields more concise and structurally aligned reasoning traces, confirming that explicit distributional correction substantially unlocks the effectiveness of subsequent reinforcement learning phases.
The authors describe a three-stage training pipeline that includes supervised fine-tuning, alignment, and reinforcement learning with visual reasoning. The alignment stage uses a mixture-of-experts discriminator to separately refine visual perception and reasoning components, leading to improved downstream performance across multiple benchmarks. The results show that the alignment stage corrects distributional drift introduced by fine-tuning and provides a better initialization for reinforcement learning, resulting in higher accuracy with fewer tokens. The alignment stage corrects distributional drift introduced by fine-tuning and improves downstream reinforcement learning performance. The mixture-of-experts discriminator enables separate refinement of visual perception and reasoning, leading to better performance than a single dense model. The three-stage pipeline is essential, with each stage playing a distinct role in narrowing the gap between the model and the supervision distribution.
The authors compare the training configurations across three stages: SFT, PRISM, and RLVR. The the the table shows that PRISM uses a different learning rate and optimizer compared to SFT and RLVR, and introduces a MoE-based reward mechanism with specific hyperparameters. RLVR employs a longer training schedule and different reward weights, while PRISM and RLVR both use dynamic batch size and remove padding. These differences reflect distinct optimization goals and training strategies for each stage. PRISM uses a different learning rate and optimizer compared to SFT and RLVR. PRISM introduces a MoE-based reward mechanism with specific hyperparameters not present in SFT or RLVR. RLVR uses a longer training schedule and different reward weights, while both PRISM and RLVR use dynamic batch size and remove padding.
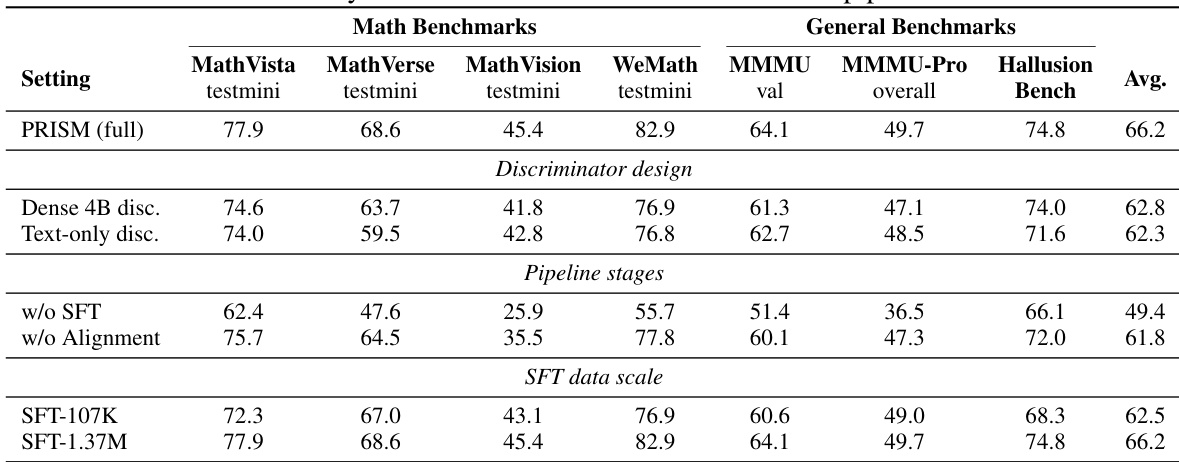
The authors present a comprehensive evaluation of their PRISM framework, demonstrating that the alignment stage significantly improves downstream reinforcement learning performance across multiple benchmarks and model scales. Results show that the full pipeline consistently outperforms baselines, with gains concentrated on mathematical reasoning tasks, and that the MoE discriminator design and three-stage training process are essential for achieving these improvements. The ablation studies further reveal that SFT data scale and the vision-language nature of the discriminator play critical roles in enabling effective distributional alignment. PRISM consistently improves downstream RLVR performance across benchmarks and model scales, with the largest gains on mathematical reasoning tasks. The MoE discriminator design is crucial for performance, as replacing it with a dense model leads to significant degradation, particularly on tasks requiring visual perception. The three-stage pipeline is necessary, as removing either SFT or the alignment stage results in substantial performance drops, indicating that each stage serves an indispensable role in the training process.
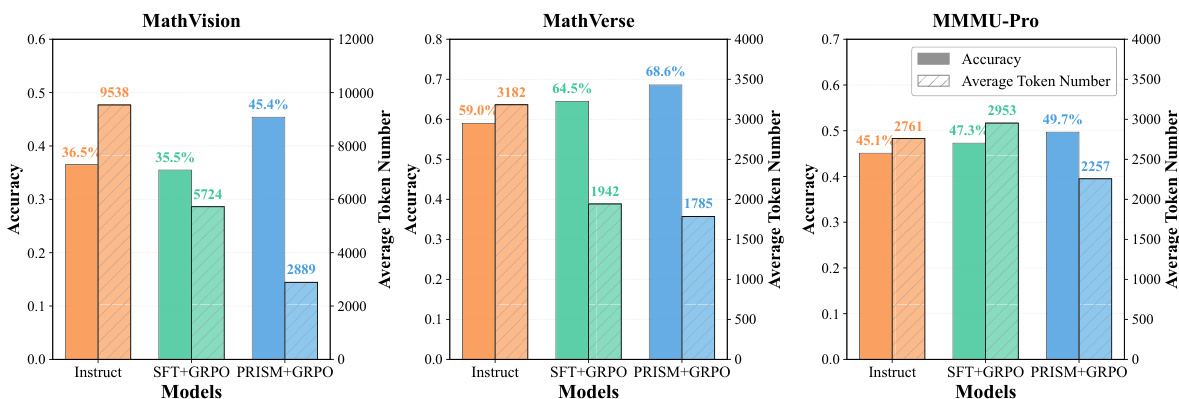
The authors present results comparing different training pipelines on mathematical reasoning and multimodal benchmarks, showing that the PRISM method consistently improves downstream reinforcement learning performance across model scales and algorithms. The PRISM pipeline achieves higher accuracy while using fewer tokens, indicating more efficient reasoning, and the alignment stage effectively corrects distributional drift introduced by supervised fine-tuning. The improvements are consistent across tasks, with the largest gains observed on benchmarks requiring strong visual grounding and reasoning. PRISM consistently outperforms baselines in accuracy while using fewer tokens, indicating more efficient and effective reasoning. The alignment stage corrects distributional drift from supervised fine-tuning, leading to better downstream reinforcement learning performance. Improvements are most pronounced on tasks requiring strong visual grounding and complex reasoning, highlighting the importance of distributional alignment in multimodal settings.
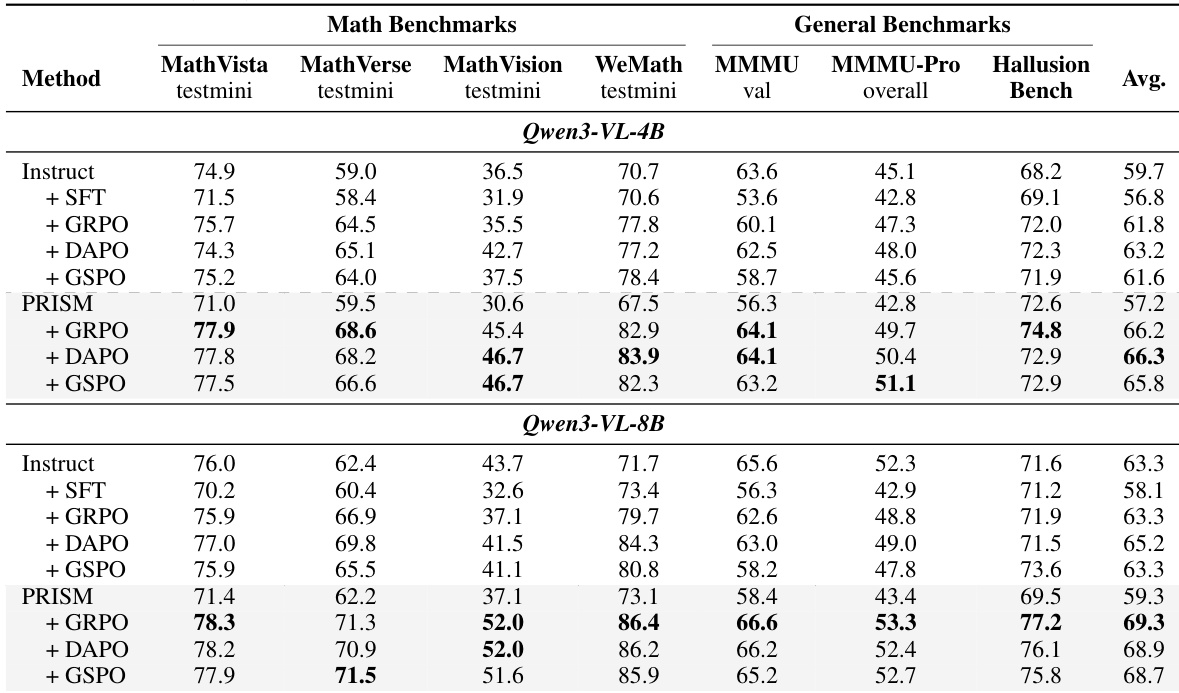
The authors present results comparing different training pipelines on multimodal reasoning benchmarks, showing that the PRISM method consistently improves downstream reinforcement learning performance across model scales and algorithms. The alignment stage in PRISM corrects distributional drift introduced by supervised fine-tuning, leading to better initialization and higher accuracy without increasing token usage. PRISM consistently improves downstream reinforcement learning performance across different models and algorithms, with the largest gains on math and vision benchmarks. The alignment stage corrects distributional drift from supervised fine-tuning, improving the model's initialization for reinforcement learning. PRISM achieves higher accuracy with fewer tokens, indicating more efficient and effective reasoning compared to baseline methods.
The evaluation compares the full three-stage training pipeline against established baselines across diverse multimodal and mathematical reasoning benchmarks, while ablation studies isolate the specific contributions of supervised fine-tuning, alignment, and reinforcement learning. These experiments validate that the alignment stage effectively corrects distributional drift from initial training and provides a superior initialization for subsequent reinforcement learning, and that the mixture-of-experts discriminator successfully refines visual perception and reasoning capabilities independently of a dense architecture. Ultimately, the framework consistently delivers higher accuracy with reduced token consumption, demonstrating that targeted distributional alignment significantly enhances both the efficiency and effectiveness of complex multimodal reasoning tasks.