Command Palette
Search for a command to run...
GLM-5V-Turbo: Auf dem Weg zu einem nativen Grundlagenmodell für multimodale Agents
GLM-5V-Turbo: Auf dem Weg zu einem nativen Grundlagenmodell für multimodale Agents
Zusammenfassung
Wir präsentieren GLM-5V-Turbo, einen Schritt hin zu nativen Foundation-Modellen für multimodale Agentic-Systeme. Da Foundation-Modelle zunehmend in realen Umgebungen eingesetzt werden, hängt ihre Agentic-Fähigkeit nicht nur von der Sprachreasoning-Leistung ab, sondern auch von der Fähigkeit, heterogene Kontexte wie Bilder, Videos, Webseiten, Dokumente und grafische Benutzeroberflächen (GUIs) wahrzunehmen, zu interpretieren und darauf zu agieren. GLM-5V-Turbo ist auf dieses Ziel ausgerichtet: Die multimodale Wahrnehmung wird als Kernkomponente der Reasoning-, Planungs-, Werkzeugnutzungs- und Ausführungsprozesse integriert und nicht lediglich als zusätzliche Schnittstelle zu einem Sprachmodell behandelt.Dieser Bericht fasst die wichtigsten Fortschritte hinter GLM-5V-Turbo zusammen, die sich auf das Modell-Design, multimodales Training, Reinforcement Learning, die Erweiterung der Werkzeugkette und die Integration in Agentic-Frameworks beziehen. Diese Entwicklungen führen zu einer starken Leistung in multimodalem Coding, der visuellen Werkzeugnutzung und agentic-Aufgaben auf Framework-Basis, wobei die wettbewerbsfähige Fähigkeit im rein textbasierten Coding erhalten bleibt. Noch wichtiger ist, dass unser Entwicklungsprozess praktische Einblicke in den Bau multimodaler Agenten bietet und dabei die zentrale Rolle der multimodalen Wahrnehmung, hierarchischer Optimierung sowie der zuverlässigen End-to-End-Verifizierung hervorhebt.
One-sentence Summary
GLM-5V-Turbo advances toward a native foundation model for multimodal agents by integrating multimodal perception directly into reasoning, planning, and tool execution rather than treating it as an auxiliary interface, which, alongside reinforcement learning and hierarchical optimization, yields strong performance in multimodal coding and visual tool use while maintaining competitive text-only coding capabilities.
Key Contributions
- Introduces GLM-5V-Turbo, a native multimodal foundation model that embeds visual and video perception directly into core reasoning, planning, and execution pipelines instead of treating it as an auxiliary interface.
- Establishes a training framework that utilizes reinforcement learning, trajectory diversity for hierarchical strategy emergence, and reliable end-to-end verification to jointly optimize model capabilities with agent harness architectures.
- Demonstrates strong performance in multimodal coding, visual tool use, and framework-based agentic tasks while preserving competitive text-only coding capabilities across comprehensive evaluations.
Introduction
As foundation models shift from passive language understanding to active real-world interaction, enabling agents to perceive, reason, and execute across heterogeneous inputs like images, videos, and graphical interfaces has become essential for software engineering and knowledge work. Prior systems typically treat multimodal perception as an auxiliary interface to a text model, which creates bottlenecks in long-horizon reasoning due to aggressive context consumption, reliance on handcrafted training trajectories, and the difficulty of faithfully compressing visual information. The authors introduce GLM-5V-Turbo, a native multimodal foundation model that tightly integrates vision and language throughout pre-training, supervised fine-tuning, and reinforcement learning. By deploying a specialized vision encoder, implementing multimodal multi-token prediction, and applying hierarchical optimization across dozens of agentic tasks, they deliver a system that excels in visual tool use and multimodal coding while preserving strong text-only performance. Their development process also yields practical guidelines for managing long-horizon visual context and co-designing model capabilities with agent harnesses.
Dataset
- Dataset Composition and Sources: The authors introduce ImageMining, a self-collected benchmark comprising 217 curated test cases derived from manually gathered trace samples. The data spans seven distinct domains: Social, Entertainment, Products, Places, Rich Text, Nature, and Science.
- Subset Details and Reasoning Categories: The benchmark organizes its cases into five core reasoning categories. Universal Recognition covers fine-grained identification of flora, fauna, and artifacts. Spatio-Temporal Reasoning handles geographic deduction grounded in visual cues. Event Reasoning focuses on news events and product launches. Text-based Reasoning processes embedded rich text such as academic papers and reports. Visual Search requires cross-referencing inputs to retrieve specific artworks or imagery.
- Training Usage and Processing Pipeline: The authors use this dataset to equip the GLM-5V-Turbo model through a multi-stage automated pipeline that handles knowledge discovery, question-answer reconstruction, and quality filtering. A central training constraint is the Visual Jump requirement, which mandates that intermediate reasoning hops must include visual transitions to prevent the model from relying on textual shortcuts or parametric knowledge.
- Cropping Strategy and Specialized Processing: The dataset includes a dedicated OCR Search subset targeting charts, maps, and posters. This subset enforces a strict processing workflow where the model must perform entity isolation and localized cropping or magnification before initiating search chains. This design transforms static images into interactive environments that demand precise on-image tool usage for deep visual exploration.
Method
The architecture of GLM-5V-Turbo integrates a novel vision encoder, multimodal token prediction, and a multi-stage training framework designed for agent-oriented tasks. At the foundation is CogViT, a parameter-efficient vision encoder developed for robust multimodal perception. It employs a two-stage pretraining process: the first stage uses distillation-based masked image modeling to strengthen visual representations by training a student Vision Transformer (ViT) to reconstruct masked regions from dual teacher models—SigLIP2 for semantic features and DINOv3 for texture details—using a quality-aware mixture of data. The second stage transitions to contrastive image-text pretraining, where the model aligns visual and textual features in a shared embedding space. This stage introduces three key enhancements: variable-size input processing via the NaFlex scheme, a scaled global batch size of 64K with sigmoid-based SigLIP loss and bidirectional distributed implementation, and training on an 8-billion bilingual (Chinese-English) image-text corpus. The vision encoder is coupled with a text encoder and a shared projection module, all optimized using the Muon optimizer with module-specific learning rates.

The multimodal input processing is handled through the Multimodal Multi-Token Prediction (MMTP) framework, an extension of the text-only MTP design. This mechanism is designed to maintain training and inference efficiency in multimodal settings. The core design decision revolves around how visual tokens are integrated into the MTP head. Three options were considered: directly passing visual embeddings, masking all visual tokens, or replacing visual tokens with a shared learnable <|image|> special token. The third option, which preserves positional information while standardizing visual input, was adopted. This design choice significantly reduces communication complexity in pipeline-parallel training by eliminating the need to propagate visual embeddings across stages, enhancing scalability and engineering maintainability. The effectiveness of this approach is demonstrated by lower training loss and more stable convergence compared to direct embedding passage, as shown in the training loss curves.
The model's capabilities are further developed through broad training across perception, reasoning, and agent tasks. Pretraining utilizes a mixture of plain text and multimodal data to foster balanced development, including categories such as world knowledge, OCR, coding, GUI, and spatial perception, with a particular emphasis on multimodal coding data to align visual understanding with code generation. This is followed by joint reinforcement learning (RL) optimization over more than 30 task categories. This multi-task RL setup leads to consistent improvements across diverse domains, including perceptual tasks like image grounding and video understanding, reasoning tasks such as STEM problem-solving, and agentic settings like GUI and coding agents. The RL process exhibits reduced cross-domain interference compared to supervised fine-tuning, allowing multiple capabilities to improve simultaneously, and facilitates the transfer of reasoning patterns across tasks. The training infrastructure is redesigned for scale, featuring unified task and reward abstraction, end-to-end asynchrony, fine-grained memory management, and topology-aware partitioning to handle the complexities of large-scale multimodal RL.
The model's capabilities are further extended through a multimodal toolchain that supports a complete perception–planning–execution loop. This includes proprietary tools like zai_-prefixed functions and compatibility with user-defined tools, enabling the model to perform tasks such as multimodal search, annotation, and webpage reading. This expansion is validated by significant performance gains on benchmarks like MMSearch-Plus and BrowseComp-VL. The model is also integrated with external agent frameworks like Claude Code and AutoClaw, serving as a cognitive core that bridges high-level reasoning with low-level system execution. This integration enables sophisticated agentic workflows, where the model acts as a vision-language controller for tasks involving complex terminals and GUIs.
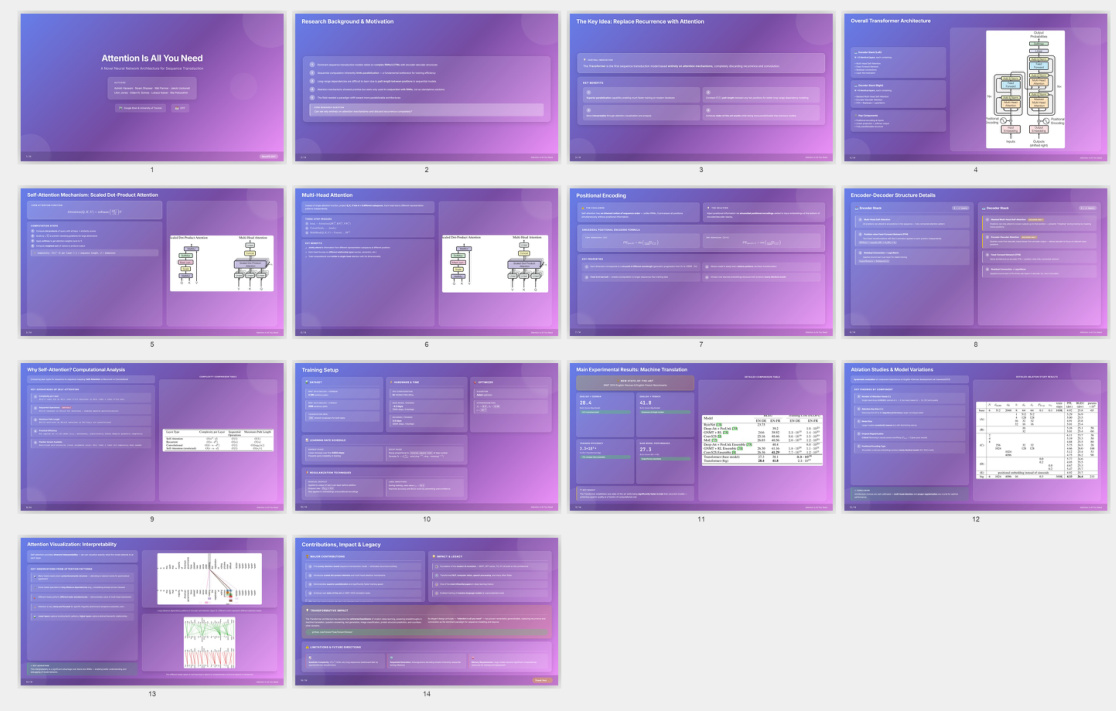
Finally, the model supports multimodal deep research and content creation, enabling workflows that involve iterative information gathering, evidence consolidation, and long-form synthesis from heterogeneous sources. It can generate text-image interleaved reports, create structured slide decks, and produce document-style write-ups by natively parsing visually rich webpages and documents. This capability is further supported by a set of official skills, which leverage the model's native abilities or wrap it as an external tool, making it easier to deploy within agent frameworks. The development process also yielded design lenses, emphasizing the foundational role of perception, the efficiency of hierarchical optimization, and the importance of clear task specification and reliable verification for end-to-end long-horizon tasks.
Experiment
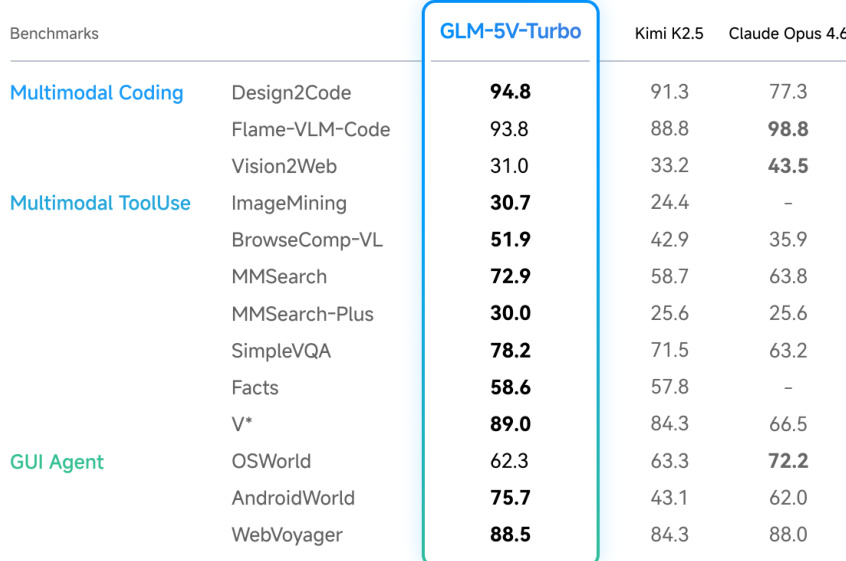
GLM-5V-Turbo is evaluated across multimodal coding, tool use, GUI agent, and text-only reasoning benchmarks to assess its integrated agentic capabilities. These experiments validate the model's proficiency in translating visual inputs into functional code, executing grounded interactions within agent frameworks, and performing complex multimodal search, document parsing, and precise spatial grounding tasks. Qualitative demonstrations consistently show that the model effectively transfers visual understanding into real-world end-to-end execution while maintaining robust text-based coding and reasoning performance. Ultimately, the evaluation confirms that GLM-5V-Turbo successfully achieves its core objective of building foundational multimodal agentic capabilities without compromising underlying text-first workflows.
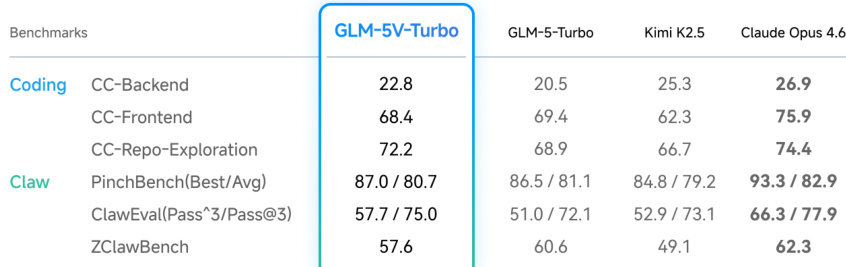
The authors evaluate GLM-5V-Turbo across coding and agent benchmarks, comparing its performance against several baseline models. Results show that GLM-5V-Turbo achieves strong results on multimodal coding and tool-use tasks while maintaining competitive performance on text-only coding and agent benchmarks, indicating a balanced capability across modalities. GLM-5V-Turbo performs strongly on multimodal coding benchmarks, outperforming other models in several categories. The model maintains solid performance on text-only coding and agent benchmarks, suggesting that visual capabilities do not undermine its core coding ability. GLM-5V-Turbo shows competitive results on execution-oriented agent tasks, indicating effective transfer of multimodal understanding to real-world agent applications.
The authors evaluate GLM-5V-Turbo across multimodal coding, tool-use, GUI agent, and text-only coding benchmarks, demonstrating strong performance in multimodal tasks such as UI-to-code generation and visual QA, while maintaining robust capabilities in pure-text coding. The model shows effective transfer to real-world agent frameworks, enabling end-to-end execution in vision-enabled environments. Results indicate that the integration of visual understanding enhances agent functionality without compromising foundational coding and reasoning abilities. GLM-5V-Turbo achieves strong performance on multimodal coding and tool-use tasks, including UI-to-code generation and visual QA. The model maintains solid coding performance on text-only benchmarks, indicating no degradation from adding visual capabilities. GLM-5V-Turbo demonstrates effective transfer to agent frameworks, enabling vision-based interaction and execution in real-world scenarios.
{"summary": "The authors conduct an experiment to investigate the relationship between incident and reflected angles in light reflection, observing the behavior of light rays on a reflective surface. Results show that the measured angles consistently align with the expected physical principle, demonstrating that the reflection angle matches the incident angle under varying conditions.", "highlights": ["The experiment demonstrates that the reflection angle consistently matches the incident angle across multiple trials.", "The setup allows for the observation of light path behavior on a reflective surface under different incident conditions.", "Results confirm the fundamental principle that the reflection angle is equal to the incident angle in a controlled environment."]
The authors evaluate GLM-5V-Turbo across multimodal coding, tool-use, and GUI agent benchmarks, showing strong performance in multimodal tasks such as coding and agent-oriented interactions while maintaining solid capabilities in text-only coding. The model demonstrates competitive results on both multimodal and text-based benchmarks, indicating effective transfer of visual understanding into practical agent execution. GLM-5V-Turbo achieves strong performance on multimodal coding and tool-use benchmarks, outperforming other models in several categories. The model shows competitive results on GUI agent benchmarks, indicating effective visual understanding for grounded interaction and action. GLM-5V-Turbo maintains solid performance on text-only coding tasks, suggesting that adding visual capabilities does not compromise its underlying coding ability.
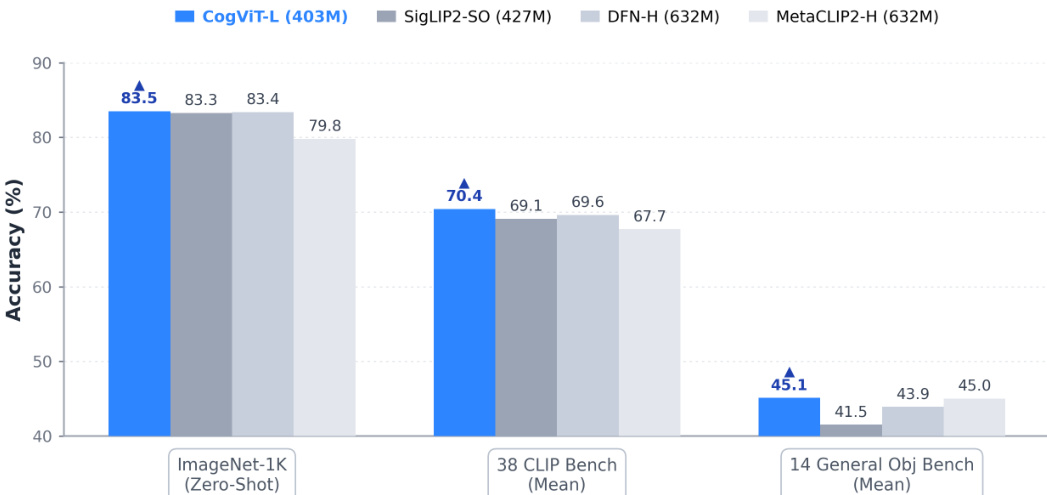
The chart compares the performance of GLM-5V-Turbo with other models across three benchmark categories, showing that GLM-5V-Turbo achieves high accuracy on ImageNet-1K and competitive results on CLIP and general object benchmarks. The model outperforms others on ImageNet-1K and maintains strong performance on the 38-CLIP benchmark while showing consistent results on the 14-general object benchmark. GLM-5V-Turbo achieves the highest accuracy on ImageNet-1K compared to other models. GLM-5V-Turbo shows strong performance on the 38-CLIP benchmark, closely matching or exceeding other models. GLM-5V-Turbo maintains competitive accuracy on the 14-general object benchmark relative to other models.
The evaluation tests GLM-5V-Turbo across multimodal coding, tool-use, GUI agent, and text-only benchmarks alongside standard vision recognition tasks to validate visual-to-code translation, autonomous agent execution, and the preservation of core text-based competencies. These experiments demonstrate that the model effectively bridges visual perception with practical workflows without experiencing performance degradation from multimodal integration. Qualitatively, the system exhibits robust adaptability, successfully leveraging visual inputs to enhance real-world task completion and grounded interaction. Ultimately, the findings confirm that integrating visual capabilities significantly expands functional versatility while maintaining foundational coding and reasoning stability.