Command Palette
Search for a command to run...
ReVSI: Neuordnung der Bewertung der visuellen räumlichen Intelligenz für eine präzise Beurteilung der 3D-Reasoning-Fähigkeiten von VLMs
ReVSI: Neuordnung der Bewertung der visuellen räumlichen Intelligenz für eine präzise Beurteilung der 3D-Reasoning-Fähigkeiten von VLMs
Yiming Zhang Jiacheng Chen Jiaqi Tan Yongsen Mao Wenhu Chen Angel X. Chang
Zusammenfassung
Die aktuelle Bewertung der räumlichen Intelligenz kann unter modernen Architekturen von Vision-Language-Modellen (VLMs) systematisch ungültig sein. Erstens leiten viele Benchmarks Frage-Antwort-Paare (QA-Paare) aus punktwolkenbasierten 3D-Annotationen ab, die ursprünglich für die traditionelle 3D-Wahrnehmung erstellt wurden. Wenn diese Annotationen als Goldstandard für die video-basierte Evaluation herangezogen werden, können Artefakte der Rekonstruktion und Annotation dazu führen, dass Objekte, die im Video deutlich sichtbar sind, übersehen werden, dass Objektidentitäten falsch klassifiziert werden oder dass geometrieabhängige Antworten (z. B. zur Größe) verfälscht werden, was zu fehlerhaften oder mehrdeutigen QA-Paaren führt. Zweitens gehen viele Evaluierungen vom Zugang zur gesamten Szene aus, während viele VLMs mit spärlich abgetasteten Bildern arbeiten (z. B. 16–64 Frames). Dadurch werden viele Fragen unter den tatsächlichen Eingabedaten des Modells effektiv unbeantwortbar.Wir verbessern die Validität der Evaluierung, indem wir ReVSI vorstellen, einen Benchmark und ein Protokoll, das sicherstellt, dass jedes QA-Paar unter den tatsächlichen Eingaben des Modells beantwortbar und korrekt ist. Zu diesem Zweck haben wir Objekte und Geometrie in 381 Szenen aus fünf Datensätzen neu annotiert, um die Datenqualität zu erhöhen, und alle QA-Paare unter Anwendung rigoroser Bias-Minderung sowie durch menschliche Verifizierung mit professionellen 3D-Annotierungstools neu generiert. Darüber hinaus erhöhen wir die Kontrollierbarkeit der Evaluierung, indem wir Varianten mit unterschiedlichen Frame-Budgets (16/32/64/alle) sowie detailliertere Metadaten zur Sichtbarkeit von Objekten bereitstellen, was kontrollierte diagnostische Analysen ermöglicht.Evaluierungen von allgemeinen und domänenspezifischen VLMs auf ReVSI zeigen systematische Ausfallmuster auf, die durch frühere Benchmarks verborgen blieben, und liefern so eine zuverlässigere und diagnostisch aufschlussreichere Einschätzung der räumlichen Intelligenz.
One-sentence Summary
ReVSI rebuilds spatial intelligence evaluation for vision-language models by re-annotating 381 scenes across five datasets to generate bias-mitigated, human-verified question-answer pairs aligned with sparse-frame inputs, while introducing configurable frame budgets and fine-grained visibility metadata to expose systematic reasoning failures obscured by prior benchmarks and enable reliable diagnostic assessment.
Key Contributions
- The paper introduces ReVSI, a benchmark and protocol that ensures all queries are strictly answerable using the model's actual visual inputs. This dataset is constructed by re-annotating objects and geometry across 381 scenes from five existing datasets and systematically regenerating questions with rigorous bias mitigation and human verification.
- The evaluation framework enhances diagnostic controllability by providing variants across multiple frame budgets and fine-grained object visibility metadata. It also implements a dummy-video protocol that systematically removes frames containing queried objects to isolate model reliance on specific visual evidence.
- Comprehensive testing on general and domain-specific vision-language models reveals systematic spatial reasoning failures that prior benchmarks obscured. The results demonstrate that proprietary models are frequently under-assessed on object counting, while fine-tuned variants exhibit high hallucination rates when critical visual frames are withheld.
Introduction
Vision-language models are rapidly being deployed to interpret complex three-dimensional environments, making rigorous evaluation of their spatial reasoning essential for applications in robotics, navigation, and spatial analysis. Previous benchmarks attempted to bridge this gap by projecting 3D mesh annotations onto video streams, but these static ground truths frequently misalign with actual frame-level visual evidence. This misalignment creates a validity gap that systematically obscures true model capabilities and masks issues like annotation bias and hallucination. The authors address these shortcomings by introducing ReVSI, a rebuilt evaluation framework that systematically re-annotates datasets, eliminates spatial bias, and establishes frame-aware testing protocols. By generating dummy videos that isolate specific objects, they reveal that prior benchmarks significantly misrepresent model performance and provide a more transparent, evidence-driven standard for measuring visual spatial intelligence.
Dataset
• Dataset Composition & Sources: The authors introduce ReVSI, a spatial intelligence benchmark constructed by re-annotating 381 indoor scenes sourced from five established 3D datasets: ScanNetv2, ScanNet++, ARKitScenes, 3RScan, and MultiScan. The dataset adopts an open vocabulary approach, expanding object labeling diversity to over 500 categories while maintaining a long-tailed distribution that reduces reliance on common category priors.
• Subset Details & Filtering Rules: The benchmark organizes spatial reasoning into object counting, size estimation, absolute and relative distance, relative direction, and room size estimation, explicitly excluding the Object Appearance Order task due to its temporal focus. The dataset provides four frame budget variants (16, 32, 64, and all-frame) to evaluate models under realistic sampling constraints. To ensure answerability and reduce bias, the authors apply strict filtering rules: ambiguous categories like footwear are removed, fixed-dimension objects are excluded from size estimation, and short-distance queries are filtered out for distance tasks. Positioning objects exceeding one square meter are also discarded to prevent ambiguous directional reasoning.
• Data Processing & Usage: The benchmark is designed strictly for evaluation rather than model training. The authors completely regenerate question-answer pairs using refined templates and enforce comprehensive human verification. Frame subsets are constructed through hierarchical uniform sampling, ensuring nested structures where lower budgets are strict subsets of higher ones while maintaining consistent temporal coverage. During evaluation, questions are only retained if they remain answerable under the specific frame budget, and dummy videos are generated to stress-test whether models rely on visual evidence or memorized scene priors.
• Cropping, Metadata & Additional Processing: The pipeline incorporates several specialized processing steps to guarantee precision. The authors initialize gravity-aligned oriented bounding boxes algorithmically before manually refining them for tight spatial localization. Object visibility metadata is generated by projecting 3D masks into video frames using camera trajectories, marking objects as visible when their pixel coverage exceeds five percent, with manual verification for edge cases. Auxiliary 2D bounding boxes are computed via ray casting to guide annotators but are not used for final ground truth. Room boundaries are manually traced from orthogonal top-down views, and all source videos are standardized to 640 by 480 resolution at 10 frames per second, with invalid camera poses discarded and orientation metadata manually corrected. Tight image crops are also extracted for automated label verification, ensuring high annotation fidelity.
Method
The authors leverage a reimagined benchmark framework, ReVSI, designed to address critical evaluation pitfalls in spatial reasoning assessments for vision-language models. Central to this approach is ensuring strict consistency between what the model observes in its input and what the benchmark questions require. This is achieved through a comprehensive redesign of both the data annotation and evaluation pipeline. As shown in the figure below, ReVSI introduces a more rigorous and diverse set of question types across multiple spatial reasoning categories, including object counting, room size estimation, and relative distance and direction tasks. The framework emphasizes high-fidelity annotations derived from raw video inputs, which are re-annotated using professional 3D tools to eliminate ground-truth drift caused by reliance on imperfect 3D reconstructions. This ensures that object labels, identities, and geometric properties like size and spatial relationships are accurately aligned with the visual evidence available in the video frames.
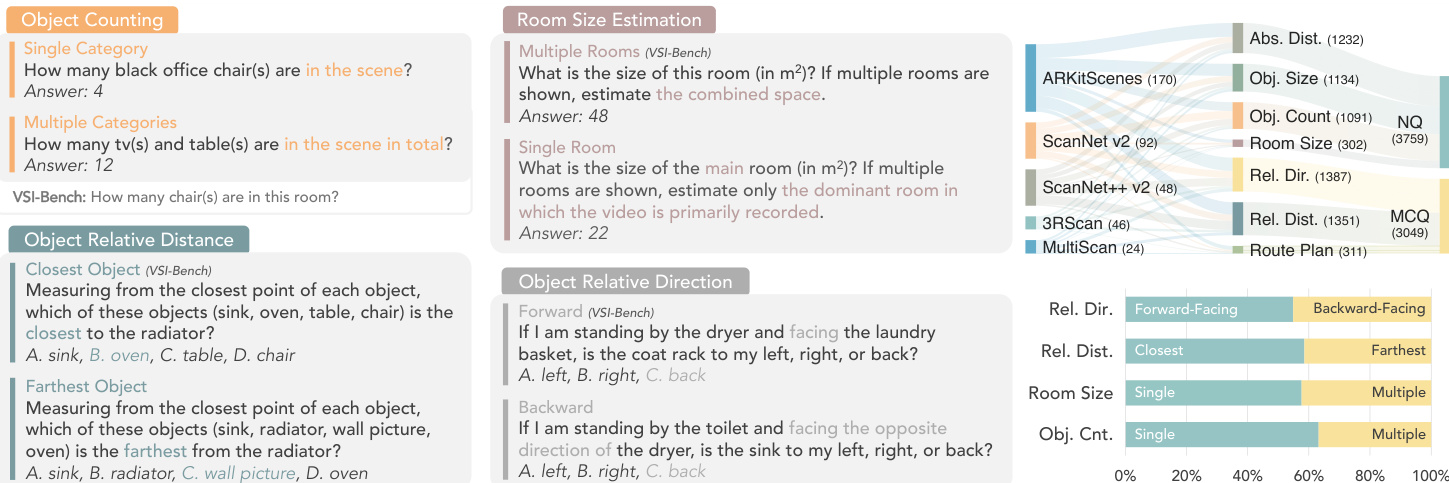
Experiment
The evaluation assesses open-source, proprietary, and specialized spatial reasoning models using ReVSI, a benchmark featuring more precise room polygons and 3D object annotations than prior datasets. Supplementary experiments validate model robustness across different frame-sampling rates and reveal consistent qualitative asymmetries in spatial reasoning capabilities. Specifically, models perform more reliably when processing single objects rather than multiple ones, identifying closest targets instead of farthest ones, and interpreting forward directions compared to backward ones. These results underscore the enhanced annotation quality of ReVSI while highlighting systematic limitations in current vision-language models for complex 3D spatial tasks.
The authors evaluate various models on spatial reasoning tasks using a benchmark with refined annotations, comparing performance across different model types and frame sampling rates. Results show that proprietary models generally outperform open-source models, with notable differences in accuracy depending on task type and the number of visual frames provided. Proprietary models achieve higher accuracy than open-source models across most tasks in the evaluation. Performance varies significantly with the number of frames used, with higher frame counts generally leading to better results. Models show systematic asymmetries in performance, such as better accuracy on single-object counting compared to multiple-object counting and easier handling of forward-facing directional queries than backward-facing ones.
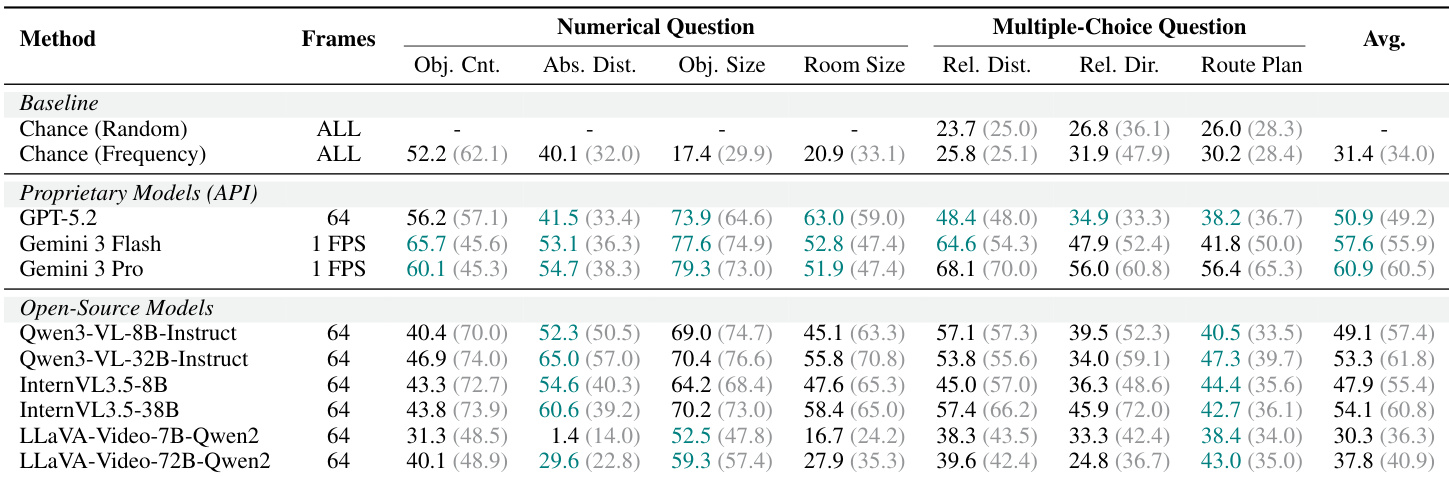
The authors compare their ReVSI benchmark with VSI-Bench, highlighting differences in annotation methods and frame sampling strategies. ReVSI uses manual annotations for more accurate room and object definitions, while VSI-Bench relies on automated methods. The evaluation includes multiple frame sampling settings to assess model performance under varying visual evidence. ReVSI employs manual annotations for more accurate room and object definitions compared to VSI-Bench's automated methods. ReVSI supports multiple frame sampling settings including 16, 32, and 64 frames, while VSI-Bench uses all available frames. ReVSI includes frame-adaptive question answering, which is not present in VSI-Bench.

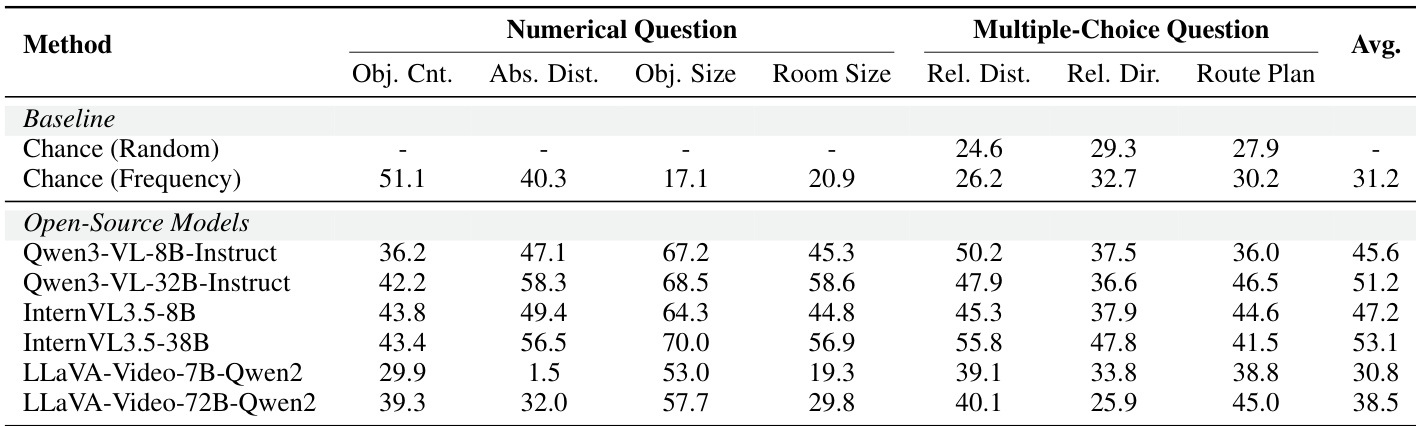
The authors evaluate various models on spatial reasoning tasks using the ReVSI benchmark, comparing performance across numerical and multiple-choice question types. Results show that open-source models generally outperform baseline random and frequency-based approaches, with variations in performance depending on the specific task and model architecture. Open-source models achieve higher performance than baseline methods across most tasks in the ReVSI benchmark. Performance varies significantly across different types of spatial reasoning tasks, with some tasks showing notably higher accuracy than others. Among open-source models, certain configurations demonstrate stronger performance in numerical questions compared to multiple-choice questions.
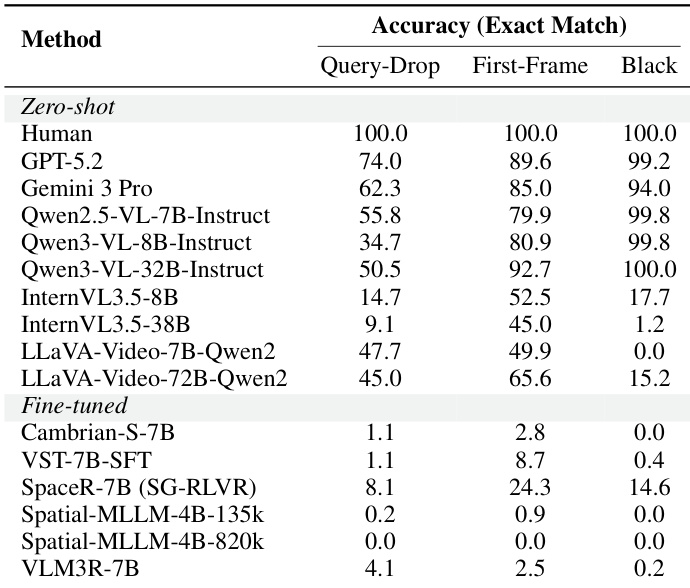
The authors evaluate a range of open-source, proprietary, and fine-tuned models on spatial reasoning tasks using the ReVSI benchmark, focusing on accuracy across different query types and input conditions. Results show that human performance is perfect across all conditions, while models exhibit significant variation, with proprietary models generally outperforming open-source ones, and fine-tuned models showing mixed results depending on the task and input format. Human performance achieves perfect accuracy across all query types and input conditions. Proprietary models generally outperform open-source models, with some achieving high accuracy on specific conditions. Fine-tuned models show low accuracy on most tasks, indicating limited improvement over zero-shot baselines.
The authors evaluate model performance across different frame sampling rates, showing that higher frame counts generally improve accuracy for most task types. Results indicate consistent trends in model capabilities, with some tasks showing stronger performance at higher frame counts while others remain stable or vary based on the complexity of the spatial reasoning required. Model performance improves with higher frame sampling rates for most task types, indicating the importance of visual evidence in spatial reasoning. Certain tasks like object counting and relative distance estimation show significant accuracy gains at higher frame counts, while others remain relatively stable. The evaluation reveals systematic differences in model performance across task variants, such as single vs. multiple object counting and forward vs. backward directional queries.
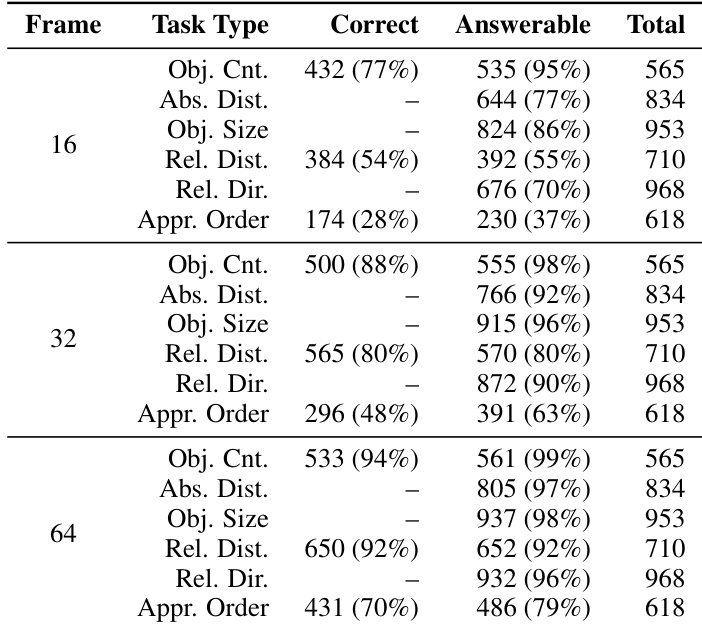
The evaluation setup utilizes the ReVSI benchmark with manually annotated spatial reasoning tasks to assess how varying frame sampling rates and query types impact model performance. These experiments validate the influence of visual evidence density and architectural differences, demonstrating that increased frame counts consistently enhance reasoning accuracy, particularly for counting and distance estimation. Qualitatively, proprietary models outperform open-source alternatives, while fine-tuned approaches yield minimal improvements over zero-shot baselines. The results further reveal systematic performance asymmetries tied to query direction and object complexity, highlighting a substantial gap between current AI capabilities and perfect human spatial reasoning.