Command Palette
Search for a command to run...
EnergAIzer: Schnelles und präzises GPU-Leistungsabschätzungs-Framework für KI-Arbeitslasten
EnergAIzer: Schnelles und präzises GPU-Leistungsabschätzungs-Framework für KI-Arbeitslasten
Kyungmi Lee Zhiye Song Eun Kyung Lee Xin Zhang Tamar Eilam Anantha P. Chandrakasan
Zusammenfassung
Da KI-Anwendungen den Stromverbrauch von Rechenzentren erhöhen, ist eine präzise Leistungsabschätzung von GPUs entscheidend für ein proaktives Energiemanagement. Bisherige Leistungsmodelle stehen jedoch vor einem Skalierbarkeitsengpass, der nicht in den Modellierungstechniken selbst, sondern in der Beschaffung der erforderlichen Eingabewerte zur Hardware-Auslastung liegt. Herkömmliche Ansätze stützen sich entweder auf kostspielige Simulationen oder Hardware-Profiling, was sie bei der Notwendigkeit schneller Vorhersagen unpraktikabel macht. Diese Arbeit stellt EnergAIzer vor, das diesen Skalierbarkeitsengpass adressiert, indem es eine leichte Lösung zur Vorhersage der Auslastungseingabewerte entwickelt und die Schätzungs-Wartezeit von Stunden auf Sekunden reduziert. Unsere zentrale Erkenntnis ist, dass Kernels in KI-Anwendungen häufig Optimierungen einsetzen, die strukturierte Muster erzeugen, die den Speichertraffic und die Ausführungszeitlinie analytisch bestimmen. Wir konstruieren ein Leistungsmodell, das diese Muster als analytische Grundlage für die Anpassung empirischer Daten verwendet, wodurch auch die modulebene Auslastung natürlich sichtbar wird. Diese vorhergesagte Auslastung wird dann in unser Leistungsmodell eingespeist, um den dynamischen Stromverbrauch zu schätzen. EnergAIzer erzielt auf NVIDIA Ampere GPUs einen Leistungsfehler von 8 %, was mit traditionellen Leistungsmodellen, die auf aufwändiger cycle-level Simulation oder Hardware-Profiling basieren, wettbewerbsfähig ist. Wir demonstrieren die Erkundungsfähigkeiten von EnergAIzer für Frequenzskalierung und architektonische Konfigurationen, einschließlich der Vorhersage des Stromverbrauchs der NVIDIA H100 mit nur 7 % Fehler. Zusammenfassend bietet EnergAIzer eine schnelle und präzise Leistungsvorhersage für KI-Anwendungen und ebnet den Weg für energiebewusste Design-Explorationen.
One-sentence Summary
EnergAIzer addresses the scalability bottleneck in estimating dynamic GPU power consumption for AI workloads by predicting hardware utilization inputs through structured kernel patterns rather than costly simulation or hardware profiling, reducing estimation wait time from hours to seconds with 8% power error on NVIDIA Ampere GPUs and 7% error on NVIDIA H100 to enable rapid power-aware design explorations.
Key Contributions
- This work presents EnergAIzer, a lightweight solution that predicts hardware utilization inputs to reduce estimation waittime from hours to seconds. The system eliminates the need for costly simulation or hardware profiling required by conventional approaches.
- The method constructs a performance model using structured patterns common in AI workload kernels as an analytical scaffold for empirical data fitting. This approach determines memory traffic and execution timelines analytically while naturally exposing module-level utilization for accurate power estimation.
- Experiments demonstrate that EnergAIzer achieves 8% power errors on NVIDIA Ampere GPUs, remaining competitive with traditional models requiring elaborate cycle-level simulation. The framework also supports exploration of frequency scaling and architectural configurations, successfully forecasting power for NVIDIA H100 with just 7% error.
Introduction
AI workloads are driving significant increases in datacenter power consumption, making accurate GPU power estimation essential for optimizing resource allocation and hardware design. Traditional power models rely on costly cycle-level simulations or physical hardware profiling to obtain necessary utilization inputs, creating a scalability bottleneck that hinders rapid design exploration. Existing lightweight performance models fail to capture the specific module activity and memory hierarchy details required for accurate power prediction. The authors present EnergAIzer, a framework that leverages structured optimization patterns inherent in AI kernels to analytically predict hardware utilization without simulation, reducing estimation time from hours to seconds while maintaining competitive accuracy.
Dataset
- Dataset Composition and Sources: The authors provide a pre-collected database for empirical fitting and ground-truth measurements to validate predictions. These artifacts are hosted on the EnergAIzer Github repository and the Zenodo archive.
- Key Details: The data supports single kernel-level power and latency estimations as well as end-to-end estimations for AI workloads. Scripts are included to reproduce experiments for diverse AI workloads and GPU configuration exploration.
- Data Usage: The database is used for empirical fitting while the measurements serve for validation. The framework allows users to adapt the artifacts for GPU power and energy predictions.
- Processing and Requirements: Execution requires Python3 within a virtual environment on x86-64 or Arm machines. Users need 200 MB of disk space and Linux or Mac OS environments. GPU machines are not required unless customizing the database collection.
Method
The EnergAIzer framework is designed to predict latency and power consumption for AI workloads on GPUs by separating one-time offline training from rapid online inference. The system takes an AI workload, GPU architecture configurations, and power settings as inputs to generate end-to-end latency and average power estimates. A critical component of this workflow is the Kernel Configuration Predictor, which uses a decision tree trained on an offline database to infer optimization parameters like tiling and pipelining from tensor shapes, eliminating the need for physical profiling during inference.
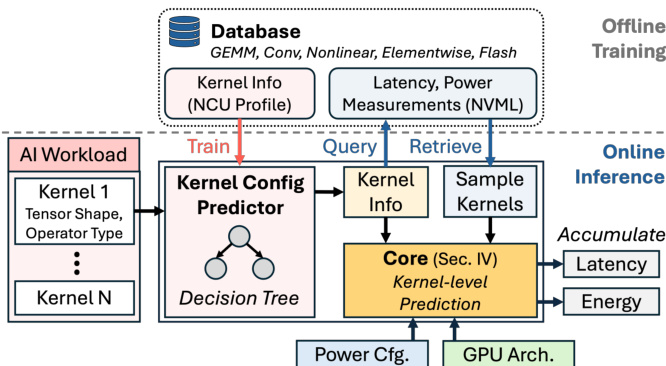
At the heart of the system lies the EnergAIzer Core, which performs kernel-level predictions through a three-stage pipeline. As illustrated in the framework diagram, the core processes kernel information, GPU architecture details, and power configurations through an Abstraction module, a Performance Model, and finally a Power Model to output latency and power estimates.
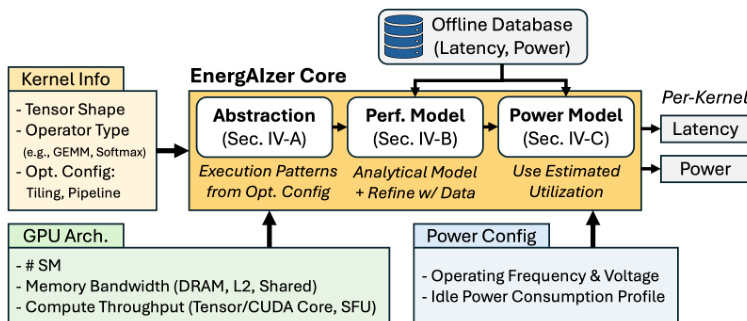
The Abstraction module establishes a workload representation based on common software optimization choices found in dominant AI kernels like GEMM, Softmax, and FlashAttention. Tensors are hierarchically partitioned into tiles at threadblock, warp, and instruction levels, which determine memory traffic and work distribution. For instance, threadblock-level tiles dictate global memory traffic and SM distribution, while warp-level tiles define shared memory usage. The authors analytically derive memory traffic for DRAM, L2 cache, and shared memory based on these tiling parameters and ideal threadblock swizzling. This analytical approach aligns closely with measured hardware counter values, as shown in the validation plots for various kernel types.
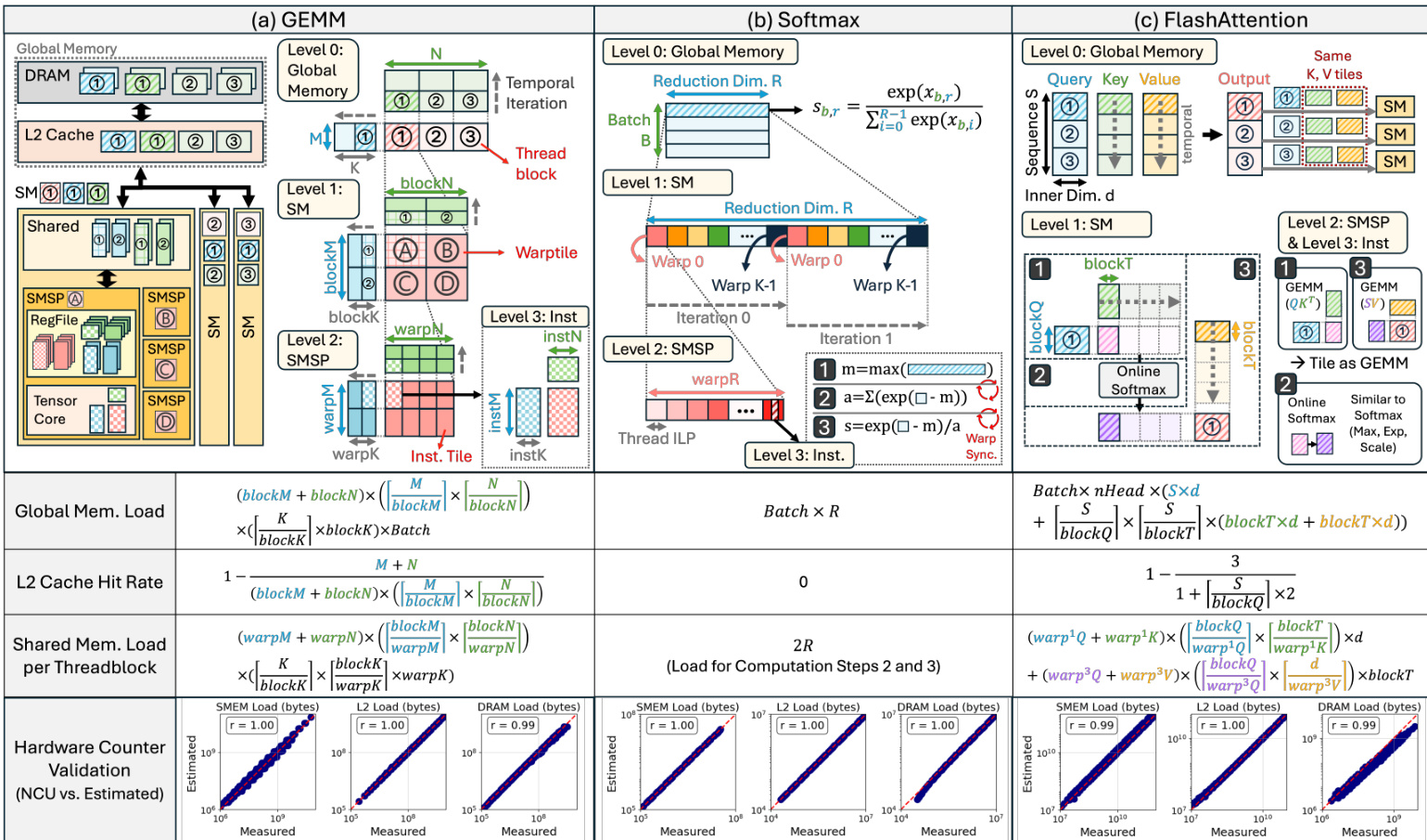
Following abstraction, the Performance Model constructs a coarse-grained execution timeline to expose module-level utilization. This timeline maps actions such as data loads, stores, and computations, determining their overlap based on pipelining strategies. For example, in GEMM kernels, multi-stage pipelines allow global memory loads to overlap with shared memory loads and Tensor Core computations to hide latency. The ideal latency for an action is calculated as the amount of work divided by the module bandwidth or concurrency. To address secondary effects like kernel launch overhead or memory bank conflicts that are difficult to model analytically, the authors apply empirical corrections. The corrected latency is computed as t^corrected=λ×tideal+ε, where coefficients are fitted to an offline database to minimize prediction error. The timeline construction for different kernels, including the distinct phases of prologue, mainloop, and epilogue, is visualized in the execution timeline diagrams.
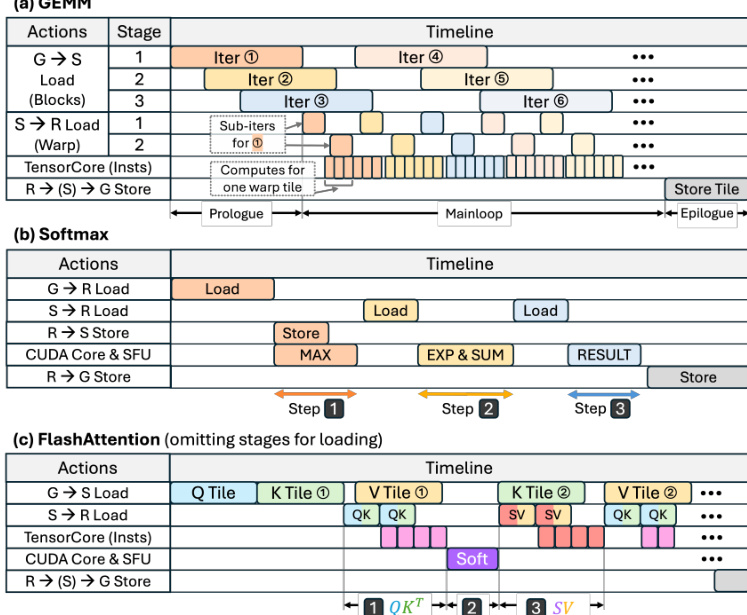
Finally, the Power Model utilizes the derived timeline to estimate power consumption. Module-level utilization is computed as the ratio of a module's active time to the total kernel latency, where active time is the sum of latencies of all actions engaging that module. This utilization information, combined with the power configuration settings such as operating frequency and voltage, allows the system to estimate dynamic power. The offline training process involves collecting latency and power measurements via NVML and kernel information via NCU to train the decision tree and fit the empirical correction coefficients, ensuring high accuracy across diverse tensor shapes and kernel types without requiring runtime profiling.
Experiment
EnergAIzer is evaluated on NVIDIA A100 and A10 GPUs using diverse language and vision workloads to validate its latency and power estimation accuracy alongside design space exploration capabilities. The experiments demonstrate that the framework achieves competitive prediction errors while offering orders of magnitude faster inference times compared to traditional hardware profiling tools. Furthermore, the system successfully forecasts performance for new GPU architectures and algorithmic configurations such as voltage-frequency scaling and precision changes without requiring new data collection.
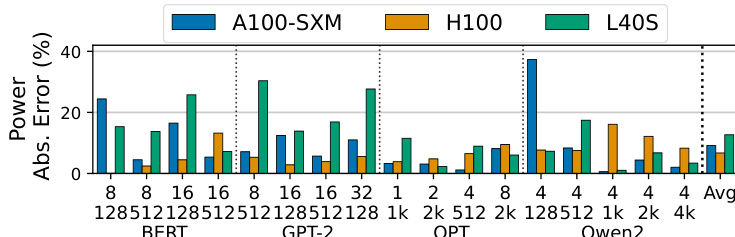
The authors evaluate the power estimation accuracy of their framework across different GPU architectures, specifically comparing A100-SXM, H100, and L40S models. The results demonstrate the model's ability to generalize across generations, although accuracy varies depending on the specific hardware architecture and memory technology used. The chart displays power estimation errors for A100-SXM, H100, and L40S GPUs across BERT, GPT-2, OPT, and Qwen2 models. L40S generally shows higher error rates than the other two architectures, particularly in GPT-2 and OPT configurations. H100 demonstrates competitive error rates, often lower than the A100-SXM baseline, indicating robust cross-generation prediction capabilities.
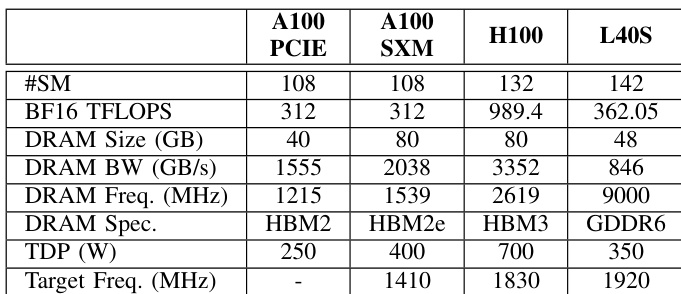
The authors present a comparison of hardware specifications for four different GPU architectures to demonstrate their framework's capability in exploring design choices. The data contrasts the A100 variants with newer generations like the H100 and L40S, highlighting differences in compute throughput and memory technology. This setup allows the system to test power prediction accuracy across both similar and distinct hardware generations. The specifications cover compute performance, memory capacity, and power limits for four distinct GPU models. Newer architectures like the H100 exhibit substantially higher compute throughput and memory bandwidth compared to the A100 series. The L40S configuration is distinct in its use of GDDR6 memory, unlike the HBM variants found in the other listed GPUs.
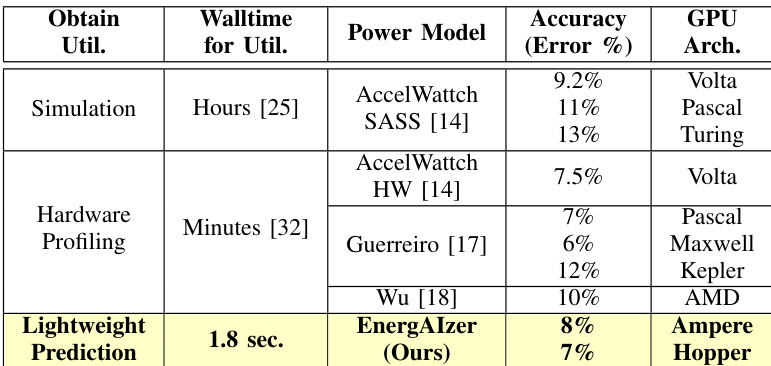
The the the table compares the time costs of simulation-based estimation and NCU profiling across different deep learning models. Simulation approaches are shown to be the most time-consuming, taking hours to complete, whereas NCU profiling is faster but still requires minutes. This data supports the paper's argument that existing methods have impractical walltimes compared to the proposed lightweight framework. Simulation-based estimation requires significantly more time than NCU profiling for the tested models. NCU profiling duration scales with the model, taking the longest time for the Qwen2 model. The simulation method was not applicable for the Qwen2 model, indicated by a missing value.
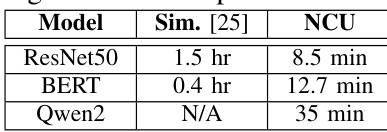
The authors compare their lightweight prediction method against simulation and hardware profiling baselines, demonstrating a drastic reduction in walltime from hours or minutes to seconds. The proposed approach achieves competitive accuracy on modern GPU architectures like Ampere and Hopper, whereas prior methods are often restricted to older generations or require significantly longer processing times. Prediction time is reduced to seconds, offering a massive speedup over methods requiring minutes or hours. The framework supports recent GPU architectures like Ampere and Hopper, unlike baselines limited to older generations. Accuracy remains low and competitive, performing better than simulation and comparably to hardware profiling.
The evaluation assesses power estimation accuracy across diverse GPU architectures including A100, H100, and L40S, demonstrating the framework's ability to generalize across hardware generations despite varying error rates. Experiments comparing simulation and profiling baselines reveal that existing methods incur impractical walltimes, whereas the proposed lightweight approach offers a drastic reduction in prediction latency. Overall, the framework maintains competitive accuracy on modern architectures while significantly outperforming prior methods in both speed and hardware compatibility.