Command Palette
Search for a command to run...
DR-Venus: Hin zu frontier-orientierten Deep Research Agents im Edge-Scale-Bereich mit nur 10K Open Data
DR-Venus: Hin zu frontier-orientierten Deep Research Agents im Edge-Scale-Bereich mit nur 10K Open Data
Zusammenfassung
Edge-Scale Deep Research agents, die auf kleinen Sprachmodellen basieren, sind aufgrund ihrer Vorteile in Bezug auf Kosten, Latenz und Datenschutz äußerst attraktiv für den realen Einsatz. In dieser Arbeit untersuchen wir, wie man einen leistungsfähigen kleinen Deep Research agent unter der Beschränkung auf begrenzten Open-Source-Daten trainiert, indem sowohl die Datenqualität als auch die Datennutzung verbessert werden. Wir präsentieren DR-Venus, einen wegweisenden 4B Deep Research agent für die Edge-Scale-Bereitstellung, der vollständig auf Open Data basiert.Unser Trainingsrezept besteht aus zwei Phasen. In der ersten Phase nutzen wir agentic Supervised Fine-Tuning (SFT), um grundlegende agentic Fähigkeiten zu etablieren. Dabei kombinieren wir strikte Datenbereinigung mit dem Resampling von Long-Horizon-Trajektorien, um die Datenqualität und -nutzung zu optimieren. In der zweiten Phase wenden wir agentic Reinforcement Learning (RL) an, um die Ausführungssicherheit bei komplexen Deep-Research-Aufgaben mit langem Zeithorizont (Long-Horizon Tasks) weiter zu steigern. Um RL in diesem Szenario für kleine agents effektiv zu gestalten, bauen wir auf IGPO auf und entwerfen Turn-Level-Rewards, die auf Informationsgewinn (Information Gain) und formatbewusster Regularisierung basieren, wodurch die Überwachungsdichte (Supervision Density) und die Zuordnung von Erfolg/Misserfolg auf Ebene einzelner Interaktionsschritte (Turn-Level Credit Assignment) verbessert werden.DR-Venus-4B, das vollständig auf etwa 10.000 Open-Data-Samples trainiert wurde, übertrifft in mehreren Deep-Research-Benchmarks frühere agentic Modelle mit weniger als 9B Parametern deutlich und verringert gleichzeitig den Abstand zu wesentlich größeren Systemen der 30B-Klasse. Unsere weiterführenden Analysen zeigen, dass 4B agents bereits ein überraschend starkes Leistungspotenzial besitzen, was sowohl das Einsatzversprechen kleiner Modelle als auch den Wert von Test-Time Scaling in diesem Kontext unterstreicht. Wir stellen unsere Modelle, den Code und die wichtigsten Trainingsrezepturen zur Verfügung, um die reproduzierbare Forschung an Edge-Scale Deep Research agents zu unterstützen.
One-sentence Summary
The Venus Team introduces DR-Venus, a frontier 4B deep research agent designed for edge-scale deployment that utilizes only 10K open data samples through a two-stage training recipe consisting of agentic supervised fine-tuning and agentic reinforcement learning based on information gain and format-aware regularization to significantly outperform prior models under 9B parameters and approach the performance of 30B-class systems.
Key Contributions
- The paper introduces DR-Venus, a 4B parameter deep research agent designed for edge-scale deployment that is trained entirely on approximately 10K open-source data samples.
- The researchers develop a two-stage training recipe consisting of agentic supervised fine-tuning (SFT) using cleaned and resampled long-horizon trajectories, followed by agentic reinforcement learning (RL) that utilizes turn-level rewards based on information gain and format-aware regularization.
- Experimental results demonstrate that DR-Venus-4B significantly outperforms existing agentic models under 9B parameters on multiple deep research benchmarks and narrows the performance gap compared to much larger 30B-class systems.
Introduction
Deep research agents capable of iterative search and evidence synthesis are essential for complex information-seeking tasks, yet deploying them on edge devices requires small language models to optimize for cost, latency, and privacy. Current state-of-the-art research agents typically rely on massive parameter counts or closed-source datasets, leaving a gap in high-performance, small-scale agents trained on open data. Small models are particularly vulnerable to noisy training trajectories and face significant challenges during reinforcement learning, where sparse rewards often lead to training instability. The authors address these issues by introducing DR-Venus, a 4B parameter agent trained through a two-stage process of agentic supervised fine-tuning with trajectory resampling and agentic reinforcement learning using turn-level rewards. This approach significantly improves data utilization and supervision density, allowing the 4B model to outperform larger models under 9B parameters and narrow the performance gap with 30B-class systems.
Dataset

The authors developed the DR-Venus dataset to train edge-scale deep research agents using a highly curated selection of open-source data. The dataset details are as follows:
- Dataset Composition and Sources: The authors start with 10,001 raw REDSearcher trajectories. After a multi-stage cleaning and refinement process, the final training set consists of 18,745 instances.
- Data Processing and Filtering:
- Environment Alignment: All trajectories are converted into a standardized interaction format, including specific message schemas, system prompts, and tool-call/response protocols to ensure consistency between training and online inference.
- Tool Pruning and Deduplication: To match the deployment environment, the authors remove all tool interactions except for search and browse. They prune disallowed tool calls at the turn level rather than discarding entire trajectories. They also remove 15,728 duplicate tool interactions, primarily redundant browse events. This stage leaves 10,000 valid trajectories.
- Correctness Filtering: The authors use Qwen3-235B-A22B-Instruct-2507 as a judge model to verify the accuracy of the final answers. This step retains 9,365 high-quality trajectories.
- Training Strategy and Resampling: To emphasize the long-horizon planning required for deep research, the authors employ a turn-aware resampling strategy during SFT. They assign sampling weights of 1x for trajectories with 0 to 50 turns, 2x for 51 to 100 turns, and 5x for trajectories exceeding 100 turns. This process expands the final training set to 18,745 instances and significantly increases the proportion of long-horizon trajectories (those with over 100 turns) from 13.29% to 33.21%.
Method
The authors leverage a two-stage training framework to develop DR-Venus, a deep research agent capable of solving complex information-seeking tasks through long-horizon interaction with external environments. The overall approach is structured around two complementary objectives: improving training data quality and enhancing data utilization. The framework begins with a formulation of the deep research task as a long-horizon reasoning-and-acting problem, where the agent must iteratively reason, invoke tools, gather evidence, and produce a final answer. This process is grounded in a formal environment E equipped with executable actions A, including search, browse, and answer actions. At each turn t, the agent generates a turn output ut=(τt,at), where τt represents the intermediate reasoning and at is the corresponding tool or answer action. The interaction history h<t is updated based on the agent's output and the environment's response, forming a trajectory H that captures the full sequence of reasoning, actions, and observations.
The first stage of the training pipeline is agentic supervised fine-tuning (SFT), which initializes the model with basic agentic capabilities. The authors use trajectories from REDSearcher, a previously established system, but apply a multi-stage data filtering and construction pipeline to mitigate redundancy, structural mismatches, and noisy supervision. The cleaned trajectories are serialized into autoregressive sequences, and the model is trained using a standard next-token prediction objective, with the loss computed only over the agent-generated tokens—specifically, the reasoning traces τt and actions at—while masking out environment observations ot. This ensures that the model learns the structured interaction pattern of reasoning, tool use, and answer generation without being distracted by irrelevant or noisy environmental data. The SFT stage provides a stable foundation for long-horizon interaction, enabling the model to effectively utilize limited open-data supervision.
The second stage employs agentic reinforcement learning (RL) to refine the model’s performance and address residual failure modes such as formatting errors, redundant reasoning, and inefficient tool use. To overcome the scarcity of high-quality open-source RL data, the authors adopt Information Gain-based Policy Optimization (IGPO), an algorithm that constructs dense turn-level reward signals to improve data efficiency. The core of this approach is the information gain (IG) reward, which evaluates each turn based on how much it increases the model's probability of generating the ground truth answer. Formally, the IG reward for turn t is defined as the difference in the log probability of the ground truth sequence under the current policy before and after the turn, capturing the extent to which the turn contributes to improved confidence in the correct answer. This reward is computed only for non-answer turns, with the answer turn relying on outcome rewards based on correctness.
To further enhance the reward design, the authors introduce a browse-aware IG assignment strategy, which computes IG rewards exclusively on browse turns and propagates them to all preceding search turns since the last browse action. This reflects the differing informational value of browse and search actions in deep research tasks. Additionally, a turn-level format penalty is applied to ensure consistent formatting across all turns, avoiding the coarse-grained penalties that can unfairly penalize correctly formatted turns in long trajectories. The format-adjusted rewards are then normalized within each rollout group to balance the scales of turn-level IG and outcome rewards, and an optional IG-Scale mechanism adaptively rescales the IG rewards to maintain balance in the presence of weak outcome supervision.
The final reward signal is a discounted cumulative reward R~i,t, which incorporates future reward information by applying a discount factor γ to the normalized and scaled turn-level rewards. This dense supervision signal is assigned to every token in the policy-generated output at turn t, enabling effective credit assignment across the interaction horizon. The policy optimization is performed using the IGPO objective, which combines a GRPO-style approach with turn-level credit assignment. The objective function includes a clipped surrogate term to ensure stable updates and a KL divergence penalty to prevent excessive deviation from the reference policy. This comprehensive reward and optimization framework enables DR-Venus to achieve improved execution reliability and push performance toward the frontier of long-horizon agentic tasks.
Experiment
The researchers evaluated DR-Venus across six benchmarks covering deep research, web browsing, and multi-step information seeking to validate the effectiveness of an agentic SFT and RL training pipeline. Results demonstrate that high-quality supervised fine-tuning on open data allows a small 4B model to establish a strong baseline that rivals much larger agents, while agentic RL further enhances reliability, tool-use stability, and long-horizon performance. Ultimately, the findings suggest that effective data utilization and dense reward designs can compensate for model scale, enabling edge-scale agents to achieve highly competitive research capabilities.
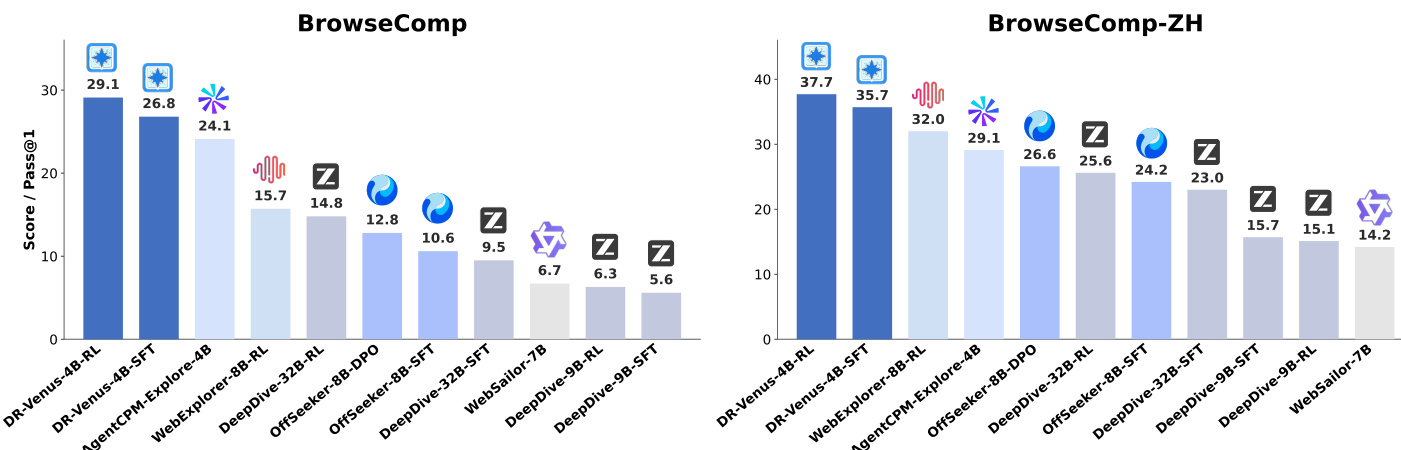
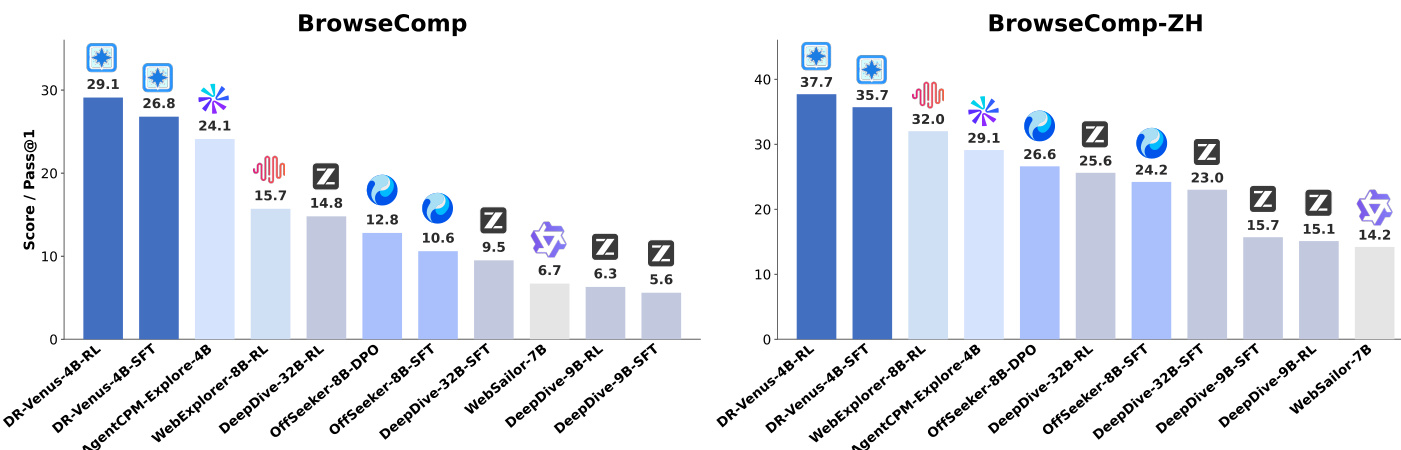
The authors compare DR-Venus, a small-model agent, against various baselines on two benchmarks, showing that DR-Venus-4B-SFT establishes a strong baseline and DR-Venus-4B-RL further improves performance. The results indicate that effective training on open data and reinforcement learning can enable small models to achieve competitive performance, often surpassing larger models, particularly in long-horizon tasks requiring deep research and tool use. DR-Venus-4B-SFT outperforms several 4B–9B agents and matches or exceeds larger 30B-scale models on multiple benchmarks. Agentic RL improves performance across most benchmarks, with gains linked to better formatting and more reliable tool use. DR-Venus-4B-RL achieves high performance on BrowseComp-ZH, surpassing larger models and demonstrating strong capability under test-time scaling.
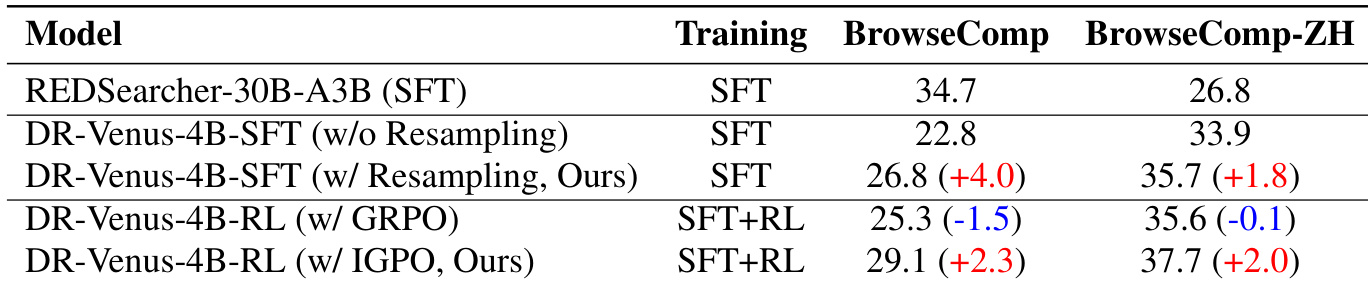
The authors compare the performance of DR-Venus models with different training configurations on two benchmarks, highlighting the impact of resampling and reinforcement learning. Results show that adding resampling during supervised fine-tuning improves performance over the baseline, and that reinforcement learning with IGPO further enhances results, particularly on BrowseComp. The improvements are attributed to better tool use and more reliable long-horizon execution. Resampling during supervised fine-tuning improves performance over the baseline on both benchmarks. Reinforcement learning with IGPO leads to consistent gains, while GRPO shows little to no improvement. The model's performance is strongly correlated with effective tool use, particularly browsing, which is enhanced by reinforcement learning.
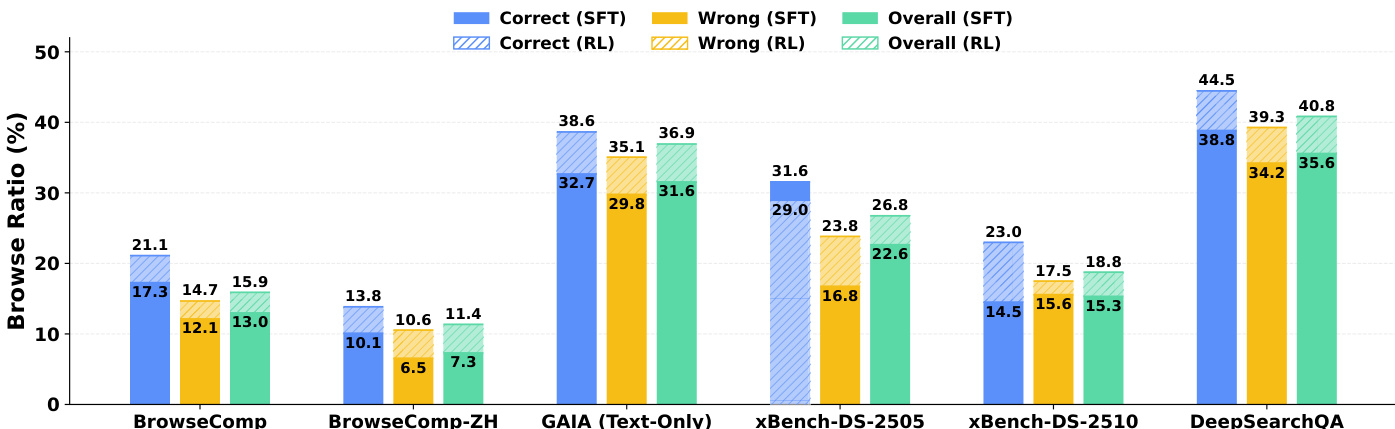
The authors analyze the tool usage behavior of their agent across multiple benchmarks, focusing on the browse ratio for correct and incorrect trajectories under supervised fine-tuning (SFT) and reinforcement learning (RL) checkpoints. Results show that successful trajectories consistently exhibit higher browse ratios than failed ones, indicating that deeper evidence inspection is crucial for task success. Reinforcement learning enhances this pattern by increasing the overall browse ratio and strengthening the alignment between browsing behavior and task correctness, particularly in scenarios where the SFT model previously showed counterintuitive trends. Correct trajectories consistently show higher browse ratios than wrong trajectories across all benchmarks, indicating deeper evidence gathering is linked to success. Reinforcement learning increases the overall browse ratio and strengthens the gap between correct and wrong trajectories, improving tool use alignment with task outcomes. RL corrects counterintuitive patterns in tool use, such as wrong trajectories browsing more than correct ones, by promoting more effective evidence gathering.
The authors present a comprehensive evaluation of DR-Venus, a small-scale deep research agent, comparing its performance against larger foundation models and trained agents across multiple benchmarks. Results show that DR-Venus-4B-SFT establishes a strong baseline, outperforming several 30B-scale models on individual benchmarks, while DR-Venus-4B-RL further improves performance, achieving competitive results with larger models and demonstrating the effectiveness of reinforcement learning in enhancing long-horizon task reliability. The analysis highlights that high-quality training data and effective data utilization can compensate for model scale limitations, and that reinforcement learning enhances tool use, particularly browsing, to improve evidence gathering and task success. DR-Venus-4B-SFT outperforms several 30B-scale agents on individual benchmarks, demonstrating that model scale is not the sole determinant of performance. DR-Venus-4B-RL improves upon the SFT baseline across most benchmarks, with gains attributed to better formatting accuracy, tool use, and execution reliability. Reinforcement learning increases the browse ratio, particularly for correct trajectories, indicating improved evidence gathering and more effective tool use.
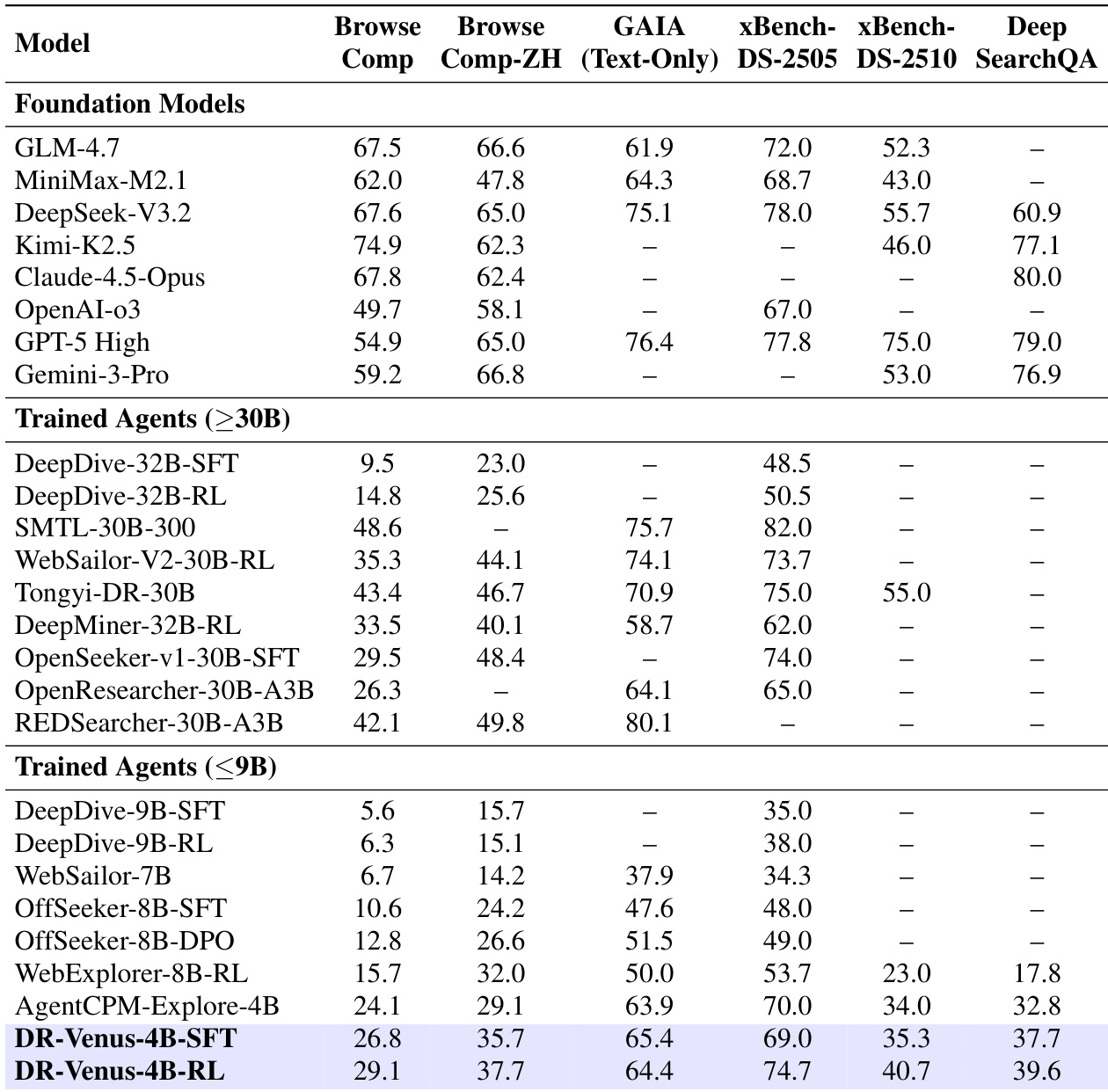
The authors evaluate the DR-Venus small-model agent against various baselines and larger foundation models across multiple benchmarks to validate the impact of supervised fine-tuning and reinforcement learning. The results demonstrate that effective training on open data and agentic reinforcement learning allow small models to achieve competitive performance, often surpassing much larger models in long-horizon research tasks. Specifically, reinforcement learning improves task success by enhancing tool use reliability and promoting deeper evidence gathering through increased browsing behavior.