Command Palette
Search for a command to run...
RAD-2: Skalierung von Reinforcement Learning in einem Generator-Discriminator-Framework
RAD-2: Skalierung von Reinforcement Learning in einem Generator-Discriminator-Framework
Hao Gao Shaoyu Chen Yifan Zhu Yuehao Song Wenyu Liu Qian Zhang Xinggang Wang
Zusammenfassung
Hier ist die Übersetzung des Textes ins Deutsche, unter Berücksichtigung der wissenschaftlichen Präzision und der von Ihnen vorgegebenen Anforderungen:Hochgradig autonomes Fahren erfordert Motion Planner, die in der Lage sind, multimodale zukünftige Unsicherheiten zu modellieren und gleichzeitig eine Robustheit in Closed-Loop-Interaktionen zu gewährleisten. Obwohl Diffusion-basierte Planner effektiv bei der Modellierung komplexer Trajektorienverteilungen sind, leiden sie häufig unter stochastischen Instabilitäten und einem Mangel an korrigierendem negativem Feedback, wenn sie rein mittels Imitation Learning trainiert werden. Um diese Probleme zu lösen, schlagen wir RAD-2 vor, ein einheitliches Generator-Discriminator-Framework für das Closed-Loop-Planning. Konkret wird ein Diffusion-basierter Generator verwendet, um diverse Trajektorien-Kandidaten zu erzeugen, während ein durch RL optimierter Discriminator diese Kandidaten nach ihrer langfristigen Fahrqualität neu bewertet (Reranking). Dieses entkoppelte Design vermeidet die direkte Anwendung spärlicher (sparse) skalaren Rewards auf den vollständigen hochdimensionalen Trajektorienraum, wodurch die Optimierungsstabilität verbessert wird. Um das Reinforcement Learning weiter zu verstärken, führen wir „Temporally Consistent Group Relative Policy Optimization“ ein, das die zeitliche Kohärenz nutzt, um das Credit Assignment Problem zu mildern. Zusätzlich schlagen wir „On-policy Generator Optimization“ vor, welches Closed-Loop-Feedback in strukturierte longitudinale Optimierungssignale umwandelt und den Generator schrittweise in Richtung High-Reward-Trajektorien-Manifolds verschiebt. Zur Unterstützung eines effizienten großangelegten Trainings führen wir BEV-Warp ein, eine High-Throughput-Simulationsumgebung, die die Closed-Loop-Evaluierung durch räumliches Warping direkt im Bird's-Eye-View-Feature-Raum durchführt. RAD-2 reduziert die Kollisionsrate im Vergleich zu leistungsstarken Diffusion-basierten Planern um 56 %. Der Einsatz in der realen Welt demonstriert zudem eine verbesserte wahrgenommene Sicherheit und eine höhere Fahrglätte in komplexem urbanem Verkehr.
One-sentence Summary
To improve stability and correct imitation learning errors in multimodal autonomous driving scenarios, the researchers propose RAD-2, a unified generator-discriminator framework that utilizes a diffusion-based generator to produce trajectory candidates and an RL-optimized discriminator to rerank them, while employing Temporally Consistent Group Relative Policy Optimization to enhance reinforcement learning.
Key Contributions
- The paper introduces RAD-2, a unified generator-discriminator framework that utilizes a diffusion-based generator for diverse trajectory production and an RL-optimized discriminator for reranking candidates based on long-term driving quality.
- This work presents Temporally Consistent Group Relative Policy Optimization to improve credit assignment through temporal coherence and On-policy Generator Optimization to refine trajectory distributions using structured longitudinal signals.
- The authors develop BEV-Warp, a high-throughput feature-level simulation pipeline that warps BEV features around the ego vehicle to enable scalable closed-loop training without expensive image-level rendering.
Introduction
High-level autonomous driving requires motion planners that can model multimodal uncertainty while remaining robust during closed-loop interactions. While diffusion-based planners excel at capturing complex trajectory distributions, they often face stochastic instabilities and lack corrective feedback when trained solely through imitation learning. Furthermore, applying reinforcement learning directly to high-dimensional trajectory spaces is difficult due to sparse rewards and severe credit assignment challenges. The authors leverage a unified generator-discriminator framework to decouple these tasks, using a diffusion-based generator to produce diverse candidates and an RL-optimized discriminator to rerank them based on long-term driving quality. To support this, they introduce Temporally Consistent Group Relative Policy Optimization to stabilize the RL search space and BEV-Warp, a high-throughput simulation environment that performs closed-loop evaluation in the Bird's-Eye View feature space to bypass expensive image-level rendering.
Dataset

Dataset Overview
The authors utilize a multi-stage dataset strategy to train and evaluate their motion generation and reinforcement learning frameworks:
- Generator Pretraining Data: The authors use approximately 50,000 hours of real-world driving data containing ego-vehicle trajectories. This large-scale dataset is used to pre-train the motion generator to capture the multimodal distribution of human driving behaviors.
- BEV Warp Environment Subsets:
- Source and Filtering: The authors initially collect 50,000 clips from real-world logs, with each clip lasting 10 to 20 seconds. These clips undergo closed-loop simulation in the BEV Warp environment to identify specific driving behaviors. Clips are filtered to isolate safety-critical scenarios (high collision risk) and efficiency-related scenarios (suboptimal performance).
- Training Sets: Two curated training sets are created for closed-loop reinforcement learning, each containing 10,000 clips focused on either safety or efficiency objectives.
- Evaluation Sets: Two disjoint subsets of 512 clips each are constructed for closed-loop assessment, corresponding to the safety and efficiency categories.
- 3DGS Environment Subsets:
- Source: The authors utilize the photorealistic 3D Gaussian Splatting (3DGS) simulation benchmark from Senna-2, which focuses on high-risk safety scenarios.
- Usage: 1,044 clips are used to train the trajectory discriminator, while 256 clips are reserved for closed-loop evaluation.
- Open-loop Evaluation Scenarios: The authors adopt the Senna-2 open-loop evaluation dataset to test planning quality across six representative scenarios: car-following start, car-following stop, lane changing, intersections, curves, and heavy braking.
Method
The proposed framework, RAD-2, employs a generator-discriminator architecture to achieve robust and safe motion planning in autonomous driving. This design decouples the high-dimensional trajectory generation process from the low-dimensional reinforcement learning (RL) optimization, enabling stable and efficient policy training. As illustrated in the framework diagram, the system operates through two primary components: a diffusion-based generator and an RL-trained discriminator. The generator produces a diverse set of candidate trajectories conditioned on the current observation, while the discriminator evaluates and reranks these candidates based on their expected long-term outcomes. This joint policy is defined as \\Pi_{\\theta,\\phi}(\\tau|o) = \\mathbb{E}_{c \\sim \\mathcal{G}_\\theta(\\cdot|o)}[\\mathcal{D}_\\phi(\\tau|o, \\mathcal{C})], which allows for a structured policy where the generator explores a broad space of feasible actions and the discriminator selectively prioritizes higher-quality behaviors. The architecture inherently supports inference-time scaling by increasing the number of candidate trajectories without requiring retraining.
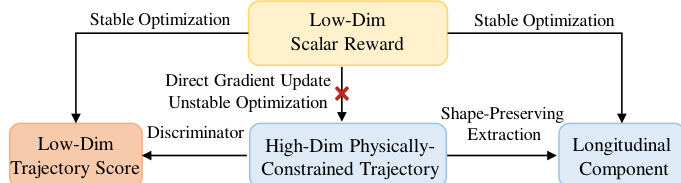
The diffusion-based generator, as shown in the diagram, models a multimodal distribution over future trajectories. It first encodes the current observation ot into Bird's Eye View (BEV) features Tb and extracts scene-specific information from static map elements, dynamic agents, and navigation inputs. These components are processed by lightweight encoders to obtain token embeddings, which are then fused with the BEV features to form a unified scene embedding Etextscene. This embedding conditions a DiT-based trajectory generator via cross-attention. For M independent modes, the generator iteratively denoises an initial noise trajectory over K steps to produce a set of candidate trajectories widehatmathcalT. These trajectories are passed to the discriminator for evaluation.
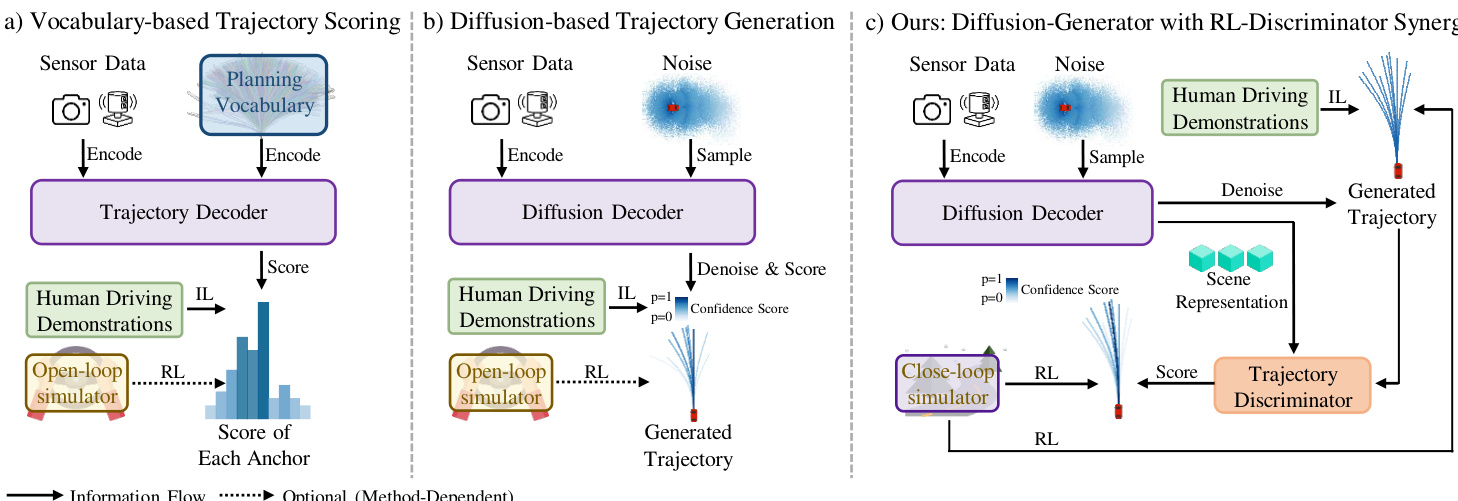
The discriminator evaluates candidate trajectories by first encoding each point in the trajectory via a shared MLP, and then processing the resulting sequence with a Transformer encoder to produce a trajectory-level query Qtau. This query aggregates information from the entire trajectory and is used to interact with the scene context. The scene representation is constructed from the same inputs as the generator, using independent encoders for static and dynamic elements. The trajectory-query interacts with the scene context through cross-attention mechanisms to produce fused embeddings Etextfusion. A final sigmoid activation applied to this fused representation produces a scalar score for each candidate trajectory, which is used for reranking. This process enables the discriminator to provide precise, long-term outcome-based feedback, which is then used to guide the optimization of the generator.
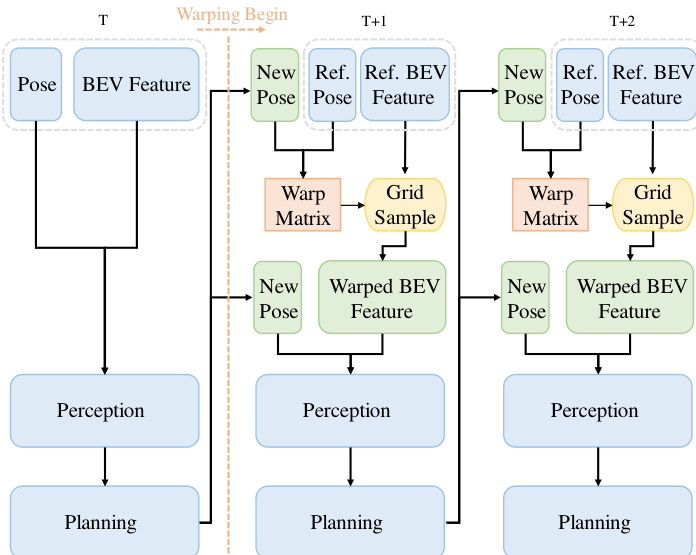
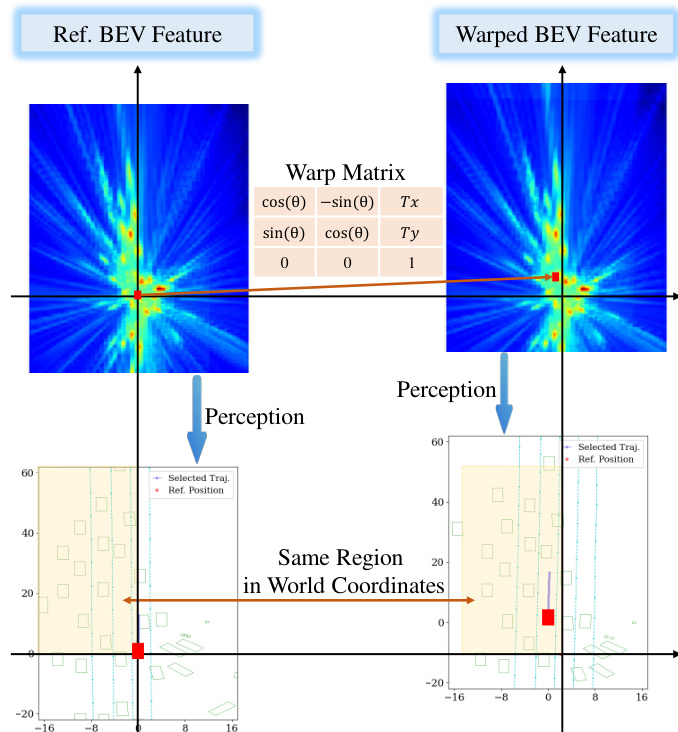
To scale the RL training process, the system leverages a high-throughput, feature-level simulation environment called BEV-Warp. This environment enables efficient closed-loop interaction by manipulating BEV features directly, bypassing the need for expensive image-level rendering. The simulation is initialized from real-world sequences, and at each timestep, the system extracts a reference BEV feature and the current agent pose. The planner generates candidate trajectories, from which an optimal one is selected. To maintain temporal coherence and ensure stable exploration, the system employs a trajectory reuse mechanism. Once a trajectory is selected, its corresponding control commands are executed over a fixed horizon, stabilizing the agent's motion. This mechanism ensures that the cumulative reward accurately reflects the quality of the selected trajectory, facilitating effective policy gradients. The closed-loop evaluation is driven by a recursive feature-warping mechanism, where a warp matrix derived from the relative pose deviation between the simulated agent and the logged reference is applied to the reference BEV feature to synthesize the next high-fidelity observation.
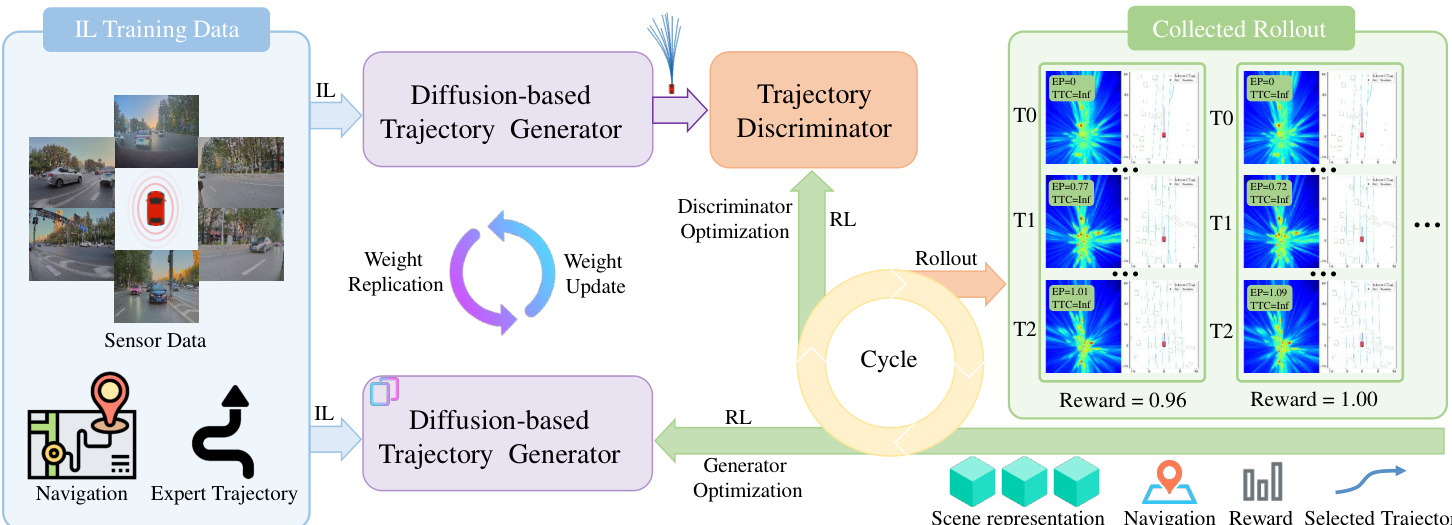
The joint policy optimization is realized through a multi-stage iterative process. The global objective is to minimize the KL-divergence between the hybrid policy and an ideal high-efficiency distribution. The training pipeline consists of three stages: (i) Temporally Consistent Rollout, which collects stable closed-loop interaction data; (ii) Discriminator Optimization, where the discriminator is optimized via a Temporally Consistent Group Relative Policy Optimization (TC-GRPO) framework to enhance its scoring precision; and (iii) Generator Optimization, which employs On-policy Generator Optimization (OGO) to shift the generator's distribution toward safer and more efficient behaviors. The TC-GRPO framework introduces a structured rollout and reward assignment mechanism to address the credit assignment problem in continuous driving, ensuring that the sparse environment reward is directly attributed to the specific trajectory hypothesis sustained within each persistent interval. The OGO mechanism converts closed-loop reward signals into structured longitudinal optimizations, adjusting the acceleration profile of raw trajectory segments to better align with safety and efficiency goals. This allows the generator to iteratively shift its output distribution toward favorable long-term outcomes without compromising stability.
The training process begins with a pre-training stage where the diffusion-based generator is initialized via imitation learning on expert demonstrations to capture multi-modal trajectory priors. This is followed by a closed-loop rollout phase where the joint policy interacts with the BEV-Warp environment to generate diverse rollout data. The discriminator is then optimized via the TC-GRPO framework, leveraging the closed-loop feedback to enhance its ability to rank trajectories. Finally, the generator is optimized through OGO, which uses the structured longitudinal optimization signals derived from low-reward rollouts to refine its distribution. The system employs a cyclic optimization loop, with the discriminator updated more frequently than the generator, ensuring continuous co-adaptation. The entire framework enables a self-improving closed loop, where the generator and discriminator jointly optimize the overall policy, progressively shifting the trajectory distribution toward safer and more efficient behaviors.
Experiment
The proposed method is evaluated through closed-loop simulations in BEV Warp and 3DGS environments to assess interactive driving behavior, alongside open-loop benchmarks to validate trajectory accuracy. Results demonstrate that the synergistic joint optimization of the generator and discriminator significantly improves the balance between safety and efficiency compared to decoupled or single-objective training strategies. Qualitative analysis and ablation studies further confirm that the framework achieves superior collision avoidance and smoother navigation through effective reward-based filtering and robust inference-time scaling.
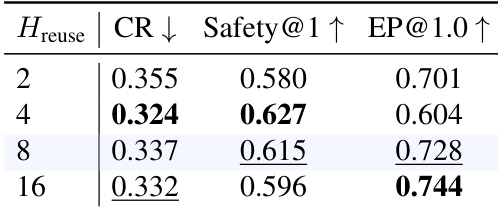
The the the table presents an ablation study on the execution horizon, showing how different values affect collision rate, safety, and efficiency metrics. The results indicate that an intermediate horizon achieves the best balance between performance and stability. An execution horizon of 8 achieves the highest efficiency and the best trade-off between safety and collision rate. Lower horizons lead to higher collision rates and reduced safety, while higher horizons decrease efficiency. The optimal horizon balances stable credit assignment with reactive flexibility for effective training.
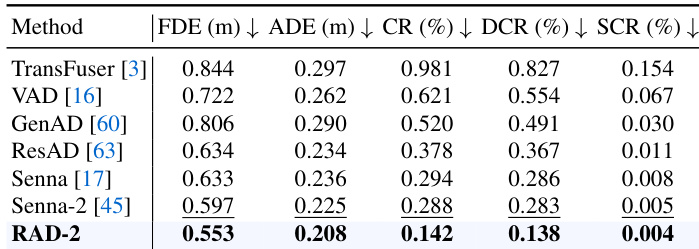
The authors compare several methods on open-loop trajectory accuracy using a benchmark that includes various driving scenarios. Results show that the proposed method achieves the lowest collision rate and the best trajectory quality metrics, outperforming prior approaches across all evaluated measures. The proposed method achieves the lowest collision rate and trajectory error metrics compared to all baseline methods. The method significantly reduces both dynamic and static collision components in open-loop scenarios. It demonstrates superior trajectory quality with the lowest ADE and FDE values among the evaluated approaches.
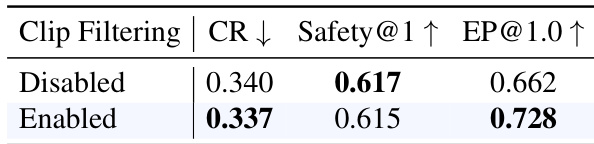
The results show that enabling clip filtering improves efficiency while maintaining safety in trajectory planning. This indicates that filtering out low-variance scenarios leads to more stable and effective training outcomes. Clip filtering improves efficiency without compromising safety Enabling clip filtering enhances [email protected] performance Filtering low-variance clips stabilizes training dynamics
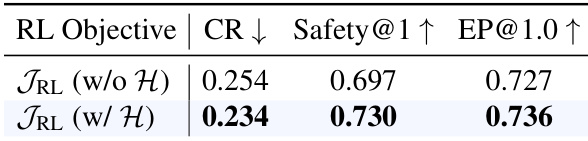
The authors compare two reinforcement learning objectives, one without and one with an entropy term, to evaluate their impact on safety and efficiency. Results show that incorporating the entropy term improves safety and efficiency metrics compared to the version without it. Including the entropy term in the RL objective improves safety and efficiency The version with the entropy term achieves a lower collision rate The version with the entropy term achieves higher safety and efficiency scores
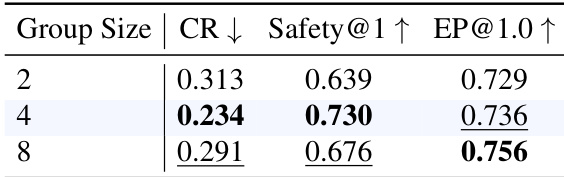
The the the table shows the impact of different group sizes on model performance, with a group size of 4 achieving the best balance between safety and efficiency metrics. Larger group sizes lead to a decline in safety performance while improving efficiency slightly. A group size of 4 achieves the highest safety and efficiency scores. Increasing the group size beyond 4 reduces safety metrics. Efficiency improves with larger group sizes, but at the cost of safety.
The experiments evaluate various architectural and training components through ablation studies and comparative benchmarks to optimize driving performance. Results demonstrate that an intermediate execution horizon, the inclusion of an entropy term in the RL objective, and the use of clip filtering all contribute to more stable and efficient training. Furthermore, the proposed method outperforms baseline approaches in open-loop trajectory accuracy, while an optimal group size is necessary to balance safety with operational efficiency.