Command Palette
Search for a command to run...
Wie lässt sich ein Reasoning Model fine-tunen? Ein Teacher-Student-Kooperationsframework zur Synthese von Student-consistent SFT-Daten
Wie lässt sich ein Reasoning Model fine-tunen? Ein Teacher-Student-Kooperationsframework zur Synthese von Student-consistent SFT-Daten
Zixian Huang Kaichen Yang Xu Huang Feiyang Hao Qiming Ge Bowen Li He Du Kai Chen Qipeng Guo
Zusammenfassung
Eine weit verbreitete Strategie zur Modellverbesserung besteht darin, synthetische Daten, die von einem stärkeren Modell generiert wurden, für das Supervised Fine-Tuning (SFT) zu verwenden. Bei aufkommenden Reasoning-Modellen wie Qwen3-8B führt dieser Ansatz jedoch häufig nicht zu einer Verbesserung der Reasoning-Fähigkeiten und kann sogar zu einem erheblichen Leistungsabfall führen. In dieser Arbeit identifizieren wir eine signifikante stilistische Divergenz zwischen den vom Teacher generierten Daten und der Verteilung des Students als einen Hauptfaktor, der das SFT beeinflusst. Um diese Lücke zu schließen, schlagen wir ein „Teacher-Student Cooperation Data Synthesis“-Framework (TESSY) vor, das Teacher- und Student-Modelle so miteinander verknüpft, dass sie abwechselnd Style- und Non-Style-Tokens generieren. Infolgedessen erzeugt TESSY synthetische Sequenzen, welche die fortgeschrittenen Reasoning-Fähigkeiten des Teachers erben und gleichzeitig die stilistische Konsistenz mit der Verteilung des Students beibehalten. In Experimenten zur Code-Generierung unter Verwendung von GPT-OSS-120B als Teacher führte das Fine-Tuning von Qwen3-8B auf vom Teacher generierten Daten zu Leistungsabfällen von 3,25 % auf LiveCodeBench-Pro und 10,02 % auf OJBench, während TESSY Verbesserungen von 11,25 % bzw. 6,68 % erzielt.
One-sentence Summary
To mitigate performance drops in reasoning models caused by stylistic divergence during supervised fine-tuning, the authors propose TESSY, a teacher-student cooperation framework that interleaves teacher and student models to generate style-consistent synthetic sequences, ultimately improving Qwen3-8B code generation performance by 11.25% on LiveCodeBench-Pro and 6.68% on OJBench when using GPT-OSS-120B as the teacher.
Key Contributions
- The paper identifies stylistic divergence between teacher-generated data and the student model distribution as a primary cause for performance degradation during supervised fine-tuning of reasoning models.
- This work introduces the Teacher–Student Cooperation Data Synthesis (TESSY) framework, which interleaves teacher and student models to alternately generate style and non-style tokens to ensure stylistic consistency while retaining advanced reasoning capabilities.
- Experiments on code generation tasks demonstrate that TESSY overcomes the performance drops caused by standard teacher-generated data, achieving improvements of 11.25% on LiveCodeBench-Pro and 6.68% on OJBench when fine-tuning Qwen3-8B.
Introduction
Supervised fine-tuning (SFT) using synthetic data from stronger models is a standard method for enhancing large language models. However, for specialized reasoning models, this approach often causes significant performance degradation because of a stylistic divergence between the teacher's output and the student's distribution. While existing methods attempt to bridge this gap through self-distillation or on-policy learning, they often struggle with high computational costs or the introduction of reasoning shortcuts. The authors propose TESSY, a Teacher-Student Cooperation Data Synthesis framework that interleaves teacher and student models to alternately generate style and non-style tokens. This approach allows the synthesized data to inherit advanced reasoning capabilities from the teacher while maintaining the stylistic consistency required by the student.
Dataset

Dataset Overview
The authors constructed a specialized training corpus focused on programming contest tasks through the following process:
- Composition and Sources: The dataset is built from open-source collections provided by OpenThoughts and NVIDIA Nemotron.
- Selection and Filtering: To ensure task relevance, the authors used carefully designed prompts to guide GPT-OSS-120B in selecting samples specifically related to programming contests. During this process, the original responses were discarded, and only the corresponding questions were retained.
- Dataset Size: From the filtered corpus, the authors randomly sampled 80k questions. This collection contains 37k unique questions.
- Usage: The resulting set of unique questions serves as the foundation for generating new responses and training the models used across all experiments.
Method
The authors propose a teacher–student cooperation data synthesis framework, referred to as TESSY, designed to improve supervised fine-tuning (SFT) for reasoning models by addressing the challenge of stylistic misalignment between teacher and student models. The core objective is to align the student model’s output distribution with the data distribution, focusing on capability tokens that contribute to task performance while mitigating the influence of style tokens that may introduce conflicting stylistic patterns. To achieve this, the framework decomposes the training objective into two components: LCap(MS), which optimizes capability tokens, and LSty(MS), which handles style tokens. The key insight is that capability tokens are best sampled from a more powerful teacher model, whereas style tokens should follow the student’s inherent distribution to preserve stylistic consistency.
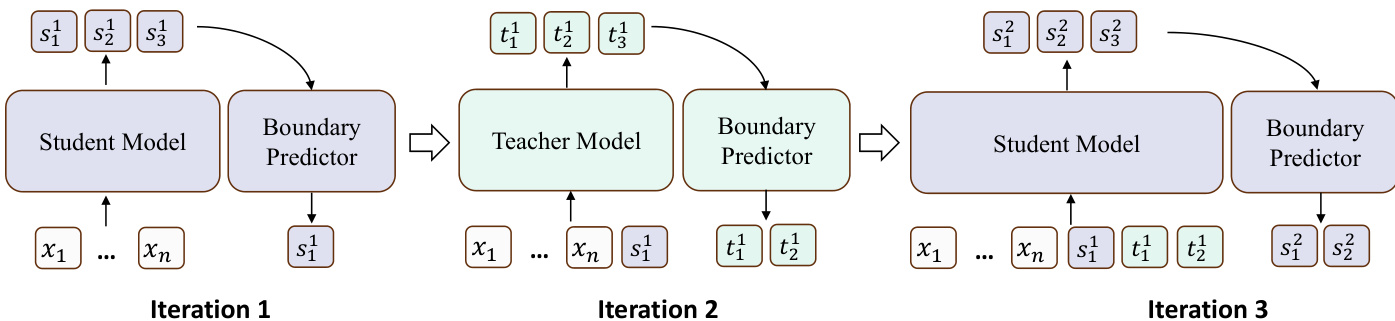
As illustrated in the figure, TESSY generates responses through an alternating and iterative process between the teacher and student models. The framework begins with the student model generating the initial span of style tokens, followed by the teacher model producing a span of capability tokens, and continues in this alternating pattern. This design reflects the natural structure of human reasoning, where reasoning steps are often interspersed with transitional or connective statements. The response y is constructed as a sequence of alternating spans: y=[s1,t1,s2,t2,…], where si and ti represent spans generated by the student and teacher models, respectively. The generation of each span depends on the complete history of previously generated spans, defined as si=MS(x,[s1,t1,…,si−1,ti−1]) and ti=MT(x,[s1,t1,…,si]).
A critical challenge in this alternating generation process is the generation boundary problem: determining the appropriate length of each span to ensure that student-generated spans contain only style tokens and teacher-generated spans contain only capability tokens. To resolve this, TESSY employs a generate-then-rollback strategy. At each step, the current model generates a fixed number of k tokens, after which a boundary predictor is applied to identify the correct truncation point. For the teacher model, a capability token boundary predictor, BT, is used to locate the first style token in the generated sequence, and all tokens up to and including the last capability token are retained. Similarly, a style token boundary predictor, BS, for the student model identifies the first capability token, and all tokens up to and including the last style token are kept. The truncated spans are then appended to the synthetic sequence, and the generation roles are switched if a truncation occurs, indicating a change in token type.

The boundary predictors are implemented as token-level sequence labeling models, trained to classify each token as either a capability or style token. To train these predictors, the authors sample 100k segments of thinking content from both the teacher and student models and use the teacher model to annotate the style spans. The training is performed on a small model, Qwen3-0.6B-Base, to ensure efficiency. Finally, the synthetic sequence is completed by generating the final answer, which is delegated entirely to the student model to maintain stylistic consistency with the student's output distribution. The complete data synthesis process is outlined in Algorithm 1, which formalizes the alternating generation, boundary prediction, and role switching steps.
Experiment
The experiments evaluate the TESSY framework against various supervised fine-tuning (SFT) baselines, including teacher-only and teacher-score methods, across code generation, mathematics, and science tasks. The results demonstrate that directly training student models on stylistically different teacher data leads to performance degradation due to distributional conflicts. In contrast, TESSY consistently improves student performance by delegating reasoning content to the teacher while maintaining stylistic consistency through student-generated text, showing strong generalizability across different teacher and student model scales.
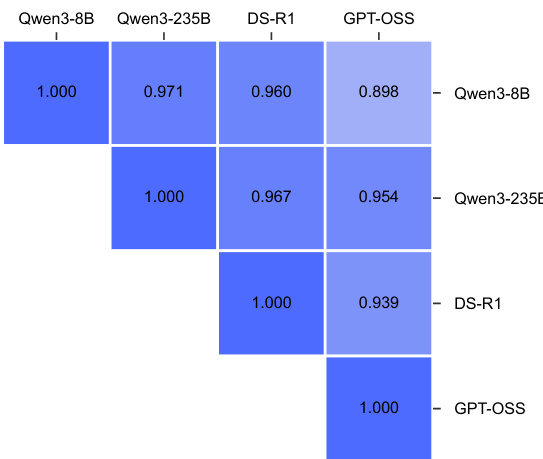
The the the table presents a comparison of output similarity between different models, showing that TESSY increases the similarity between the student model and various teacher models. The results indicate that TESSY effectively reduces distributional differences in generated responses, with the highest similarity observed between models of the same family. TESSY increases output similarity between student and teacher models. Similarity is highest between models of the same family. TESSY reduces distributional differences in generated responses.
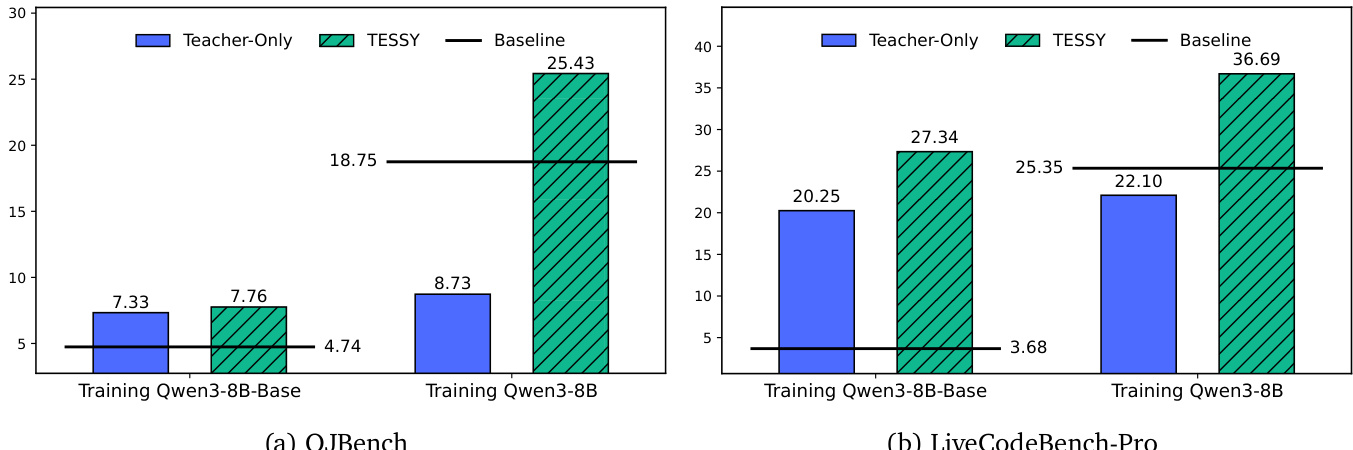
The authors compare the performance of TESSY against baseline methods on code generation tasks, using Qwen3-8B and Qwen3-8B-Base as student models. Results show that TESSY consistently improves performance on both in-domain and out-of-domain benchmarks compared to Teacher-Only and other baselines, while Teacher-Only leads to significant performance drops. TESSY consistently improves model performance on code generation benchmarks compared to Teacher-Only and other baselines. Teacher-Only results in substantial performance degradation across all evaluated datasets. TESSY enables performance gains even when training on a base model, though gains are smaller than when training on a reasoning model.
The authors compare different data synthesis methods for fine-tuning a student model, showing that TESSY consistently outperforms Teacher-Only across multiple benchmarks. The results indicate that TESSY improves the student model's performance while mitigating performance drops caused by stylistic mismatches in training data. TESSY improves student model performance on both in-domain and out-of-domain benchmarks compared to Teacher-Only Teacher-Only leads to performance degradation on multiple datasets, while TESSY avoids this issue TESSY achieves better results than Teacher-Only even when the teacher model has higher baseline capability
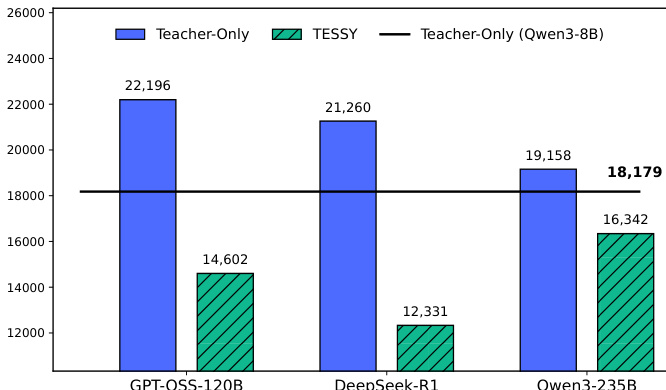
The bar chart compares the average token counts of synthetic data generated by different methods across three teacher models. Results show that TESSY consistently produces shorter responses compared to the Teacher-Only approach, with the reduction varying depending on the teacher model used. TESSY generates significantly fewer tokens than Teacher-Only across all evaluated models. The reduction in token count is most pronounced when using GPT-OSS-120B as the teacher. TESSY produces responses that are even shorter than those generated by the student model Qwen3-8B.
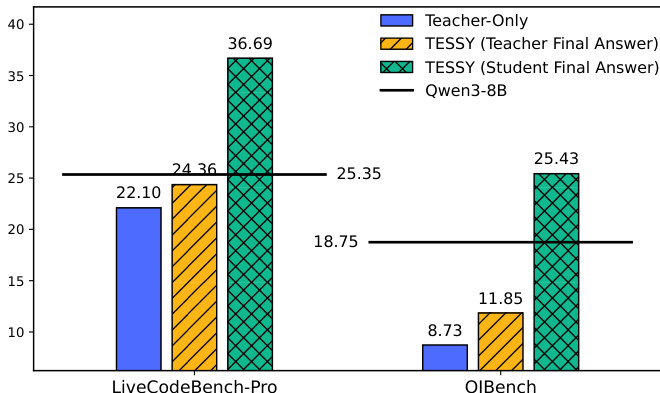
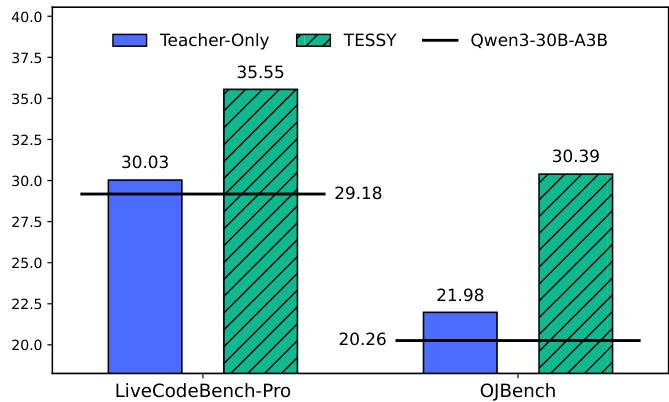
The authors compare the performance of TESSY and Teacher-Only methods on code generation tasks. Results show that TESSY consistently outperforms Teacher-Only, achieving higher scores on both LiveCodeBench-Pro and OJBench compared to the baseline model. TESSY achieves higher performance than Teacher-Only on code generation benchmarks. TESSY improves model performance on LiveCodeBench-Pro and OJBench compared to the baseline. The performance gap between TESSY and Teacher-Only is significant on both benchmarks.
The experiments evaluate TESSY by comparing its output similarity, code generation performance, and data synthesis quality against Teacher-Only and other baseline methods. The results demonstrate that TESSY effectively reduces distributional differences between student and teacher models while preventing the performance degradation typically caused by stylistic mismatches. Furthermore, TESSY consistently improves performance on both in-domain and out-of-domain benchmarks and produces more concise synthetic responses compared to the Teacher-Only approach.