Command Palette
Search for a command to run...
Gedächtnis-Transfer Learning: Wie Erinnerungen über Domänen hinweg in Coding Agents übertragen werden
Gedächtnis-Transfer Learning: Wie Erinnerungen über Domänen hinweg in Coding Agents übertragen werden
Kangsan Kim Minki Kang Taeil Kim Yanlai Yang Mengye Ren Sung Ju Hwang
Zusammenfassung
Hier ist die Übersetzung des Textes ins Deutsche, unter Berücksichtigung Ihrer Vorgaben für wissenschaftliche Präzision und die Beibehaltung von KI-Fachtermini:Übersetzung:Die speicherbasierte Selbstentwicklung (Memory-based self-evolution) hat sich als vielversprechendes Paradigma für Coding Agents herausgestellt. Bestehende Ansätze beschränken die Nutzung von Memory jedoch typischerweise auf homogene Aufgabendomänen. Dabei versäumen sie es, die gemeinsamen infrastrukturellen Grundlagen – wie etwa Runtime-Umgebungen und Programmiersprachen – zu nutzen, die über verschiedene reale Coding-Probleme hinweg existieren. Um diese Einschränkung zu adressieren, untersuchen wir das Memory Transfer Learning (MTL), indem wir einen vereinheitlichten Memory-Pool aus heterogenen Domänen nutzen. Wir evaluieren die Performance über sechs Coding-Benchmarks hinweg unter Verwendung von vier verschiedenen Memory-Repräsentationen, die von konkreten Traces bis hin zu abstrakten Insights reichen. Unsere Experimente zeigen, dass domänenübergreifendes Memory die durchschnittliche Performance um 3,7 % verbessert. Dies geschieht primär durch den Transfer von Meta-Wissen, wie beispielsweise Validierungsroutinen, anstatt durch aufgabenbezogenen Code. Ein wesentliches Ergebnis ist, dass die Abstraktion die Transferierbarkeit bestimmt: High-Level-Insights generalisieren gut, während Low-Level-Traces aufgrund ihrer übermäßigen Spezifität häufig zu negativem Transfer führen. Darüber hinaus zeigen wir, dass die Effektivität des Transfers mit der Größe des Memory-Pools skaliert und dass Memory sogar zwischen verschiedenen Modellen transferiert werden kann. Unsere Arbeit etabliert empirische Designprinzipien für die Erweiterung der Memory-Nutzung über einzelne, isolierte Domänen (Silos) hinaus.Projektseite: https://memorytransfer.github.io/
One-sentence Summary
By investigating Memory Transfer Learning (MTL) through a unified memory pool across heterogeneous domains, researchers demonstrate that prioritizing abstract meta-knowledge over task-specific traces improves performance across six coding benchmarks by 3.7% and establishes design principles for scaling memory and enabling model-to-model transfer.
Key Contributions
- This work introduces Memory Transfer Learning, a paradigm that enables coding agents to leverage a unified memory pool generated from heterogeneous task domains to improve performance on target tasks.
- The research evaluates four distinct memory representations ranging from concrete traces to abstract insights across six coding benchmarks, demonstrating that cross-domain memory improves average performance by 3.7%.
- The study establishes empirical design principles by showing that high-level meta-knowledge like validation routines generalizes effectively, while low-level traces often cause negative transfer due to excessive specificity.
Introduction
Memory-based self-evolution is a critical paradigm for advancing coding agents by allowing them to reuse successful workflows and avoid past errors. While these agents rely on memory to reduce reasoning overhead, existing approaches typically restrict memory utilization to homogeneous task domains, failing to exploit the shared infrastructural foundations like programming languages and runtime environments found across diverse coding problems. The authors investigate Memory Transfer Learning (MTL) by leveraging a unified memory pool from heterogeneous domains to improve agent performance. Their research demonstrates that cross-domain memory improves average performance by 3.7% by transferring high-level meta-knowledge rather than task-specific code. Furthermore, the authors establish that memory abstraction is a key driver of success, finding that high-level insights generalize well while low-level execution traces often lead to negative transfer due to excessive specificity.
Method
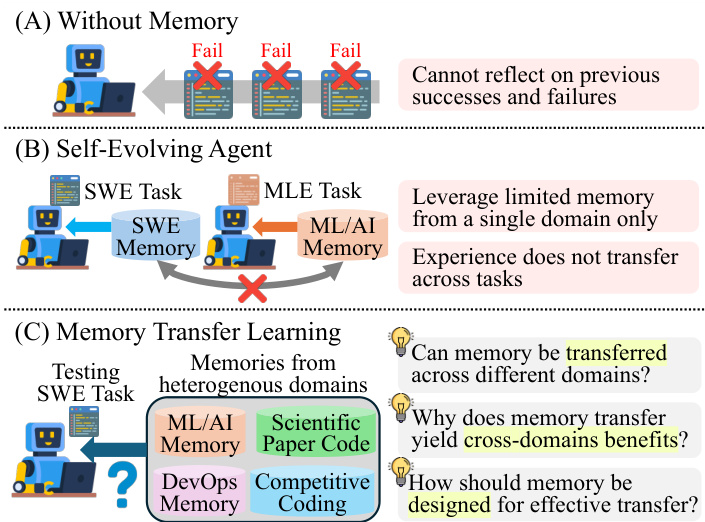
The authors design a memory-based coding agent that operates through a two-stage process: memory generation and memory retrieval. This framework is structured to enable the agent to leverage past experiences for improved task performance, particularly in cross-domain scenarios. The overall architecture is illustrated in the figure below, which contrasts three settings: a baseline agent without memory, a self-evolving agent using memory from a single domain, and the proposed memory transfer learning approach that enables knowledge transfer across heterogeneous domains.
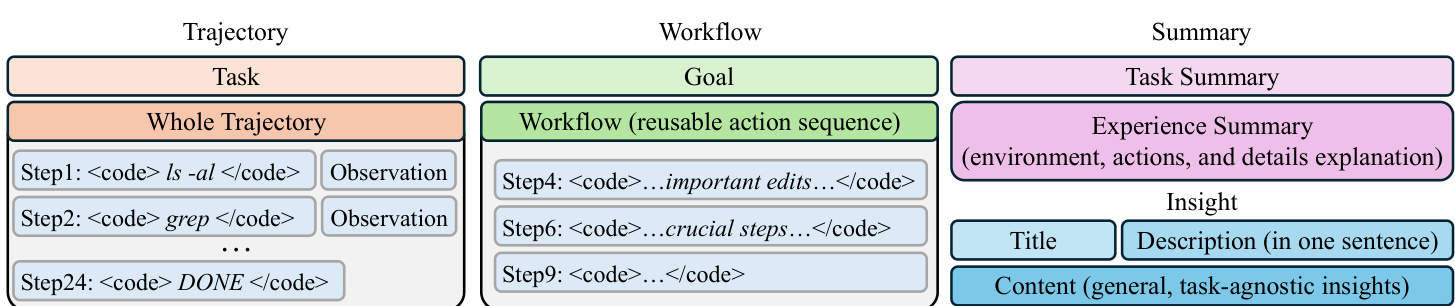
During the memory generation phase, the agent performs inference across all benchmarks to collect trajectories, which are sequences of reasoning, actions, and observations. These trajectories form the basis for constructing four distinct memory representations. The first is the Trajectory memory, which preserves the full sequence of actions and their corresponding observations without reasoning steps, capturing detailed execution history. The second is the Workflow memory, which abstracts the trajectory into a reusable sequence of actions aimed at achieving a specific goal, thereby reducing noise from irrelevant details. The third is the Summary memory, where a large language model (LLM) generates a concise summary of the task and a paragraph explaining the success or failure of the inference, providing explicit analysis. The fourth is the Insight memory, which distills the experience into a generalizable format consisting of a title, a brief description, and a content section that encapsulates transferable knowledge without referencing specific implementation details.
Following generation, the memories are indexed and stored in a heterogeneous-domain memory pool, which is constructed by aggregating memories from all benchmarks except the one being tested for each memory type. This ensures that the retrieval process operates on knowledge from different domains. During inference, the agent retrieves the most relevant memories by first generating an embedding for the current task and then computing the cosine similarity between this embedding and the embeddings of the stored memories. The top-N memories with the highest similarity scores are selected and incorporated into the system prompt at the beginning of the inference process, guiding the agent's reasoning and action selection.
The effectiveness of memory transfer is further analyzed through a formal mathematical framework that models the abstraction-transfer tradeoff. This model decomposes a memory embedding into a domain-invariant component, representing transferable meta-knowledge, and a domain-specific component. The abstraction level of a memory is defined as the proportion of its invariant component, and the utility of retrieving a memory for an unseen task is modeled as a trade-off between the transferable guidance provided by the invariant component and the penalty from domain mismatch due to the specific component. This formalization demonstrates that higher abstraction levels lead to greater transfer gains, providing a theoretical foundation for the observed benefits of generalizable memory representations.
Experiment
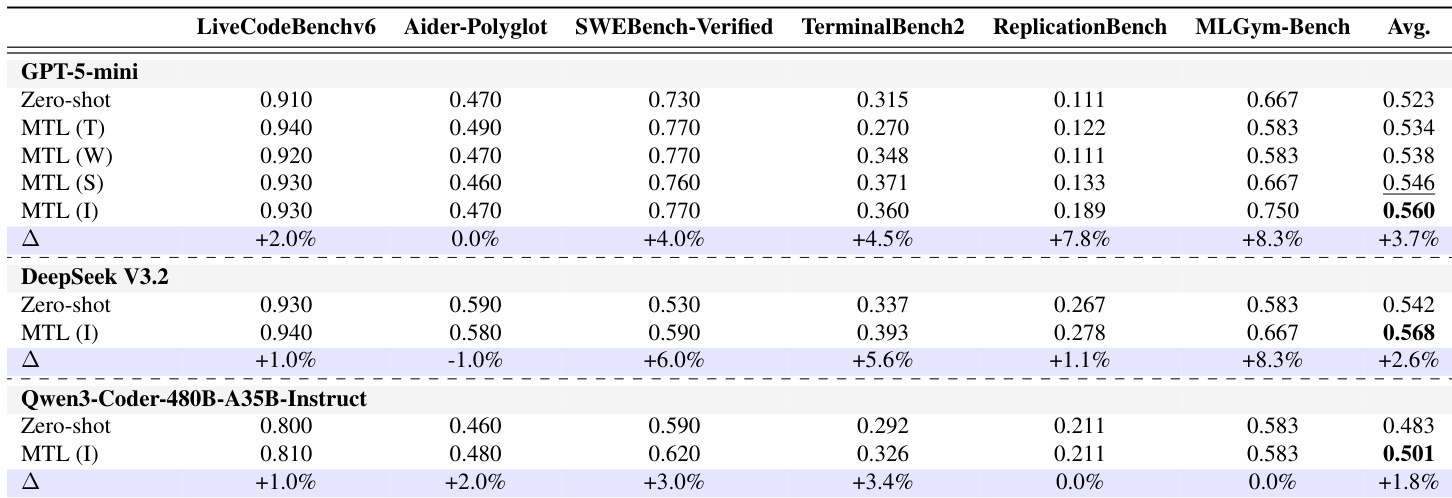
The researchers evaluated Memory Transfer Learning (MTL) for coding agents across six diverse benchmarks, ranging from competitive programming to repository-level tasks, to validate the effectiveness of cross-domain knowledge transfer. The experiments demonstrate that MTL significantly outperforms zero-shot baselines and existing self-evolving methods by providing high-level meta-knowledge rather than task-specific implementation details. Findings indicate that more abstract memory representations, such as Insights, yield superior transferability and efficiency compared to low-level trajectories, which can lead to brittle execution errors. Furthermore, the study shows that the benefits of MTL scale with the size and diversity of the memory pool and remain effective even when transferring memories across different language models.
The authors evaluate memory transfer learning across multiple coding benchmarks and models, showing consistent performance improvements over zero-shot baselines. Insight memories achieve the highest average performance, indicating that high-level, abstract knowledge transfers more effectively than task-specific details. Memory transfer learning improves performance over zero-shot baselines across different models and benchmarks. Insight memories, which capture high-level procedural guidance, achieve the highest average performance. Performance improves with larger memory pools and greater domain diversity, indicating better access to transferable meta-knowledge.
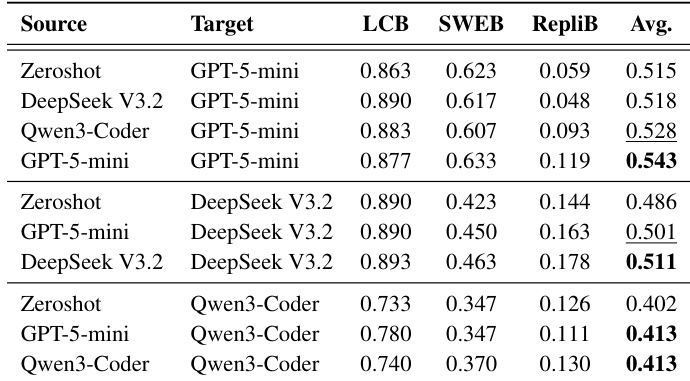
The authors evaluate memory transfer learning across multiple coding benchmarks and models, showing consistent performance improvements over zero-shot baselines. Insight memory types achieve the highest average gains, indicating that higher abstraction levels enhance transfer effectiveness. Memory transfer learning improves performance across diverse coding benchmarks and models compared to zero-shot settings. Insight memory types consistently outperform other memory types, highlighting the importance of abstraction in transfer learning. Performance gains increase with larger memory pools and greater domain diversity, suggesting that knowledge transfer benefits from broader training data.
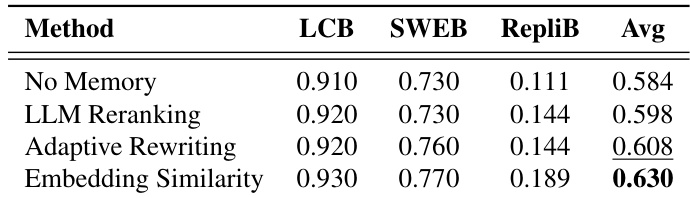
The the the table compares different memory retrieval methods across multiple benchmarks, showing that embedding similarity achieves the highest average performance. Adaptive rewriting and LLM reranking perform similarly but are slightly lower than embedding similarity, while the no memory baseline is the lowest. Embedding similarity retrieval method outperforms other methods across benchmarks. Adaptive rewriting and LLM reranking show similar performance, slightly below embedding similarity. The no memory baseline has the lowest performance in all evaluated metrics.
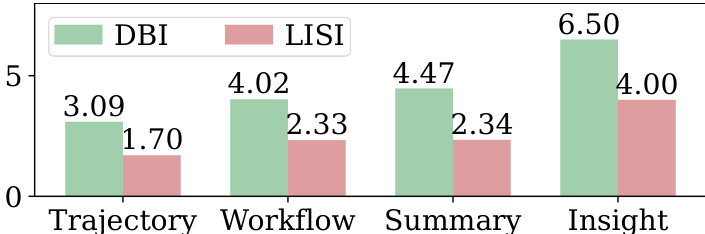
The chart compares memory abstraction levels using DBI and LISI metrics across different memory types. Trajectory and Workflow memories show stronger clustering, while Insight memories exhibit greater mixing and sparsity, indicating higher abstraction and generalization. Insight memories are more abstract and generalized compared to Trajectory and Workflow memories. Higher abstraction levels correlate with greater mixing and weaker clustering in the embedding space. DBI and LISI metrics show that Insight memories have the highest abstraction and the most diverse representation.
The authors evaluate Memory Transfer Learning across multiple coding benchmarks and models, showing consistent performance improvements over zero-shot baselines. Insight memories yield the highest average gains, indicating that abstract, meta-knowledge-based memories are most effective for cross-domain transfer. Memory Transfer Learning consistently improves performance over zero-shot baselines across different models and benchmarks. Insight memories achieve the highest average performance gains, suggesting abstract meta-knowledge is most transferable. Performance improves with larger memory pools and more diverse source domains, enhancing the likelihood of retrieving useful knowledge.
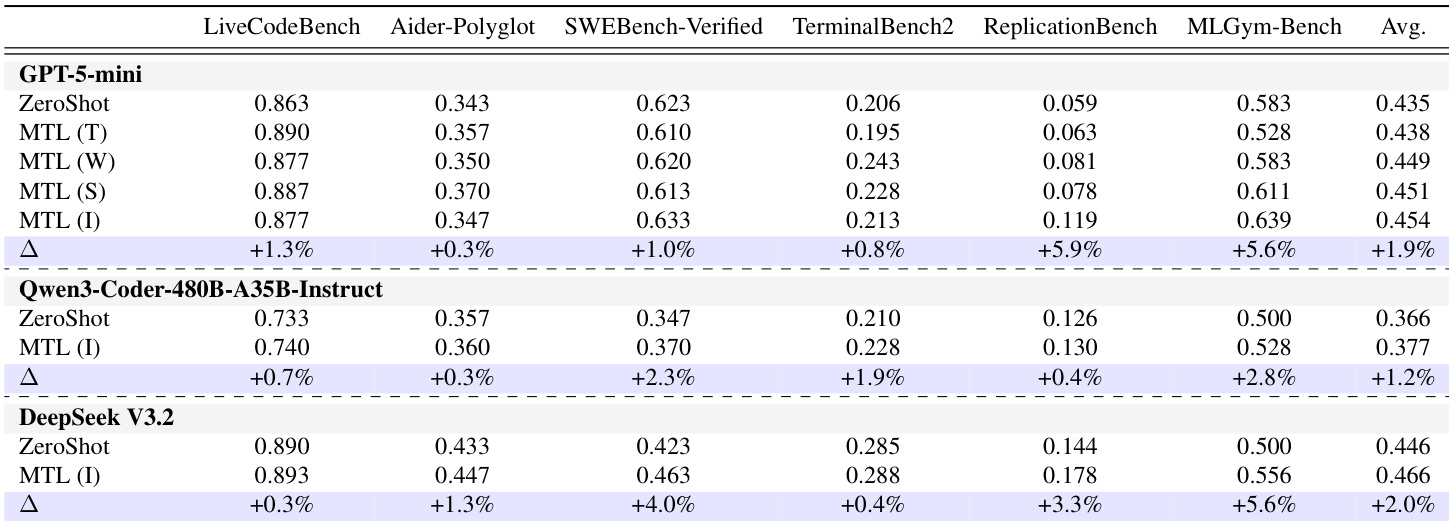
The authors evaluate memory transfer learning across various coding benchmarks and models to validate the effectiveness of different memory types and retrieval methods. Results demonstrate that memory transfer consistently outperforms zero-shot baselines, with high-level insight memories providing the most effective transfer due to their abstract and generalized nature. Furthermore, performance scales with larger, more diverse memory pools, while embedding similarity serves as the most effective retrieval mechanism.