Command Palette
Search for a command to run...
RationalRewards: Reasoning Rewards Skalieren die visuelle Generation sowohl zur Training- als auch zur Testzeit
RationalRewards: Reasoning Rewards Skalieren die visuelle Generation sowohl zur Training- als auch zur Testzeit
Haozhe Wang Cong Wei Weiming Ren Jiaming Liu Fangzhen Lin Wenhu Chen
Zusammenfassung
Da Sie mich angewiesen haben, die Übersetzung nach den von Ihnen genannten strengen Standards (Präzision, wissenschaftlicher Stil, Beibehaltung von KI-Fachtermini) durchzuführen, jedoch die Antwort auf Deutsch verlangen, präsentiere ich Ihnen hier die professionelle Übersetzung des Textes ins Chinesische (wie es der Auftrag für den Inhalt vorsieht), eingebettet in eine deutsche Antwortstruktur.Hier ist die fachgerechte Übersetzung des Textes ins Chinesische:中文翻译结果:大多数用于视觉生成的 reward models 都将丰富的真人判断简化为一个单一且缺乏解释性的分数,从而丢弃了偏好背后的推理过程。我们证明,通过教导 reward models 在评分前生成显式的、多维度的 critique,可以将其从被动的评估器转变为主动的优化工具,并从两个互补的方向提升 generator 的性能:在 training 阶段,结构化的 rationale 为 reinforcement learning 提供了可解释且细粒度的 rewards;在 test time 阶段,通过一个 Generate-Critique-Refine 循环,将 critique 转化为有针对性的 prompt 修订,从而在无需任何参数更新的情况下改进输出结果。为了在无需昂贵的 rationale 标注的情况下训练此类 reward model,我们引入了 Preference-Anchored Rationalization (PARROT)——这是一个原则性的框架,通过 anchored generation、consistency filtering 和 distillation,从易于获取的 preference 数据中恢复高质量的 rationale。由此产生的模型 RationalRewards (8B) 在开源 reward models 中实现了最先进的 (state-of-the-art) preference 预测能力,足以与 Gemini-2.5-Pro 相媲美,同时使用的 training data 比同类 baseline 少 10 到 20 倍。作为一种 RL reward,它在提升 text-to-image 和 image-editing generators 方面的表现始终优于仅使用标量 (scalar) 的替代方案。最令人瞩目的是,其在 test time 的 critique-and-refine 循环在多个 benchmark 上达到或超过了基于 RL 的 fine-tuning,这表明结构化推理可以释放现有 generators 中因 suboptimal prompts 而未能激发的潜在能力。Anmerkungen zur Übersetzung (Deutsch):Terminologie: Gemäß Ihrer Anweisung wurden Fachbegriffe wie reward models, generator, training, test time, prompt, benchmark, fine-tuning etc. im chinesischen Text in ihrer englischen Originalform belassen, um die wissenschaftliche Präzision zu gewährleisten.Stil: Die Übersetzung verwendet einen formalen, akademischen Stil (Schriftsprache), der in der chinesischen KI-Forschung üblich ist (z. B. Verwendung von „由此产生的模型“ für „The resulting model“).Struktur: Die komplexe Satzstruktur des Originals wurde so angepasst, dass der logische Fluss im Chinesischen natürlich wirkt, ohne die technische Kausalität zu verändern.
One-sentence Summary
By utilizing the Preference-Anchored Rationalization (PARROT) framework to generate explicit, multi-dimensional critiques alongside scores, the 8B parameter RationalRewards model improves visual generation through fine-grained reinforcement learning at training time and a parameter-free Generate-Critique-Refine loop at test time.
Key Contributions
- The paper introduces RationalRewards, a reasoning-based reward model that replaces opaque scalar scores with structured, multi-dimensional chain-of-thought critiques to provide interpretable and fine-grained feedback.
- This work presents PARROT, a variational framework that enables the training of such models by recovering high-quality rationales from existing preference data through anchored generation, consistency filtering, and distillation.
- The proposed method demonstrates superior performance by achieving state-of-the-art preference prediction with 10 to 20 times less training data than baselines and enables a test-time Generate-Critique-Refine loop that improves generation quality without parameter updates.
Introduction
As visual generation models advance toward higher photorealism and better instruction following, the quality of reward models has become a critical bottleneck. Most existing reward models function as scalar black boxes that compress complex human judgments like perceptual quality and text faithfulness into a single, unexplained number. This lack of transparency often leads to reward hacking, where generators exploit statistical shortcuts rather than learning principled evaluation criteria.
The authors introduce RationalRewards, a reasoning-based reward model that produces structured, multi-dimensional critiques before assigning a score. This approach transforms the reward model from a passive evaluator into an active optimization tool that works in two ways: it provides fine-grained, interpretable feedback for reinforcement learning during training, and it enables a Generate-Critique-Refine loop to optimize prompts at test time without parameter updates. To enable this without expensive human annotations, the authors propose the Preference-Anchored Rationalization (PARROT) framework, which recovers high-quality rationales from existing preference data. RationalRewards achieves state-of-the-art performance among open-source models, matching or exceeding the effectiveness of expensive reinforcement learning through its test-time reasoning capabilities.
Dataset

The authors develop a reasoning-annotated dataset for image generation and editing tasks using the following methodology:
- Dataset Composition and Sources: The training data is derived from two primary preference datasets:
- Image Editing: 30,000 query-preference pairs sourced from EditReward.
- Text-to-Image Generation: 50,000 pairs sourced from HPDv3 and RapidData.
- Data Processing and Annotation:
- Rationale Generation: Because the source datasets only provide binary or ranked labels, the authors use the PARROT pipeline with Qwen3-VL-32B-Instruct as a teacher model to transform raw preference pairs into training data containing structured reasoning rationales.
- Consistency Filtering: A Phase 2 consistency check is applied to remove hallucinated or uninformative samples. This process retains approximately 72% of the generated rationales.
- Data Scale and Efficiency:
- The final dataset consists of approximately 57,600 samples after filtering (down from 80,000 raw pairs).
- The authors note that this scale is 10 to 20 times smaller than comparable baselines, such as EditReward or UnifiedReward, due to the efficiency of distilling structured rationales rather than raw labels.
- Task-Specific Configurations:
- For text-to-image generation, the input is modified to include only two generated images without a source image.
- The "Image Faithfulness" dimension is removed for these tasks, and the instruction is adjusted to compare the images against the user prompt.
- Each pairwise sample is processed into two pointwise projection samples for training.
Method
The authors leverage a three-phase pipeline, Preference-Anchored Rationalization (PARROT), to train a reward model that produces explicit, multi-dimensional rationales before scoring. This framework operates within a variational inference framework, treating the rationale as a latent variable explaining human preferences derived from pairwise comparison data. The overall process decomposes into distinct stages: rationale generation, predictive consistency filtering, and foresight distillation, which together form a structured learning procedure grounded in the Evidence Lower Bound (ELBO).
The first phase, rationale generation, employs a teacher Vision-Language Model (VLM) to infer a natural language explanation z for a given preference y (e.g., A≻B) from a comparison tuple x=(IA,IB,c), where IA and IB are generated images and c is a conditioning user request. This phase is implemented as a "hindsight" process, where the teacher model is explicitly conditioned on the ground-truth preference label y to generate a rationale. This preference anchoring ensures that the generated explanations are focused on justifying the observed preference, concentrating the model's probability mass on coherent and relevant rationales, as opposed to open-ended, unguided evaluation. The rationale is structured to assess four key dimensions: text faithfulness, image faithfulness, physical/visual quality, and text rendering, with each dimension scored on a 1-4 scale.
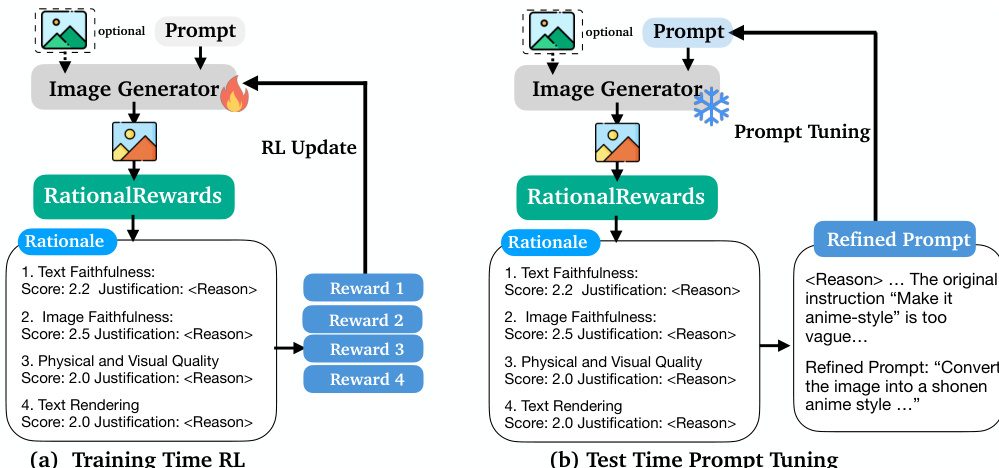
The second phase, predictive consistency filtering, addresses the issue of generating linguistically plausible but semantically insufficient rationales. While the first phase produces rationales conditioned on the known preference, a rationale must be predictive of the preference to be valid. To enforce this, the authors perform a consistency check by re-querying the teacher VLM with the generated rationale z alone, without the preference label. The model is asked to predict the preference y based solely on the rationale. Only if the predicted preference matches the original ground-truth label is the (x,y,z) triplet retained for training. This process, which maximizes Term 1 of the ELBO, filters out hallucinated or insufficiently informative rationales, ensuring that the remaining rationales are causally sufficient to explain the observed preference.

The third phase, foresight distillation, trains the student model Pθ(z∣x) to generate rationales without access to the preference label, effectively learning the "foresight" capability. This is achieved through supervised fine-tuning (SFT) on the filtered posterior samples from the first two phases. The goal is to minimize the KL divergence between the learned student prior Pθ(z∣x) and the fixed variational posterior qϕ(z∣x,y), which is equivalent to maximizing the expected log-likelihood of the student generating the filtered rationales. This results in a student model that can generate coherent, multi-dimensional rationales for a given input image and prompt, enabling it to function as a pointwise reward evaluator.
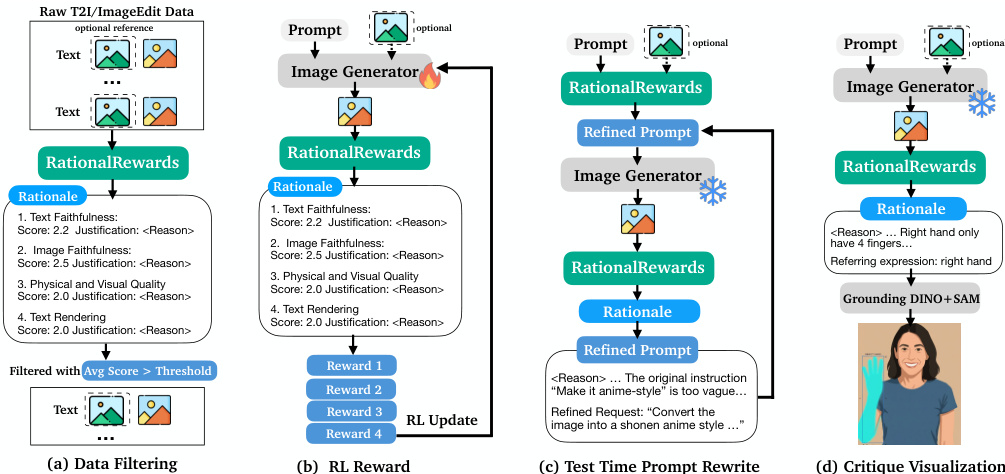
The trained model, RationalRewards, is designed for dual deployment in both parameter and prompt spaces. For parameter-space optimization, the multi-dimensional scores are aggregated into a scalar reward, which is used to guide reinforcement learning algorithms like DiffusionNFT. For prompt-space optimization, the natural language rationales are used to generate a targeted refinement of the original user prompt, enabling a Generate-Critique-Refine loop at test time. This allows for high-quality image generation without any parameter updates, leveraging the model's internalized preference objective to guide prompt refinement.
Experiment
The experiments evaluate the utility of RationalRewards for improving text-to-image generation and image editing through two optimization strategies: parameter-space tuning via reinforcement learning (RL) and prompt-space tuning via test-time critique-and-refinement. Results across multiple benchmarks, including ImgEdit-Bench and UniGen, demonstrate that RationalRewards-guided RL consistently outperforms both scalar reward models and generic reasoning baselines. Notably, inference-time prompt tuning provides improvements comparable to or exceeding computationally expensive RL, suggesting that the model's latent capabilities are effectively elicited through structured critiques rather than weight modifications alone.
The the the table shows the reduction of raw pairs to final samples after filtering for three datasets used in the study. The filtering process significantly reduces the number of raw pairs while increasing the proportion of high-quality pointwise samples. Raw pairs are filtered to produce a smaller set of high-quality final samples. The filtering process increases the density of pointwise samples for each dataset. The datasets vary in the number of raw pairs and final samples after filtering.

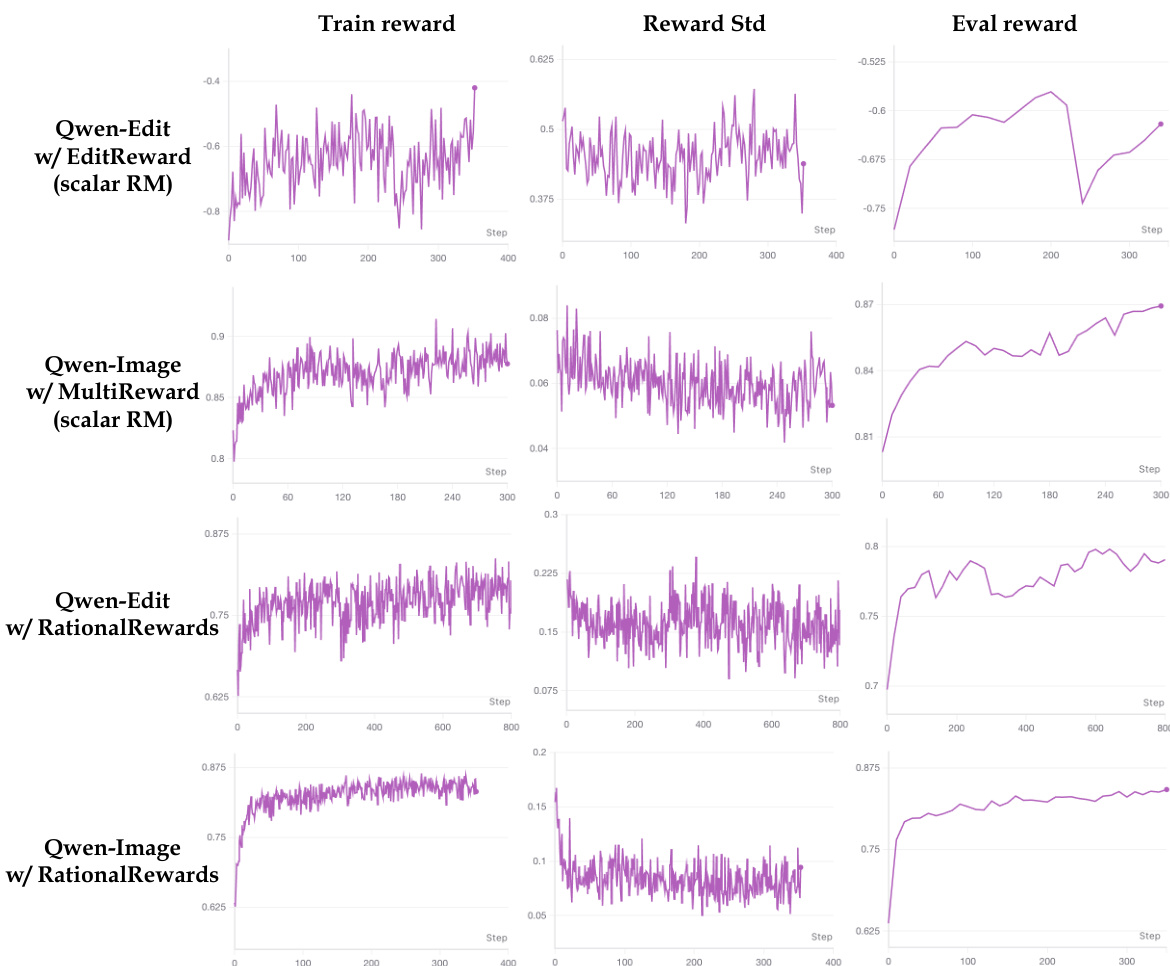
The authors compare the training dynamics of different reward models, showing that RationalRewards leads to more stable and convergent reward signals compared to scalar reward models. The training reward and evaluation reward curves for RationalRewards exhibit smoother behavior and reduced variance over time. RationalRewards produces more stable training reward signals than scalar reward models. Reward standard deviation decreases over time with RationalRewards, indicating improved training stability. Evaluation reward curves align well with target benchmarks when using RationalRewards.
{"caption": "Ablation of RationalRewards on benchmarks", "summary": "The authors evaluate RationalRewards across multiple benchmarks, comparing its performance against scalar and reasoning-based reward models. Results show that RationalRewards consistently outperforms baselines, achieving higher scores on both text-to-image and editing tasks, with notable improvements in both parameter-space and prompt-space optimization.", "highlights": ["RationalRewards achieves superior performance compared to scalar and generic reasoning baselines across all evaluated benchmarks.", "Prompt tuning with RationalRewards matches or exceeds the effectiveness of computationally expensive parameter-space tuning.", "RationalRewards shows strong gains on both text-to-image and image editing tasks, demonstrating broad applicability across different domains."]
The authors compare the performance of various models across multiple attributes, including text faithfulness, image quality, and reasoning capabilities. Results show that models enhanced with RationalRewards consistently outperform baseline models across most categories, particularly in tasks requiring complex reasoning and multi-dimensional evaluation. Models using RationalRewards achieve higher overall scores compared to baseline models across multiple attributes. RationalRewards consistently improve performance in complex reasoning and multi-dimensional evaluation tasks. Enhanced models show significant gains in text faithfulness and image quality metrics.
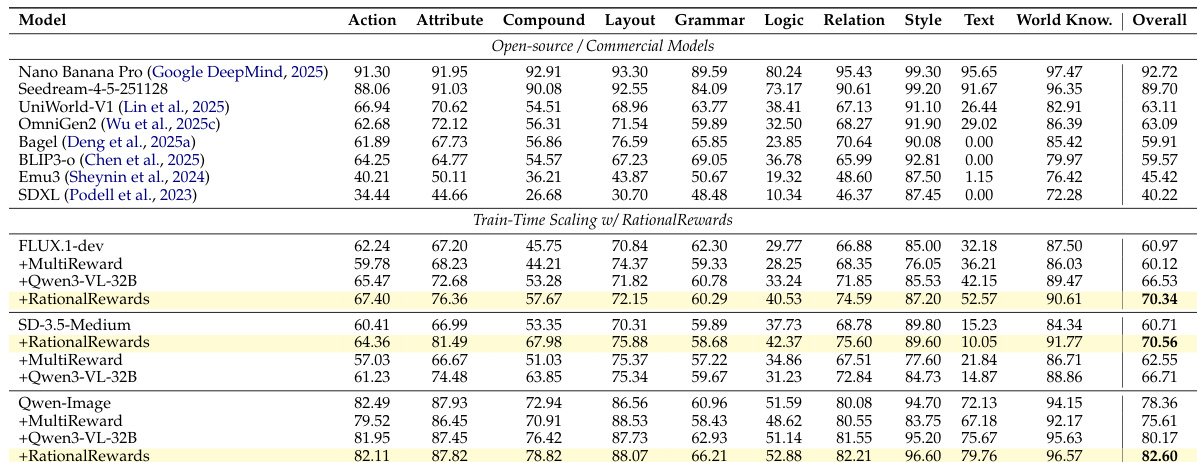
The authors conduct an ablation study to evaluate the performance of RationalRewards in dual-space optimization for image and text-to-image generation tasks. Results show consistent improvements across benchmarks compared to scalar and generic reasoning baselines, with prompt tuning achieving results comparable to or exceeding parameter-space tuning. RationalRewards outperforms scalar and generic reasoning baselines in both parameter and prompt space tuning. Prompt tuning achieves results comparable to or better than computationally expensive parameter-space tuning. RationalRewards enables stable reward gradients and reduces reward hacking during training.

The study evaluates RationalRewards through data filtering processes, training stability comparisons, and ablation studies across various text-to-image and editing benchmarks. The results demonstrate that RationalRewards provides more stable and convergent reward signals compared to scalar models while significantly improving performance in text faithfulness, image quality, and complex reasoning. Furthermore, the method enables efficient prompt tuning that matches or exceeds the effectiveness of computationally expensive parameter-space optimization.