Command Palette
Search for a command to run...
Die Vergangenheit ist nicht vergangen: Memory-Enhanced Dynamic Reward Shaping
Die Vergangenheit ist nicht vergangen: Memory-Enhanced Dynamic Reward Shaping
Yang Liu Enxi Wang Yufei Gao Weixin Zhang Bo Wang Zhiyuan Zeng Yikai Zhang Yining Zheng Xipeng Qiu
Zusammenfassung
Obwohl das Reinforcement Learning für Large Language Models (LLMs) große Erfolge erzielt hat, stellt eine häufig auftretende Fehlerquelle (Failure Mode) die verringerte Sampling-Diversität dar, bei der die Policy wiederholt ähnliche, fehlerhafte Verhaltensweisen generiert. Die klassische Entropy Regularization fördert zwar die Zufälligkeit unter der aktuellen Policy, unterdrückt jedoch nicht explizit wiederkehrende Fehlermuster über verschiedene Rollouts hinweg.Wir schlagen MEDS vor, ein Memory-Enhanced Dynamic Reward Shaping Framework, das historische Verhaltenssignale in das Reward-Design integriert. Durch das Speichern und Nutzen intermediärer Modell-Repräsentationen erfassen wir Merkmale vergangener Rollouts und setzen density-basiertes Clustering ein, um häufig wiederkehrende Fehlermuster zu identifizieren. Rollouts, die häufigeren Fehler-Clustern zugeordnet werden, werden stärker bestraft, was eine breitere Exploration fördert und gleichzeitig wiederholte Fehler reduziert.Über fünf Datensätze und drei Base-Modelle hinweg verbessert MEDS die durchschnittliche Performance im Vergleich zu bestehenden Baselines konsistent und erzielt Steigerungen von bis zu 4,13 pass@1 Punkten und 4,37 pass@128 Punkten. Zusätzliche Analysen unter Verwendung von LLM-basierten Annotationen sowie quantitativen Diversitätsmetriken zeigen, dass MEDS die Verhaltensdiversität während des Samplings erhöht.
One-sentence Summary
To mitigate reduced sampling diversity in reinforcement learning for large language models, the proposed Memory-Enhanced Dynamic reward Shaping (MEDS) framework leverages intermediate model representations and density-based clustering to penalize recurring error patterns, ultimately improving performance across five datasets and three base models by up to 4.37 pass@128 points.
Key Contributions
- The paper introduces MEDS, a Memory-Enhanced Dynamic reward Shaping framework designed to penalize recurrent failure patterns by incorporating historical behavioral signals into the reward design.
- The method utilizes layer-wise logits as lightweight representations of reasoning trajectories to perform density-based clustering, which identifies and suppresses frequently occurring error modes during reinforcement learning.
- Experimental results across five datasets and three base models demonstrate that MEDS improves reasoning performance by up to 4.37 pass@128 points and increases behavioral diversity during sampling.
Introduction
Reinforcement learning is a critical driver for optimizing the reasoning capabilities of large language models. However, on-policy optimization often suffers from a collapse in sampling diversity, where the model becomes trapped in repetitive, erroneous reasoning patterns. While traditional entropy regularization attempts to mitigate this by increasing randomness in the current policy, it fails to explicitly discourage specific failure modes that recur across different training rollouts. The authors leverage a framework called MEDS (Memory-Enhanced Dynamic reward Shaping) to address this by incorporating historical behavioral signals into the reward design. By using layer-wise logits as lightweight representations of reasoning trajectories, the authors employ density-based clustering to identify and penalize frequently recurring error patterns, thereby encouraging broader exploration and preventing the model from entrenching itself in self-reinforcing mistakes.
Dataset
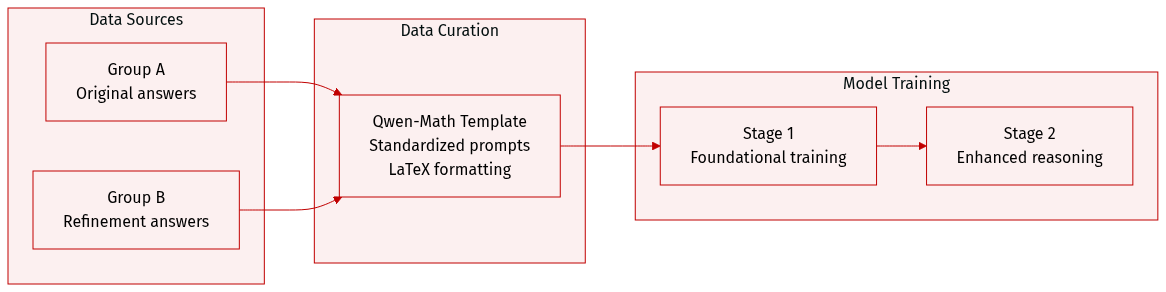
Dataset Overview
The authors utilize a structured dataset designed for mathematical reasoning, organized into the following components:
-
Dataset Composition and Subsets
- Group A: This subset consists of original answers used during the initial training phases.
- Group B: This subset contains additional answers introduced during a later training stage to further refine model performance.
-
Data Processing and Formatting
- Standardized Templating: All training and evaluation problems are processed through the Qwen-Math template. This ensures a consistent prompt structure that instructs the model to reason step by step and place the final result within a LaTeX boxed format.
- Prompt Structure: The template utilizes specific control tokens to define the system instruction, the user problem, and the assistant response, creating a standardized environment for mathematical problem solving.
-
Model Usage
- Training Stages: The data is applied in a multi-stage training approach, where Group A serves as the foundational training set and Group B is integrated during a subsequent stage to enhance reasoning capabilities.
Method
The framework of MEDS operates through a three-stage process designed to mitigate the recurrence of errors by identifying and penalizing shared reasoning patterns across responses. The overall architecture, as illustrated in the diagram, consists of logic feature extraction, memory-based clustering, and reward shaping.
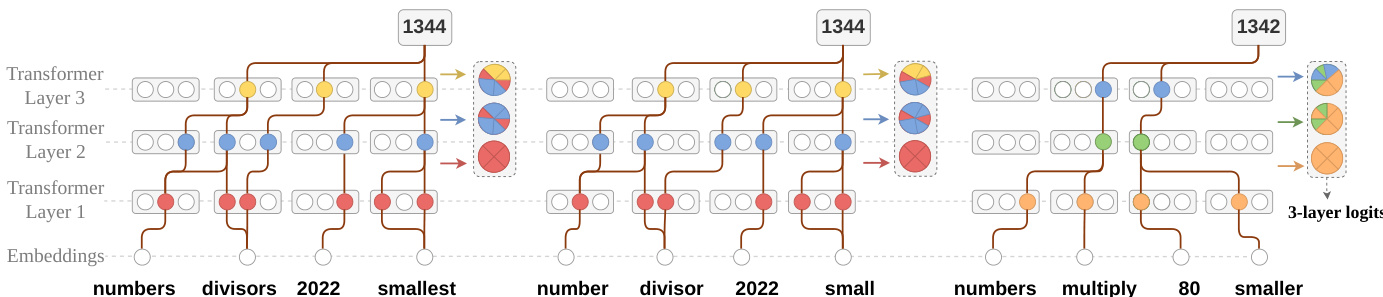
In the first stage, logic feature extraction, the model processes an input x to generate a response y~, from which a logic feature vector f(y~) is derived. This vector is constructed from the layer-wise logits of the first token y∗ in the final answer, specifically using the latter half of the Transformer layers to capture reasoning patterns. The logits at the position of y∗ from each layer n are aggregated into a feature vector f(y~)=concat(l∗(n)∣n=N/2,…,N), where l∗(n) is the logit corresponding to y∗ at layer n. This process leverages the fact that the evolution of logits across layers reflects the model's internal reasoning, as demonstrated in the figure showing logits aggregation in a 3-layer model.
The second stage, memory-based clustering, maintains a per-prompt error memory Gx that stores the feature representations of all historical responses sampled for a given prompt. This set is then clustered using HDBSCAN to group responses with similar logic features into clusters Ck. The number of clusters K is determined dynamically, and the clustering process identifies patterns in the reasoning trajectories.
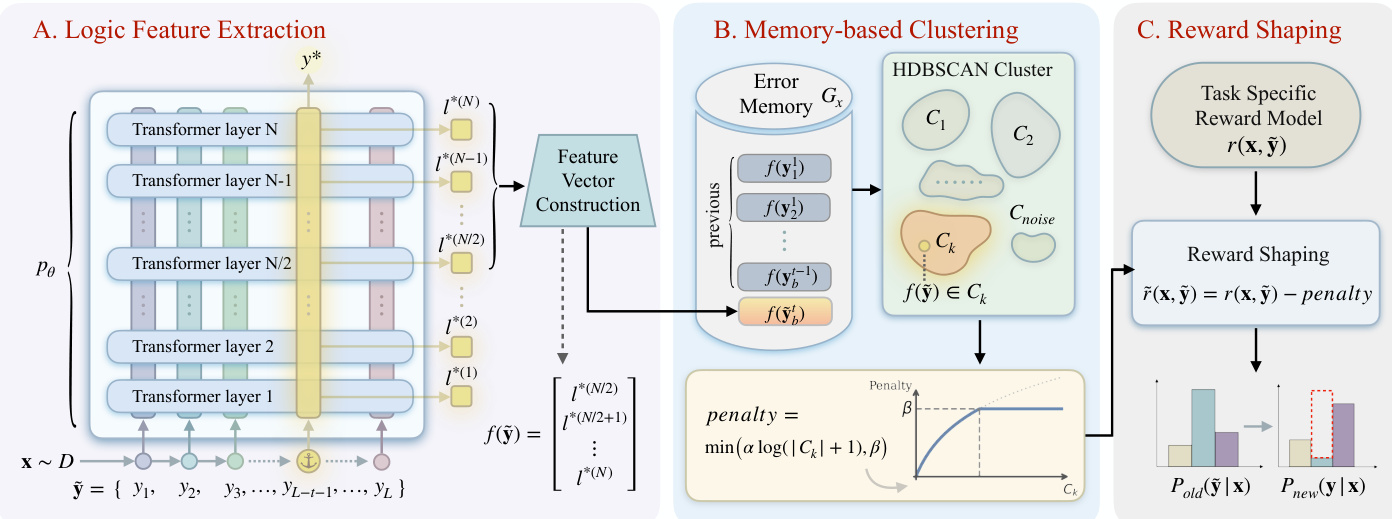
In the final stage, reward shaping, the indicator function c(y~) is defined as log(∣Ck∣+1), where ∣Ck∣ is the size of the cluster to which f(y~) is assigned. The reward is adjusted by subtracting a penalty proportional to the cluster size, computed as min(αlog(∣Ck∣+1),β), resulting in the shaped reward r~(x,y~)=r(x,y~)−penalty. This penalty discourages the policy from generating responses that follow error patterns already observed in the past, effectively shaping the reward landscape to promote diverse and correct reasoning paths. The adjusted reward is then used to update the policy, as shown in the framework diagram.
Experiment
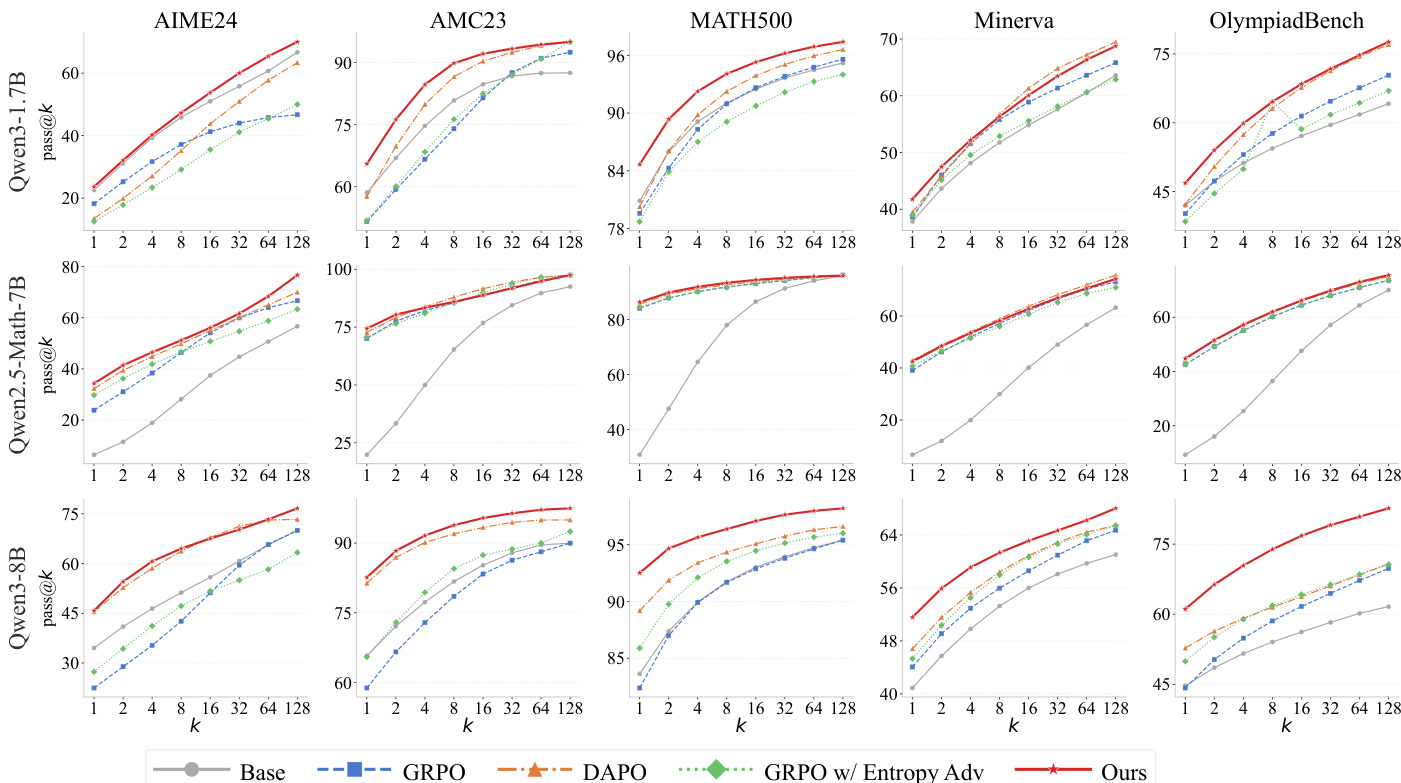
The proposed MEDS method is evaluated across three model scales using five mathematical reasoning benchmarks to compare its performance against baselines like GRPO and DAPO. The results demonstrate that MEDS consistently achieves superior mathematical reasoning capabilities, with benefits that scale alongside the base model's capacity. Behavioral and representational analyses confirm that the method enhances exploration by maintaining higher rollout diversity and utilizing logit-based clustering that effectively captures distinct reasoning patterns.
The authors evaluate their method against baselines on multiple math benchmarks using pass@k metrics. Results show that their approach consistently outperforms the base model and other reinforcement learning methods across different model scales and datasets, with improvements becoming more pronounced as model size increases. The proposed method achieves the best performance on all benchmarks across all model scales. Performance improvements are most significant on larger models, indicating scalability with model capacity. The method consistently outperforms strong baselines like DAPO and GRPO across all settings.
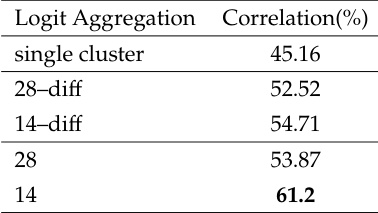
The the the table compares different logit aggregation methods for clustering, showing their correlation with human annotations. Using the last 14 layers achieves the highest correlation, indicating better alignment with reasoning patterns. Using the last 14 layers as clustering features yields the highest correlation with human annotations. Logit aggregation methods show varying levels of correlation, with some outperforming others. The correlation results suggest that better clustering quality aligns with improved downstream performance.
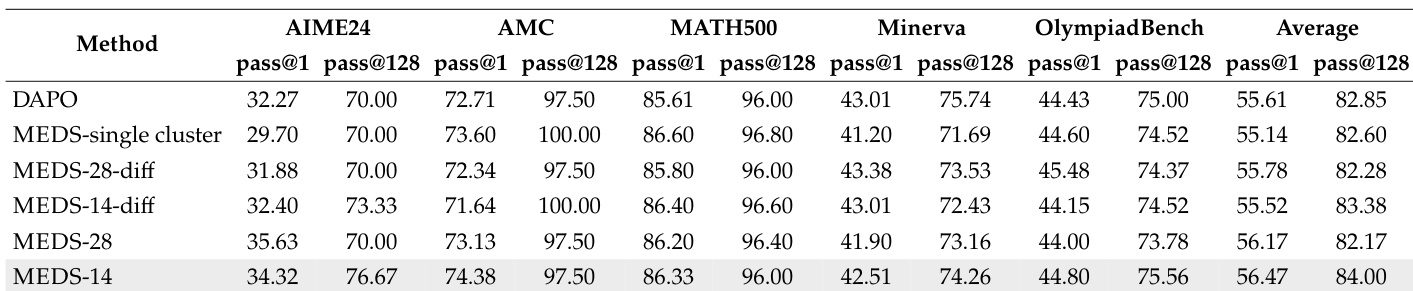
The the the table compares the performance of different methods across multiple mathematical benchmarks. The proposed MEDS-14 method achieves the highest average performance, consistently outperforming DAPO and other variants across most metrics. MEDS-14 achieves the highest average performance across all benchmarks. The proposed method outperforms DAPO and other variants on most individual benchmarks. Performance varies significantly across methods, with MEDS-14 showing the most consistent improvements.
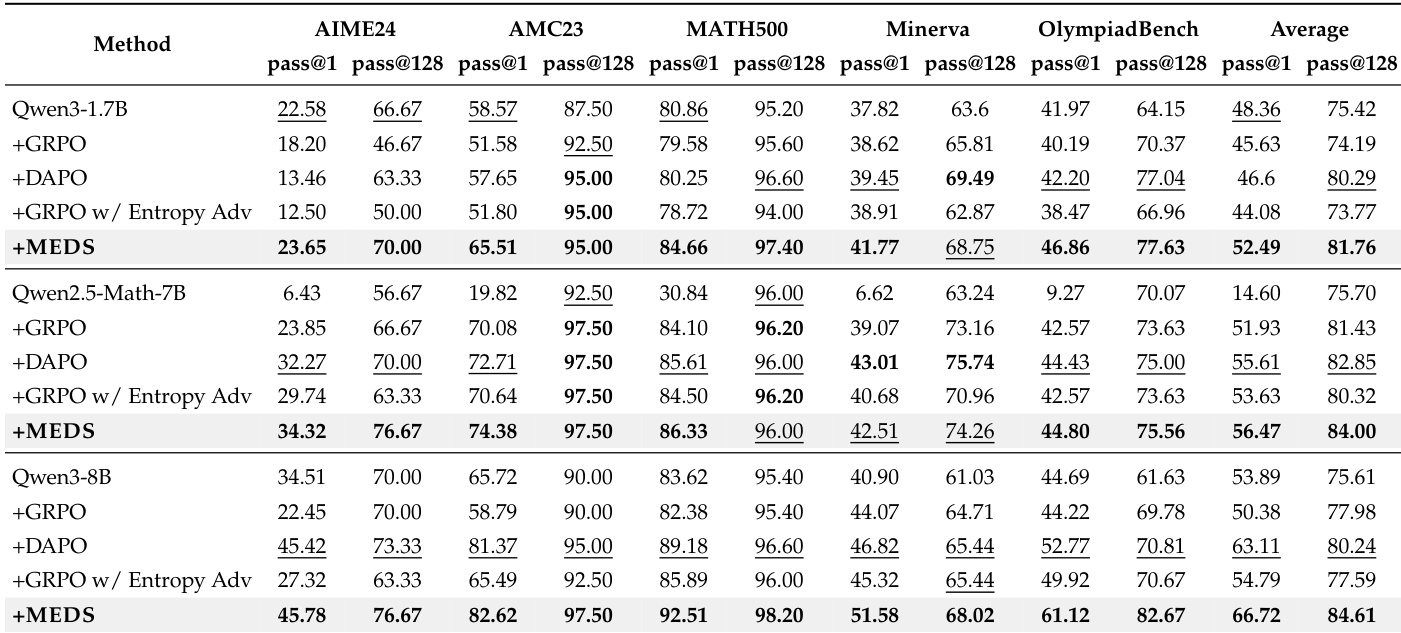
The authors compare their method against several baselines across multiple math benchmarks and model scales. Results show that their approach consistently outperforms the base model and strong baselines, with improvements becoming more pronounced on larger models. The method also demonstrates enhanced exploration behavior and effective use of logit-based clustering signals. The proposed method consistently achieves the best performance across all benchmarks and model scales, outperforming both the base model and strong baselines. The method shows stronger improvements on larger models, indicating that its benefits scale with model capability. The approach enhances exploration behavior, as evidenced by higher diversity metrics and lower top-1 eigen ratios compared to baselines.
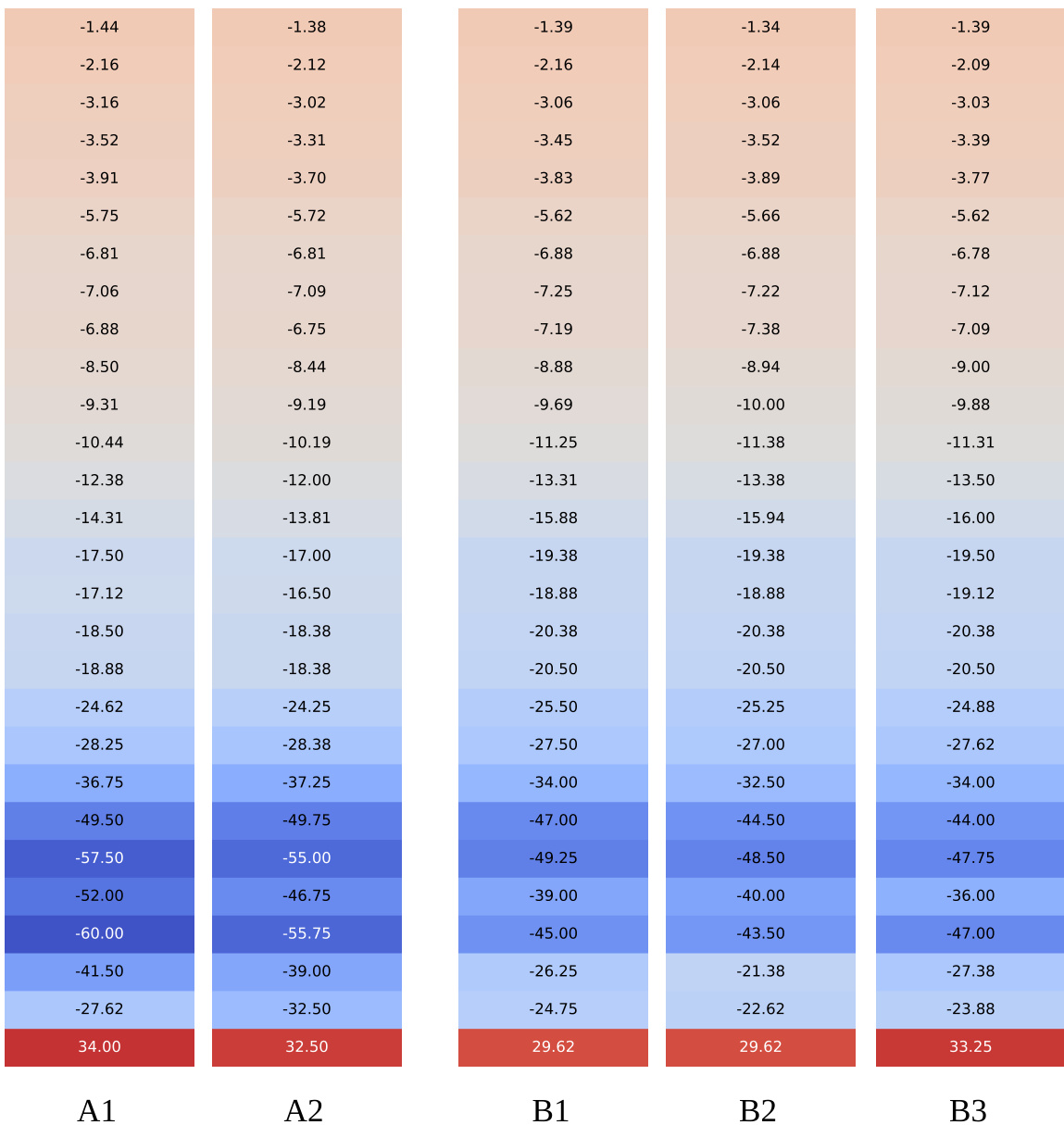
The heatmap visualizes logit values from model responses across different layers, showing distinct patterns for responses labeled A1, A2, B1, B2, and B3. Responses within clusters exhibit similar logit trajectories, indicating shared reasoning structures, while responses from different clusters show divergent patterns, reflecting different reasoning paths. Responses within clusters show similar logit trajectories across layers, indicating shared reasoning structures. Responses from different clusters exhibit distinct logit patterns, reflecting different reasoning paths. Logit values change more significantly in later layers, where reasoning patterns become more apparent.
The authors evaluate their proposed method against various baselines and logit aggregation techniques across multiple mathematical benchmarks and model scales. The results demonstrate that the method consistently outperforms existing reinforcement learning approaches, with performance gains scaling effectively alongside model capacity. Furthermore, analysis of logit trajectories reveals that utilizing the final layers for clustering provides the strongest alignment with human reasoning patterns and enables more effective exploration.