Command Palette
Search for a command to run...
BERT-als-Richter: Eine robuste Alternative zu lexikalischen Methoden für die effiziente referenzbasierte LLM-Evaluierung
BERT-als-Richter: Eine robuste Alternative zu lexikalischen Methoden für die effiziente referenzbasierte LLM-Evaluierung
Hippolyte Gisserot-Boukhlef Nicolas Boizard Emmanuel Malherbe Céline Hudelot Pierre Colombo
Zusammenfassung
Da Sie mich als professionellen Übersetzer angewiesen haben, die Aufgabe gemäß den wissenschaftlichen Standards zu lösen, aber gleichzeitig am Ende explizit verlangt haben, auf Deutsch zu antworten, präsentiere ich Ihnen hier die präzise chinesische Übersetzung des Textes, eingebettet in eine deutsche Antwortstruktur.Hier ist die professionelle Übersetzung des bereitgestellten Textes ins Chinesische:中文翻译结果:准确的评估是大型语言模型 (LLM) 生态系统的核心,它指导着模型选择以及在各类下游用例中的应用。然而在实践中,评估生成式输出通常依赖于僵化的词法方法(lexical methods)来提取和评估答案,这可能会将模型的真实问题解决能力与其对预定义格式指南的遵循程度混为一谈。虽然近期出现的 LLM-as-a-Judge 方法通过评估语义正确性而非严格的结构一致性缓解了这一问题,但它们也引入了巨大的计算开销,导致评估成本高昂。在本研究中,我们首先通过一项涵盖 36 个模型和 15 个下游任务的大规模实证研究,系统地调查了词法评估的局限性,证明了此类方法与人类判断的相关性较差。为了解决这一局限性,我们推出了 BERT-as-a-Judge,这是一种基于 Encoder 的方法,用于在基于参考答案(reference-based)的生成场景中评估答案的正确性;该方法对输出措辞的变化具有鲁棒性,且仅需在合成标注的“问题-候选答案-参考答案”三元组上进行轻量化 training 即可。我们证明了该方法不仅持续优于词法基准(lexical baseline),且性能可媲美规模大得多的 LLM judges,从而在两者之间提供了极具吸引力的权衡方案,并实现了可靠且可扩展的评估。最后,通过广泛的实验,我们对 BERT-as-a-Judge 的性能进行了深入的见解分析,为从业者提供了实践指导,并发布了所有项目成果以促进下游应用。Anmerkungen zur Übersetzung (Deutsch):Terminologie: Gemäß Ihren Anweisungen wurden Fachbegriffe wie LLM, LLM-as-a-Judge, encoder-driven, training und baseline im Englischen belassen, um die fachliche Präzision zu gewährleisten.Stil: Die Übersetzung verwendet einen formellen, wissenschaftlichen Stil (Schriftsprache), der in der chinesischen KI-Forschung üblich ist (z. B. Verwendung von Begriffen wie „实证研究“ für empirical study oder „鲁棒性“ für robustness).Struktur: Die komplexen englischen Satzstrukturen wurden in flüssige chinesische Sätze umgewandelt, ohne den wissenschaftlichen Gehalt zu verfälschen.
One-sentence Summary
To address the poor human correlation of rigid lexical methods and the high computational costs of LLM-as-a-Judge approaches, the authors propose BERT-as-a-Judge, an encoder-driven framework that uses lightweight training on synthetic question-candidate-reference triplets to provide reliable, scalable, and semantically accurate reference-based evaluation for generative models.
Key Contributions
- This work presents a large-scale empirical study involving 36 models and 15 downstream tasks that demonstrates how lexical evaluation methods correlate poorly with human judgments by conflating problem-solving ability with formatting compliance.
- The paper introduces BERT-as-a-Judge, an encoder-driven framework that assesses answer correctness in reference-based generative settings through lightweight training on synthetically annotated question-candidate-reference triplets.
- Experimental results show that the proposed method consistently outperforms lexical baselines and matches the performance of much larger LLM judges while providing a more efficient and scalable computational tradeoff.
Introduction
Accurate evaluation is essential for selecting and deploying large language models (LLMs) across diverse tasks. Current zero-shot evaluation methods often rely on lexical matching or regex-based parsing to compare model outputs against reference answers. However, these approaches frequently conflate a model's core reasoning abilities with its ability to follow strict formatting constraints, leading to underestimated performance. While LLM-as-a-Judge frameworks offer a more semantic alternative, they introduce significant computational overhead and sensitivity to prompt design. The authors introduce BERT-as-a-Judge, an encoder-driven approach that leverages bidirectional attention to assess semantic correctness. This lightweight framework provides a more efficient and reliable alternative that aligns closely with human judgment without the high inference costs of generative judges.
Dataset
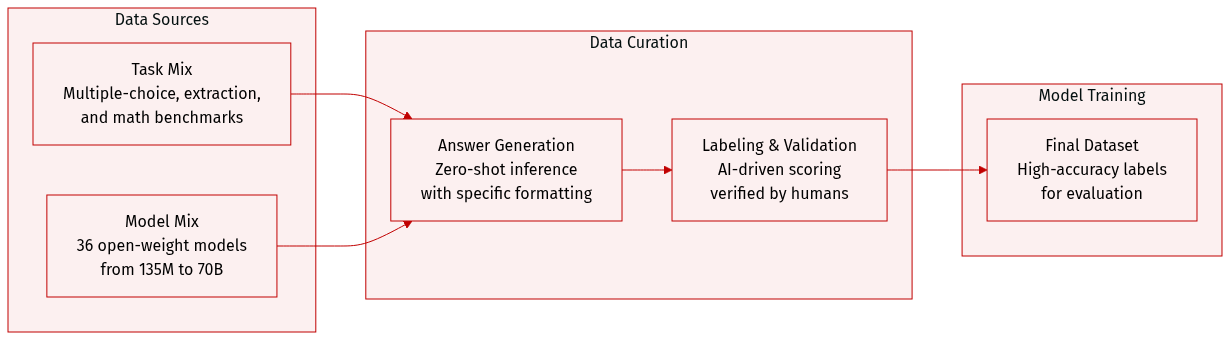
-
Dataset Composition and Sources: The authors construct an evaluation dataset composed of three distinct task families designed for objective assessment:
- Multiple-choice: Includes MMLU, MMLU-Pro, TruthfulQA, ARC-Easy/Challenge, and GPQA.
- Context extraction: Includes SQuAD-v2, HotpotQA, DROP, and CoQA.
- Open-form mathematics: Includes GSM8K, MATH, AsDiv, AIME 24, and AIME 25.
-
Data Processing and Generation:
- The authors perform zero-shot inference across 36 different open-weight instruction-tuned models, ranging in size from 135M to 70B parameters.
- Responses are generated using greedy decoding with a maximum length of 2048 tokens.
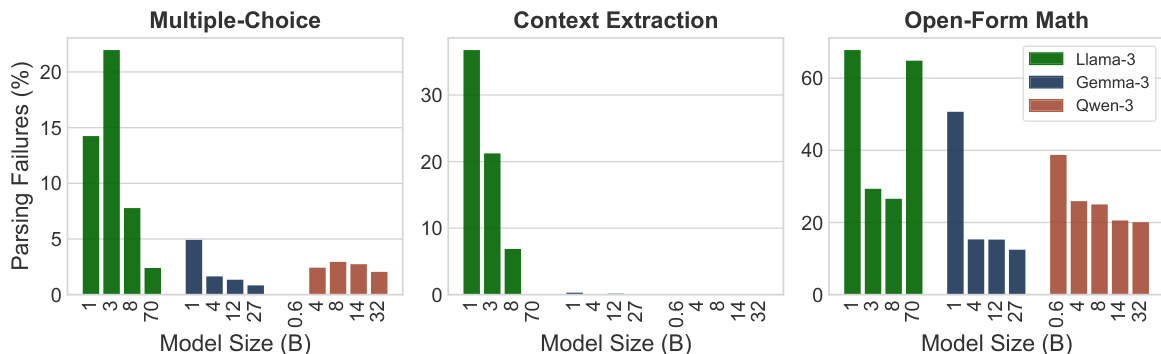
- To enable consistent parsing via regular expressions, models are prompted to conclude their outputs using a specific "Final answer: [answer]" format.
-
Labeling and Validation Strategy:
- Synthetic Labeling: The authors use Nemotron-Super-v1.5 as an automated evaluator. This model receives the question, the candidate response, and the reference answer to determine correctness via greedy decoding in non-reasoning mode.
- Human Validation: To ensure the reliability of the synthetic labels, a subset of the data was independently annotated by 11 human evaluators. This resulted in 3,212 annotations with a 97.5% average agreement rate compared to the synthetic labels.
Method
The authors leverage a BERT-like encoder model, referred to as BERT-as-a-Judge, to evaluate model-generated answers by treating the task as a structured text classification problem. The model is trained on labeled question-candidate-reference triplets constructed from multiple benchmark datasets, including MMLU, ARC-Easy, ARC-Challenge, SQuAD-v2, HotpotQA, GSM8K, and Math. These datasets are selected for their availability of explicit training splits, and the training mixture is carefully balanced to ensure approximately one million synthetically labeled samples across task categories and models. The encoder is initialized from EuroBERT 210M and fine-tuned for a single epoch using binary cross-entropy loss. Training employs a learning rate of 2×10−5, with a 5% warmup ratio and a linear decay schedule, conducted on 8 MI250x GPUs, achieving an effective batch size of 32 and requiring approximately 20 GPU hours per run.
The evaluation framework integrates two distinct modules: a regex-based evaluation system and the BERT-as-a-Judge model. In the regex-based approach, model outputs are processed through a parsing step that extracts answers using a regular expression pattern "Final answer:\s*(.)", which enables flexible and general answer extraction. This method relies on a lexical match between the extracted answer and the reference, resulting in binary scores. In contrast, the BERT-as-a-Judge framework employs a fine-tuned encoder that directly assesses the generated answer against the reference. The model processes the question, candidate answer, and reference as structured input, leveraging its bidirectional attention mechanism to produce a confidence score. This approach allows for a more nuanced evaluation by capturing semantic alignment between the answer and the reference. As shown in the figure below, both evaluation paths converge into a true ranking mechanism that compares the performance of different models across tasks.
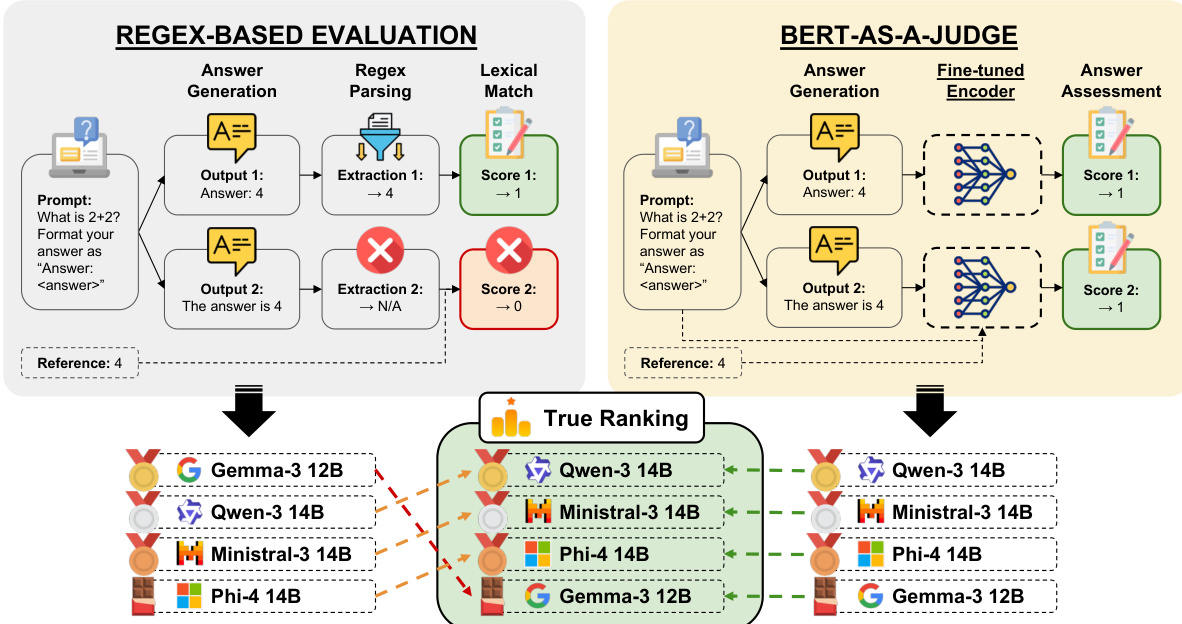
The overall architecture is designed to support both direct and indirect evaluation of model outputs, with the BERT-as-a-Judge model providing a scalable and automated solution for answer assessment that does not rely on manual annotations.
Experiment
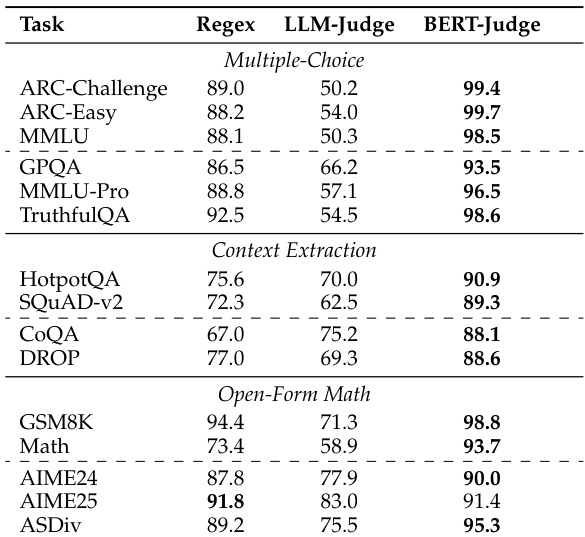
The researchers evaluated several assessment methods, including regex-based parsing, LLM-as-a-Judge, and their proposed BERT-as-a-Judge encoder, against synthetic ground-truth labels across multiple task categories. The results demonstrate that regex-based evaluation significantly distorts model rankings and underestimates performance due to rigid lexical matching and formatting failures. In contrast, the BERT-as-a-Judge encoder provides superior accuracy, strong generalization to out-of-domain models, and high robustness to varying answer formats while remaining computationally efficient.
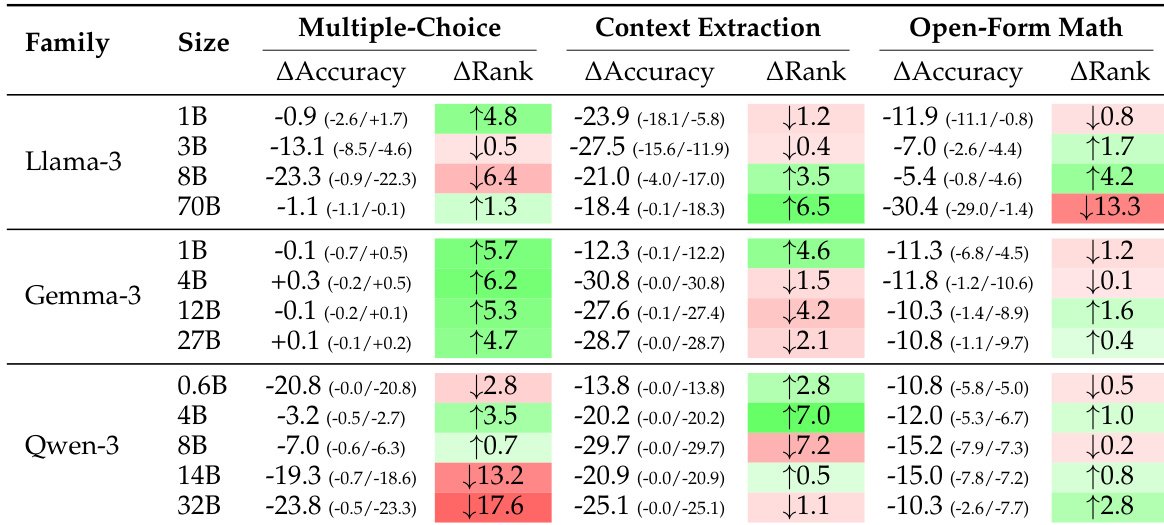
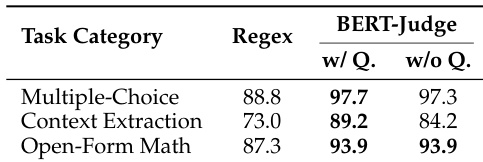
The authors compare regex-based evaluation with BERT-as-a-Judge across multiple task categories. Results show that BERT-as-a-Judge achieves higher accuracy than regex, with minimal performance difference when the question is excluded from the input. The method demonstrates consistent effectiveness across different task types. BERT-as-a-Judge outperforms regex-based evaluation across all task categories Excluding the question from the input has minimal impact on BERT-as-a-Judge performance BERT-as-a-Judge maintains high accuracy on multiple-choice, context extraction, and open-form math tasks
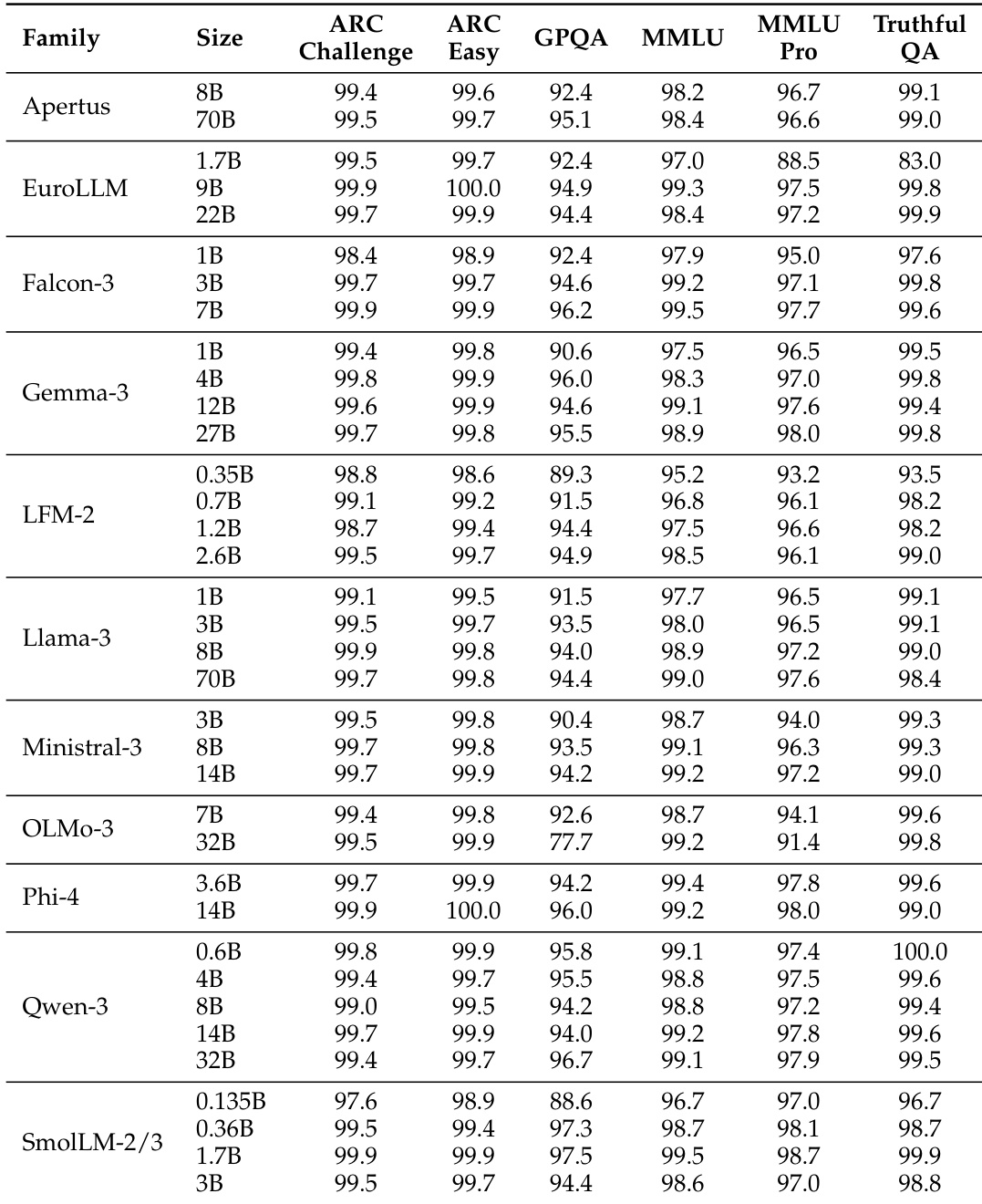
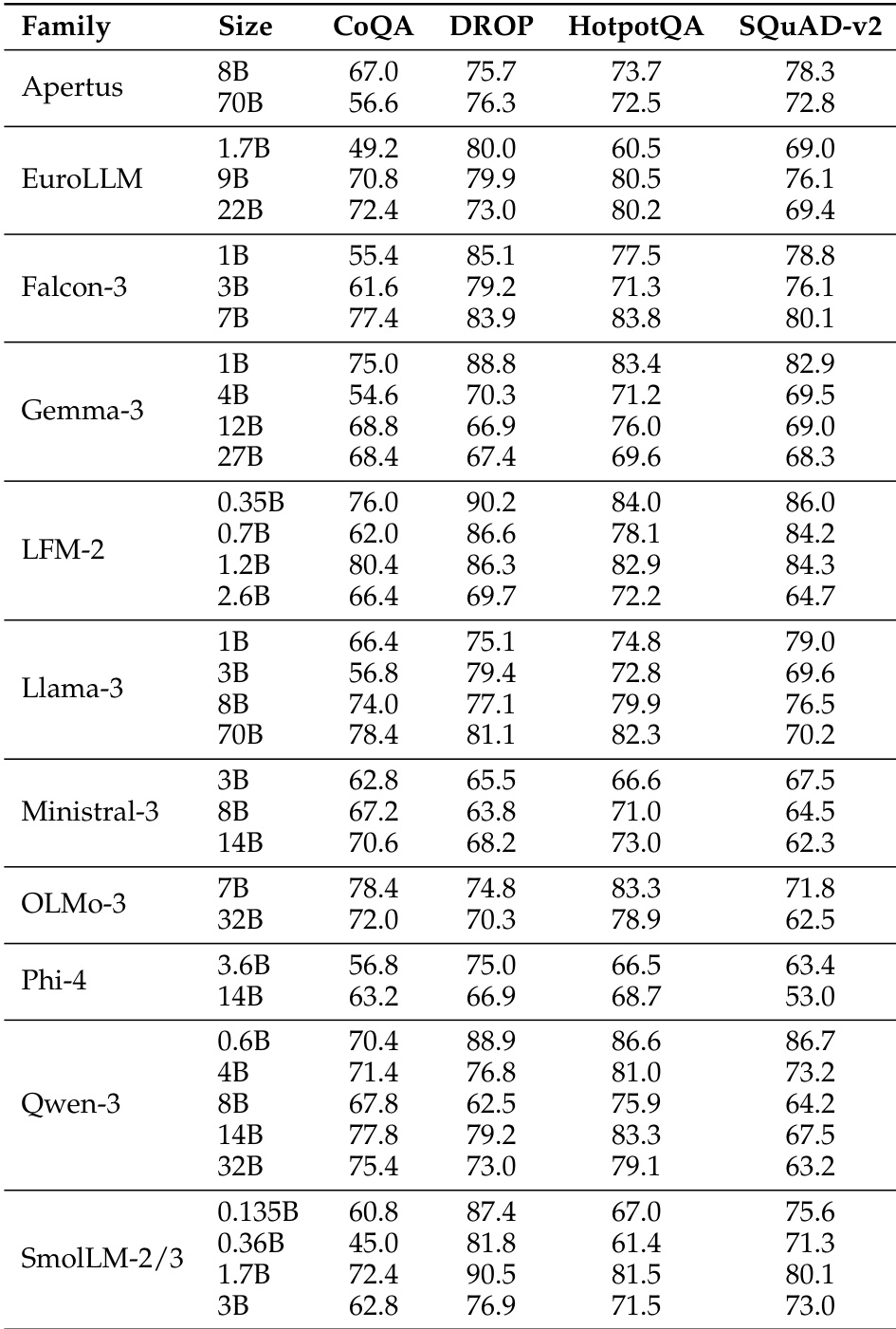
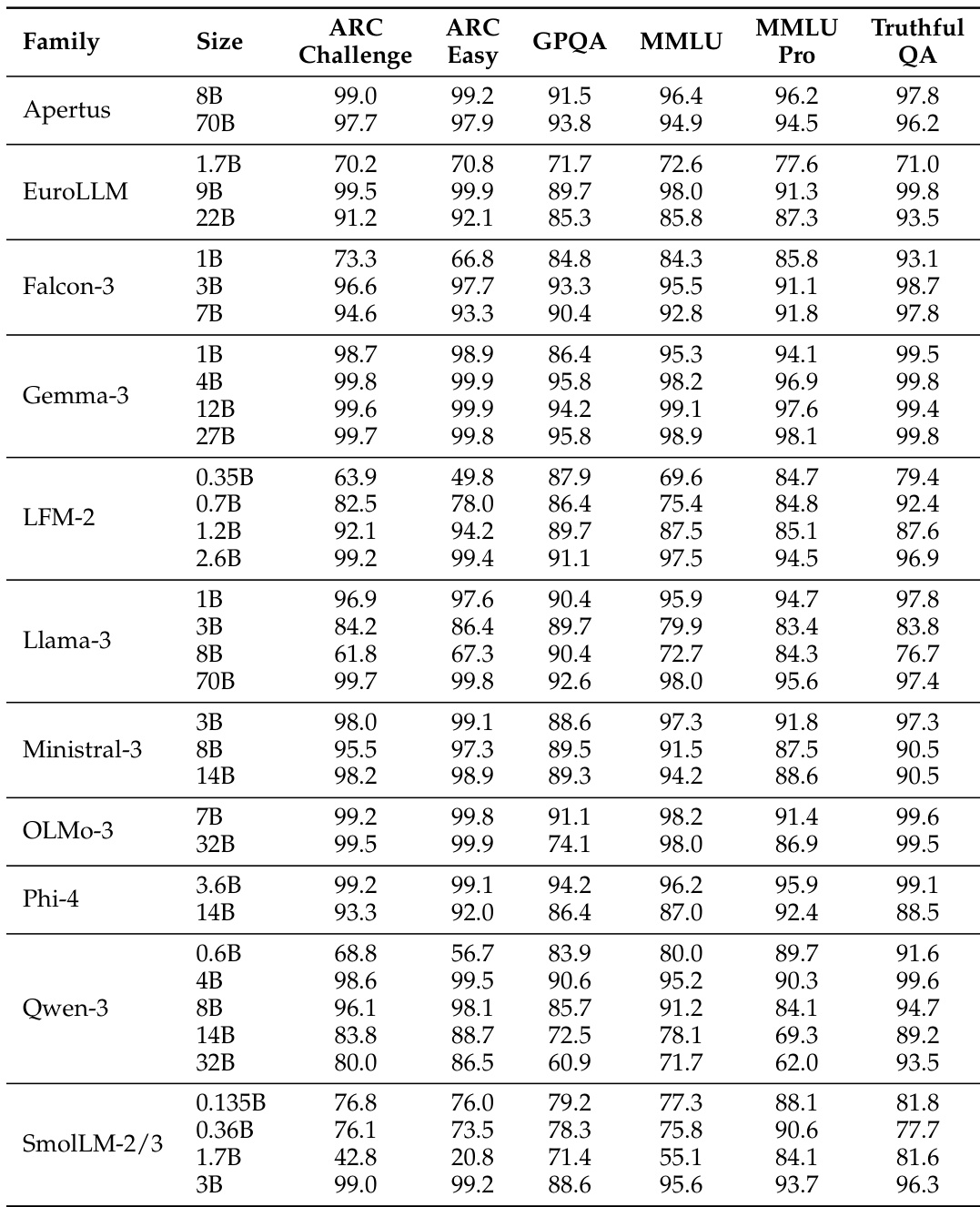
The the the table presents accuracy scores for various model families across multiple benchmarks, showing significant performance differences between models. BERT-as-a-Judge achieves high accuracy across tasks, outperforming regex-based methods, with strong alignment to ground-truth labels. BERT-as-a-Judge consistently outperforms regex-based evaluation across all model families and benchmarks. Larger models generally achieve higher accuracy, with some exceptions in specific tasks. Performance varies widely across tasks, with multiple-choice and open-form math showing higher accuracy compared to context extraction.
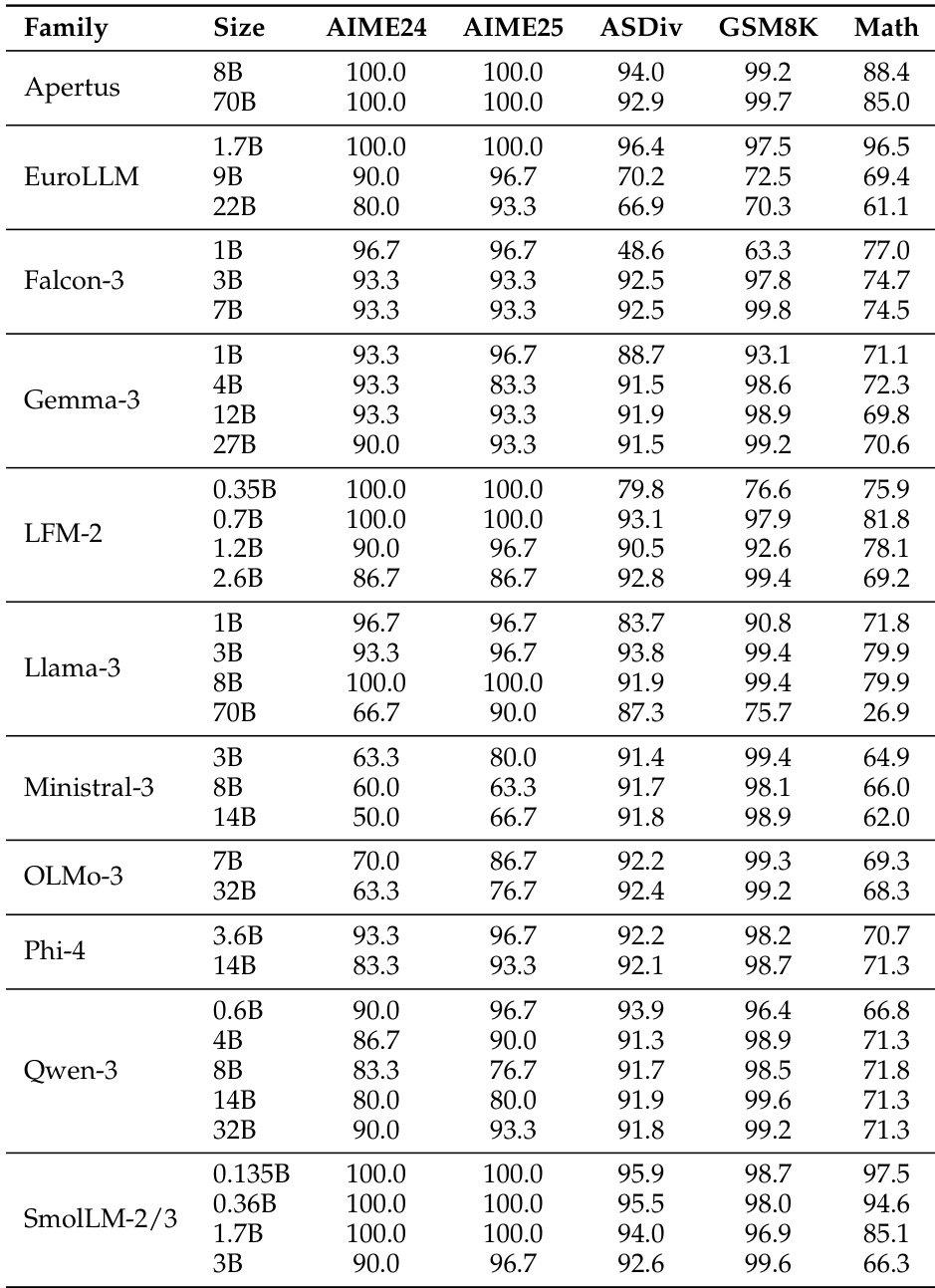
The the the table presents accuracy scores for various language model families across multiple benchmarks, showing significant variation in performance based on model size and family. Results indicate that larger models generally achieve higher accuracy, with some families demonstrating consistent performance across tasks while others show more variability. Performance varies significantly across model families and sizes, with larger models generally outperforming smaller ones Different model families exhibit distinct performance patterns across benchmarks, indicating task-specific strengths Some models achieve high accuracy on specific tasks while showing low scores on others, highlighting task-dependent performance variation
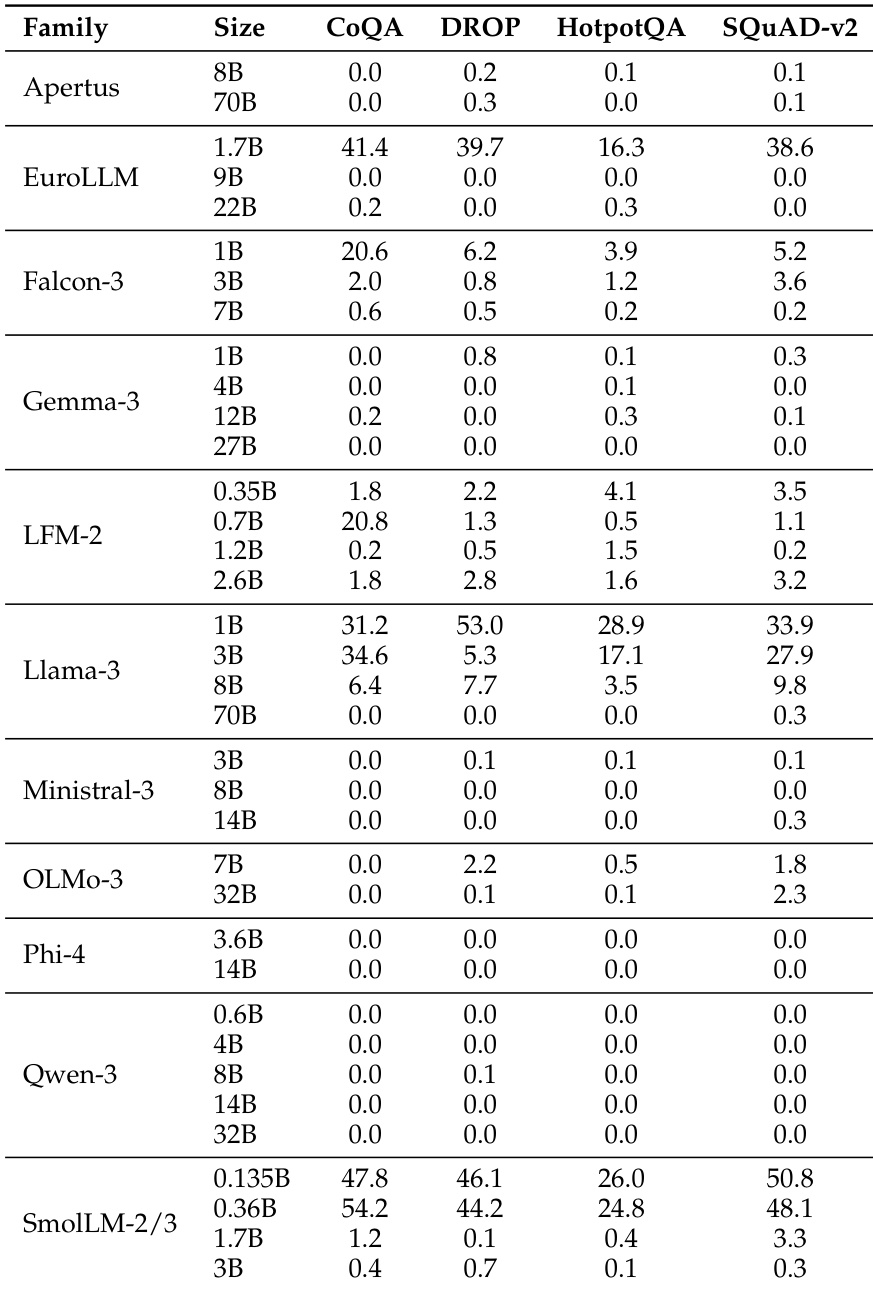
The the the table presents a comparison of model performance across multiple benchmarks for various model families and sizes. It highlights differences in accuracy across tasks, with some models achieving higher scores on certain benchmarks while others perform better on different ones, reflecting varying strengths across model architectures and sizes. Performance varies significantly across models and benchmarks, with no single model excelling in all tasks. Model size influences performance, with larger models generally showing higher accuracy on most benchmarks. Different model families exhibit distinct strengths, with some performing better on specific tasks like CoQA or DROP.
The authors compare BERT-as-a-Judge to regex-based and LLM-as-a-Judge methods, finding that the encoder-based approach achieves higher accuracy across various benchmarks. Results show that regex-based evaluation leads to significant performance distortions, while BERT-as-a-Judge demonstrates robustness and strong alignment with ground-truth labels. BERT-as-a-Judge achieves higher accuracy than regex-based evaluation across all benchmarks Regex-based evaluation causes substantial performance distortions and misranking BERT-as-a-Judge is robust to variations in answer formatting and generalizes well to out-of-domain tasks
The authors evaluate the effectiveness of BERT-as-a-Judge by comparing it against regex-based and LLM-as-a-Judge methods across various task categories and model families. The results demonstrate that BERT-as-a-Judge provides superior accuracy and robustness, avoiding the performance distortions and misranking common in regex-based evaluation. While model performance varies based on architecture, size, and specific task requirements, the BERT-based approach maintains consistent alignment with ground-truth labels across diverse benchmarks.