Command Palette
Search for a command to run...
Ein vergleichender Studienansatz im Bereich der chirurgischen KI: Datensätze, Foundation Models und Barrieren auf dem Weg zu Med-AGI
Ein vergleichender Studienansatz im Bereich der chirurgischen KI: Datensätze, Foundation Models und Barrieren auf dem Weg zu Med-AGI
Zusammenfassung
Künstliche Intelligenz (KI)-Modelle der jüngsten Zeit haben in mehreren Benchmarks für biomedizinische Aufgaben das Leistungsniveau menschlicher Experten erreicht oder sogar übertroffen, hinken jedoch bei Benchmarks zur Analyse chirurgischer Bilder hinterher. Da Chirurgie die Integration unterschiedlicher Teilaufgaben erfordert – darunter multimodale Datenintegration, Interaktion mit Menschen sowie die Berücksichtigung physischer Effekte –, könnten allgemein einsetzbare KI-Modelle als kollaborative Werkzeuge besonders attraktiv sein, sofern ihre Leistungsfähigkeit gesteigert werden kann. Einerseits ist der kanonische Ansatz des Skalierens von Architekturgroße und Trainingsdaten verlockend, insbesondere angesichts der jährlich erzeugten Millionen von Stunden an chirurgischem Videomaterial. Andererseits erfordert die Aufbereitung chirurgischer Daten für das KI-Training ein deutlich höheres Maß an fachspezifischer Expertise, und das Training auf diesen Daten benötigt teure Rechenressourcen. Diese Zielkonflikte zeichnen ein unsicheres Bild darüber, inwieweit und ob moderne KI die chirurgische Praxis unterstützen kann. In diesem Beitrag untersuchen wir diese Frage anhand einer Fallstudie zur Erkennung chirurgischer Instrumente unter Verwendung der im Jahr 2026 verfügbaren State-of-the-Art-KI-Methoden. Wir zeigen, dass selbst Modelle mit mehreren Milliarden Parametern und umfangreichem Training bei der scheinbar einfachen Aufgabe der Instrumentenerkennung in der Neurochirurgie an Grenzen stoßen. Darüber hinaus präsentieren wir Skalierungsexperimente, die belegen, dass eine Vergrößerung der Modellgröße und eine längere Trainingsdauer nur zu abnehmenden Verbesserungen relevanter Leistungsmetriken führen. Unsere Experimente deuten somit darauf hin, dass aktuelle Modelle bei chirurgischen Anwendungsfällen nach wie vor erheblichen Hindernissen gegenüberstehen. Zudem lassen sich einige dieser Hindernisse nicht einfach durch zusätzliche Rechenleistung „wegskalieren"; sie persistieren über diverse Modellarchitekturen hinweg und werfen die Frage auf, ob Daten- und Labelverfügbarkeit die einzigen limitierenden Faktoren sind. Wir diskutieren die Hauptursachen für diese Einschränkungen und stellen potenzielle Lösungsansätze vor.
One-sentence Summary
Researchers from Chicago Booth and the Surgical Data Science Collective demonstrate that scaling Vision Language Models fails to solve surgical tool detection, revealing that specialized architectures like YOLOv12-m significantly outperform billion-parameter systems in neurosurgery and laparoscopy despite massive computational investment.
Key Contributions
- The paper evaluates zero-shot surgical tool detection across 19 open-weight Vision Language Models on the SDSC-EEA neurosurgical dataset, revealing that despite increased model scale, only one model marginally exceeds the majority class baseline.
- A specialized classification head replacing off-the-shelf JSON generation is introduced for fine-tuned Gemma 3 27B, achieving 51.08% exact match accuracy and outperforming the baseline and standard fine-tuning approaches.
- Experiments demonstrate that a specialized 26M-parameter YOLOv12-m model achieves 54.73% exact match accuracy, outperforming all tested Vision Language Models while using 1,000 times fewer parameters and generalizing effectively to the CholecT50 laparoscopic dataset.
Introduction
Surgical AI aims to create collaborative tools capable of integrating multimodal data and physical effects to assist in complex procedures, yet current systems struggle to match human performance on surgical image-analysis benchmarks. While the prevailing scaling hypothesis suggests that increasing model size and training data will solve these issues, prior work faces significant challenges including the high cost of data annotation, the need for specialized expertise, and the risk that simply adding compute cannot overcome domain-specific distribution shifts. The authors leverage a case study on surgical tool detection to demonstrate that even multi-billion parameter Vision Language Models fail to surpass trivial baselines in zero-shot settings and show diminishing returns when scaled, ultimately proving that specialized, smaller models like YOLOv12-m outperform large foundation models with far fewer parameters.
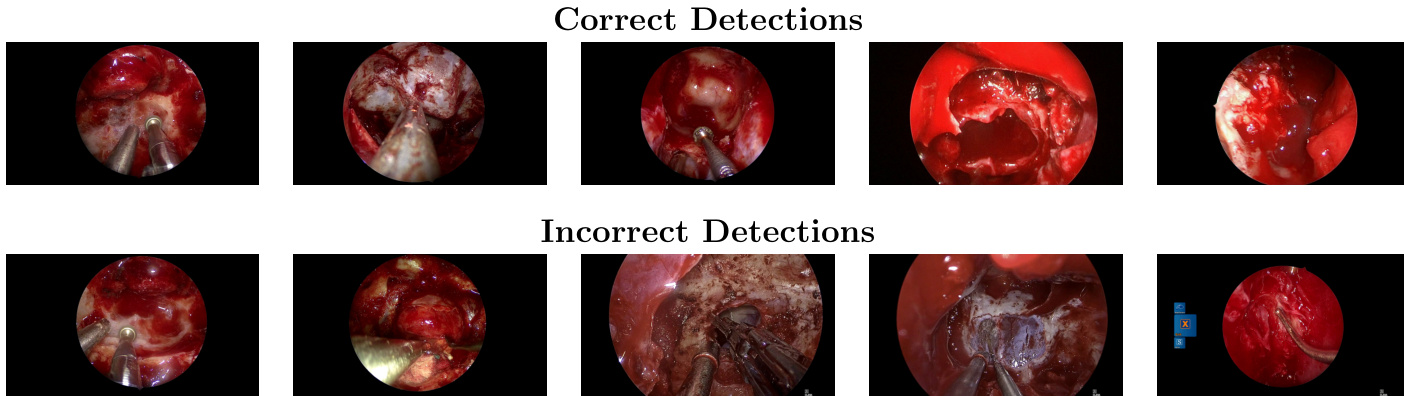
Dataset
-
Dataset Composition and Sources: The authors utilize the SDSC-EEA dataset, which contains 67,634 annotated frames extracted from 66 unique endoscopic endonasal approach (EEA) neurosurgical procedures. These video recordings were donated by 10 surgeons across 7 institutions in the United States, France, and Spain, with no exclusion criteria applied to the selection.
-
Key Details for Each Subset:
- Annotation Quality: Ground truth labels for 31 distinct surgical instrument classes were generated by three non-clinical annotators, reviewed by a senior annotator and SDSC members, with fewer than 10% of frames requiring correction.
- Format and Distribution: Annotations are provided in YOLO format with bounding boxes. The dataset shows significant class imbalance, with Suction appearing in 63.3% of frames, while other tools like Cotton Patty and Grasper appear less frequently.
- Split Strategy: To prevent data leakage, the data is split by surgical procedure rather than individual frames. This results in a training set of 47,618 frames from 53 procedures and a validation set of 20,016 frames from 13 procedures.
-
Usage in the Model:
- Fine-tuning: The training split is used for LoRA fine-tuning of the Vision-Language Model (VLM).
- Zero-Shot Evaluation: The authors evaluate zero-shot VLM performance using a specific prompt template that lists all 31 valid tool names and requires the model to return detected tools in a strict JSON format.
- External Validation: The methodology includes validation on the external CholecT50 dataset to assess generalizability.
-
Processing and Metadata Details:
- Data Leakage Prevention: The procedure-level split ensures that frames from the same surgery never appear in both training and validation sets, leading to uneven tool distributions across splits (e.g., the Sonopet pineapple tip appears only in the training set).
- Labeling Protocol: Annotators received tool descriptions and representative images prior to labeling to ensure consistency, and the final dataset includes multi-label ground truth indicating the presence or absence of instruments in each frame.
Experiment
- Zero-shot evaluation of 19 open-weight vision-language models across two years of development shows that even the largest models fail to surpass a trivial majority class baseline for surgical tool detection, indicating that general multimodal benchmark performance does not transfer to specialized surgical perception.
- Fine-tuning with LoRA adapters improves performance over zero-shot baselines, with a dedicated classification head outperforming autoregressive JSON generation, yet a persistent gap between training and validation accuracy reveals limited generalization to held-out procedures.
- Scaling LoRA adapter rank by nearly three orders of magnitude saturates training accuracy near 99% while validation accuracy remains below 40%, demonstrating that the performance bottleneck is caused by distribution shift rather than insufficient model capacity.
- A specialized 26M-parameter object detection model (YOLOv12-m) outperforms all fine-tuned vision-language models on the primary dataset while using over 1,000 times fewer parameters, suggesting that task-specific data and architecture are more critical than model scale.
- Replication on an independent laparoscopic dataset (CholecT50) confirms that zero-shot performance remains poor, fine-tuning is necessary for high accuracy, and smaller specialized models continue to outperform large foundation models, including proprietary frontier systems.
- The overall findings suggest that progress in surgical AI is currently constrained by the availability of large-scale, standardized domain-specific data rather than the scale of AI architectures, pointing toward hybrid systems that combine generalist models with specialized perception modules.