Command Palette
Search for a command to run...
Make It Up: Fake Images, Real Gains in Generalized Few-shot Semantic Segmentation
Make It Up: Fake Images, Real Gains in Generalized Few-shot Semantic Segmentation
Guohuan Xie Xin He Dingying Fan Le Zhang Ming-Ming Cheng Yun Liu
Zusammenfassung
Die generalisierte Few-Shot-Semantische Segmentierung (GFSS) ist grundlegend durch die Abdeckung neuartiger Klassen-Äußerlichkeiten bei knappen Annotationen limitiert. Zwar ermöglichen Diffusionsmodelle die skalierbare Synthese von Bildern neuartiger Klassen, doch praktische Gewinne werden häufig durch unzureichende Abdeckung und verrauschte Supervision behindert, wenn Masken nicht verfügbar oder unzuverlässig sind. Wir präsentieren Syn4Seg, ein generierungsverstärktes GFSS-Framework, das darauf abzielt, die Abdeckung neuartiger Klassen zu erweitern und gleichzeitig die Qualität von Pseudo-Labels zu verbessern. Syn4Seg maximiert zunächst die Abdeckung des Prompt-Raums, indem es für jede neuartige Klasse einen Embedding-deduplizierten Prompt-Bank konstruiert, wodurch diverse, aber klassenkonsistente synthetische Bilder erzeugt werden. Anschließend erfolgt eine support-gesteuerte Pseudo-Label-Schätzung durch eine zweistufige Verfeinerung, die i) Regionen mit geringer Konsistenz filtert, um hochpräzise Startpunkte (Seeds) zu erhalten, und ii) unsichere Pixel mit bildadaptiven Prototypen neu labelt, die globale (Support) und lokale (Bild-)Statistiken kombinieren. Abschließend werden ausschließlich Pixel im Randband und ungelabelte Pixel durch eine eingeschränkte, auf SAM basierende Aktualisierung verfeinert, um die Konturgenauigkeit zu erhöhen, ohne hochkonfidente Innenbereiche zu überschreiben. Umfassende Experimente auf PASCAL-5i und COCO-20i zeigen konsistente Verbesserungen sowohl im 1-Shot- als auch im 5-Shot-Setting und unterstreichen synthetische Daten als skalierbaren Weg für GFSS mit zuverlässigen Masken und präzisen Grenzen.
One-sentence Summary
Researchers from Nankai University and Tianjin University of Technology propose Syn4Seg, a framework that leverages Stable Diffusion to generate diverse novel-class images and employs support-guided pseudo-label refinement with SAM-based boundary correction, significantly enhancing Generalized Few-shot Semantic Segmentation performance on PASCAL-5i and COCO-20i benchmarks.
Key Contributions
- The paper introduces Syn4Seg, a generation-enhanced framework that constructs an embedding-deduplicated prompt bank to synthesize diverse, class-consistent novel-class images, thereby expanding coverage and improving generalization in Generalized Few-shot Semantic Segmentation.
- An Adaptive Pseudo-label Enhancement mechanism is presented to refine synthetic masks through a two-stage process that filters low-consistency regions and relabels uncertain pixels using image-adaptive prototypes, resulting in higher-quality supervision.
- A SAM-based Boundary Refinement module is developed to update only boundary-band and unlabeled pixels, which produces sharp, spatially coherent contours and boosts segmentation performance as demonstrated by consistent improvements on PASCAL-5i and COCO-20i benchmarks.
Introduction
Generalized few-shot semantic segmentation (GFSS) aims to segment both base and novel classes in a single inference pass, a capability critical for scalable deployment where pixel-level annotations are scarce. However, prior approaches struggle because novel classes rely on limited manual support examples, leading to poor intra-class diversity and weak generalization, while existing attempts to use Diffusion models for data augmentation often suffer from redundant image generation and noisy or misaligned segmentation masks. To overcome these hurdles, the authors propose Syn4Seg, a framework that constructs an embedding-deduplicated prompt bank to ensure diverse and class-consistent synthetic images, followed by a two-stage pseudo-label refinement process and a SAM-based boundary update to deliver high-quality supervision for robust segmentation.
Method
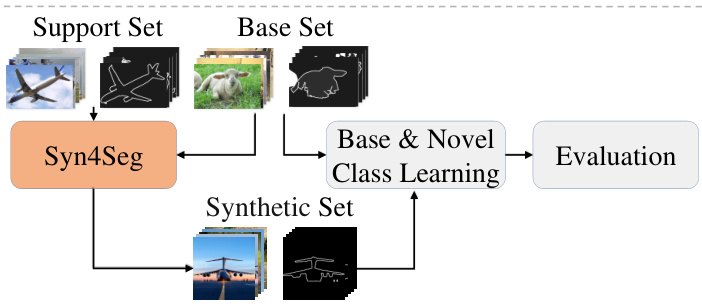
The authors propose the Syn4Seg framework to alleviate the shortage of novel class images in Generalized Few-Shot Segmentation (GFSS). The overall pipeline is illustrated in the framework diagram. The process begins with a Support Set and a Base Set. The Syn4Seg module synthesizes a Synthetic Set of novel class images. These synthetic images, along with the Base Set, are fed into a Base & Novel Class Learning module to train the final segmentation model, which is then evaluated.
To generate the synthetic images, the authors leverage High-quality Diverse Image Generation (HDIG). Direct use of class names often leads to limited diversity. HDIG addresses this by constructing a prompt set that is centered on the target class but semantically diverse. An iterative prompt generation strategy is employed where an agent generates candidate prompts. These prompts are encoded using the text encoder of Stable Diffusion 3.5-Large to ensure semantic alignment. A diversity threshold is applied to filter prompts based on cosine similarity. The maximum cosine similarity between the current candidate and existing entries is computed as: st,i=maxu∈Dt(i−1)φ~(pt,i)⊤u where φ~(p) is the normalized text embedding. A candidate prompt is accepted only if its similarity score is below a threshold λ, ensuring sufficient diversity. The accepted prompts are used to synthesize images. A qualitative comparison highlights the effectiveness of this approach, showing that HDIG produces images with substantially richer visual diversity while preserving class consistency compared to standard class-name prompts.
Once synthetic images are generated, the authors employ Adaptive Pseudo-label Enhancement (APE) to produce high-quality masks, as the initial masks from the GFSS network are often noisy. Refer to the detailed module diagram for the internal structure of APE. APE comprises two stages: Adaptive Pseudo-label Filtering (APF) and Adaptive Pseudo-label Relabeling (APR). In the APF stage, the method discards unreliable pseudo-labels by assessing the alignment between predicted regions and support prototypes. The prototype for novel class k is computed by averaging features over pixels labeled as k: μk=∑j∑p1[Mj(p)=k]1∑j∑p1[Mj(p)=k]fj(p) For a region r, the cosine similarity with the class prototype is calculated as s(r)=v^(r)⊤μ^k. If s(r)≥λ, the region is kept; otherwise, it is marked as free. In the APR stage, these free regions are adaptively relabeled using a blend of global support prototypes and image-local prototypes. The adaptive prototype for image x is given by: μ~k(x)=βμ^k+(1−β)μ^k(x) where β controls the influence of the global prototype. This ensures that the mask retains trustworthy labels while filling in uncertain areas with high-confidence predictions.
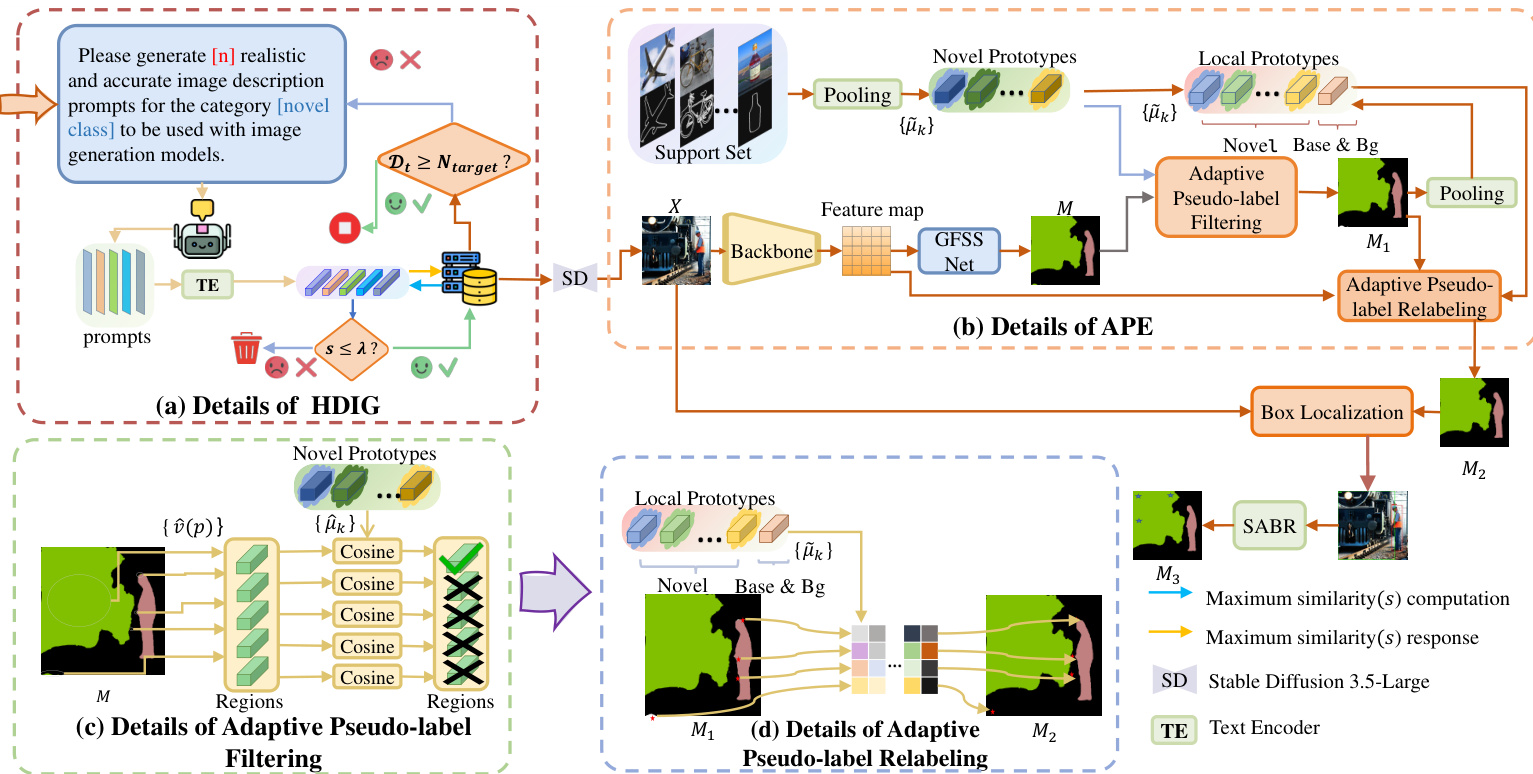
Finally, to address imprecise object boundaries, the authors apply SAM-based Boundary Refinement (SABR). This module utilizes the Segment Anything Model (SAM) to refine the mask boundaries. By identifying boundary pixels and computing tight bounding boxes, SAM is guided to produce binary foreground predictions. Updates are restricted to uncertain regions to prevent overwriting high-confidence interiors. This process yields the final training mask with substantially improved boundary fidelity, ready for downstream segmentation training.
Experiment
- Experiments on PASCAL-5i and COCO-20i benchmarks validate that the proposed Syn4Seg method significantly outperforms state-of-the-art approaches in both 1-shot and 5-shot settings, achieving superior mean and harmonic mIoU scores.
- Qualitative analysis demonstrates that the method generates more coherent and complete segmentation masks for novel classes while reducing fragmented predictions and spurious regions compared to existing techniques.
- Ablation studies confirm that enhancing image diversity through HDIG provides broader appearance cues, while the APE module improves mask precision by filtering misaligned regions and relabeling ambiguous areas.
- The inclusion of SABR effectively refines object boundaries and resolves local ambiguities, leading to the best overall segmentation consistency across base and novel classes.
- Hyperparameter analysis reveals that moderate values for prototype blending and thresholding optimize the balance between synthesized information and generalization, while the method remains robust to variations in boundary refinement parameters.
- Testing with a deeper ResNet-101 backbone shows consistent performance gains, indicating that stronger feature extraction benefits fine-grained detail capture without the method being overly dependent on backbone depth.