Command Palette
Search for a command to run...
TAPS: aufgabenbewusste Vorschlagsverteilungen für spekulatives Sampling
TAPS: aufgabenbewusste Vorschlagsverteilungen für spekulatives Sampling
Mohamad Zbib Mohamad Bazzi Ammar Mohanna Hasan Abed Al Kader Hammoud Bernard Ghanem
Zusammenfassung
Spekulatives Decodieren beschleunigt die autoregressive Generierung, indem ein leichtgewichtiges Draft-Modell zukünftige Tokens vorschlägt, die anschließend von einem größeren Target-Modell parallel verifiziert werden. In der Praxis werden Draft-Modelle jedoch üblicherweise auf breiten, generischen Korpora trainiert, wodurch unklar bleibt, inwieweit die Qualität des spekulativen Decodierens von der Trainingsverteilung des Draft-Modells abhängt. Wir untersuchen diese Frage anhand von leichten HASS- und EAGLE-2-Draftern, die auf MathInstruct, ShareGPT sowie Mischdaten-Varianten trainiert wurden, und evaluieren sie auf den Benchmarks MT-Bench, GSM8K, MATH-500 und SVAMP. Gemessen an der Akzeptanzlänge führt ein aufgaben spezifisches Training zu einer deutlichen Spezialisierung: Auf MathInstruct trainierte Drafts sind bei Reasoning-Benchmarks am stärksten, während auf ShareGPT trainierte Drafts bei MT-Bench überlegen sind. Ein Training mit Mischdaten verbessert die Robustheit, doch größere Mischungen dominieren nicht über alle Decodierungstemperaturen hinweg. Zudem untersuchen wir, wie spezialisierte Drafter zur Inferenzzeit kombiniert werden können. Eine naive Durchschnittebildung über Checkpoints erweist sich als wenig effektiv; hingegen verbessert ein routing auf Basis von Konfidenzwerten die Leistung gegenüber ein-domänigen Drafts, und eine verifizierte Merge-Tree-Verifikation erzielt für beide Backbones insgesamt die höchste Akzeptanzlänge. Schließlich ist Konfidenz ein nützlicheres Routing-Signal als Entropie: Zwar weisen abgelehnte Tokens tendenziell eine höhere Entropie auf, doch liefert die Konfidenz deutlich klarere Routing-Entscheidungen auf Benchmark-Ebene. Diese Ergebnisse zeigen, dass die Qualität des spekulativen Decodierens nicht nur von der Draft-Architektur abhängt, sondern auch von der Übereinstimmung zwischen den Trainingsdaten des Draft-Modells und der nachgelagerten Arbeitslast, und dass spezialisierte Drafter zur Inferenzzeit besser kombiniert werden können als im Weight Space.
One-sentence Summary
Researchers from KAUST and the American University of Beirut propose TAPS, demonstrating that task-specific training of HASS and EAGLE-2 drafters significantly boosts speculative decoding acceptance on matched workloads. Their work reveals that combining specialized models via confidence-based routing or merged-tree verification at inference time outperforms naive weight averaging, optimizing LLM throughput for diverse domains like math and conversation.
Key Contributions
- The paper introduces an empirical analysis showing that task-specific training of draft models yields clear specialization, where MathInstruct-trained drafters excel on reasoning benchmarks while ShareGPT-trained drafters perform best on MT-Bench.
- This work demonstrates that combining specialized drafters at inference time via confidence-based routing and merged-tree verification significantly outperforms naive weight-space averaging, achieving the highest acceptance length across both HASS and EAGLE-2 backbones.
- Results indicate that confidence serves as a more effective routing signal than entropy for making benchmark-level decisions, as rejected tokens exhibit higher entropy but confidence provides clearer distinctions for selecting the optimal drafter.
Introduction
Autoregressive generation in LLMs faces a significant inference bottleneck that speculative decoding addresses by using a lightweight drafter to propose tokens for parallel verification by a larger target model. While prior work focuses on improving draft architectures or verification procedures, most draft models are trained on broad generic corpora, leaving the impact of training data distribution on acceptance quality under-explored. The authors leverage task-specific training on datasets like MathInstruct and ShareGPT to demonstrate that specialized drafters significantly outperform generic ones on matched benchmarks. They further show that combining these specialists at inference time through confidence-based routing and merged-tree verification yields superior results compared to naive weight averaging or mixed-data training.
Method
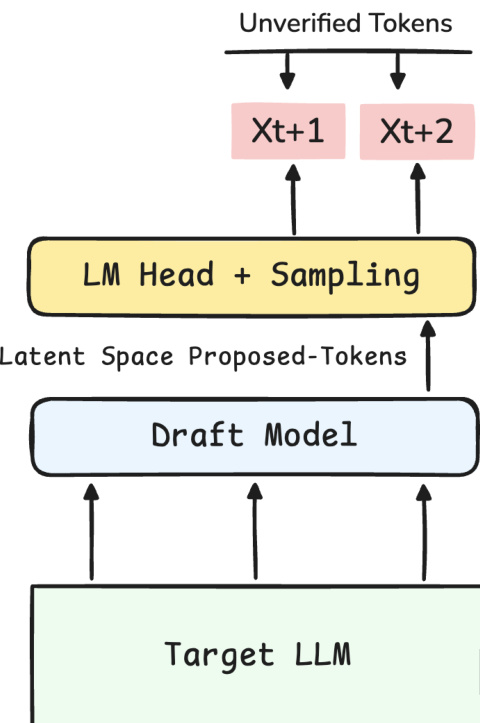
The authors leverage a speculative decoding framework where a lightweight draft model proposes future tokens for verification by a larger target LLM. As shown in the framework diagram, the process begins with the Target LLM providing context to the Draft Model. The draft model operates in latent space to propose tokens, which are then passed through an LM Head and sampling layer to generate unverified tokens like Xt+1 and Xt+2.
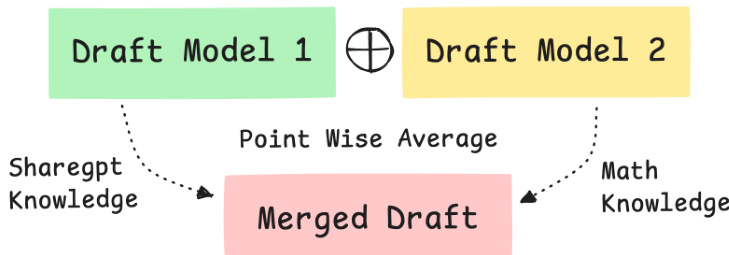
To enhance the quality of these drafts, the authors explore composition strategies for specialized models. One baseline approach is checkpoint averaging. As illustrated in the figure below, parameters from distinct draft models, such as one trained on ShareGPT data and another on Math data, are combined via point-wise averaging to create a single merged draft model.
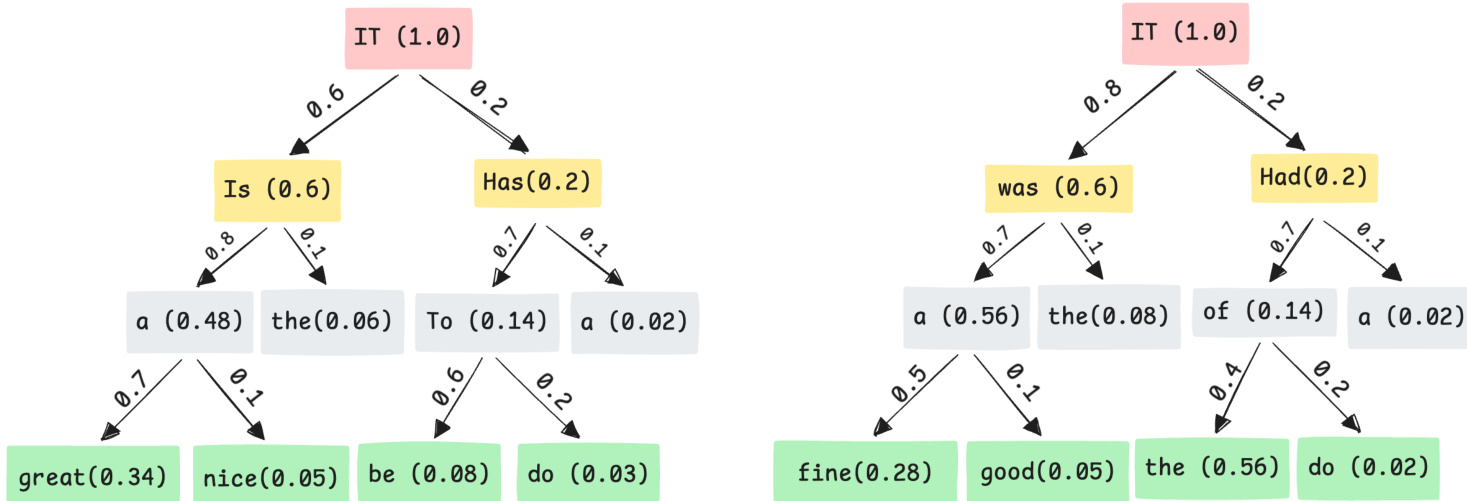
Alternatively, the authors investigate inference-time composition strategies that maintain separate specialized checkpoints. In this setting, specialized models generate distinct candidate continuations with associated confidence scores, as depicted in the tree diagrams showing separate branches for different experts.
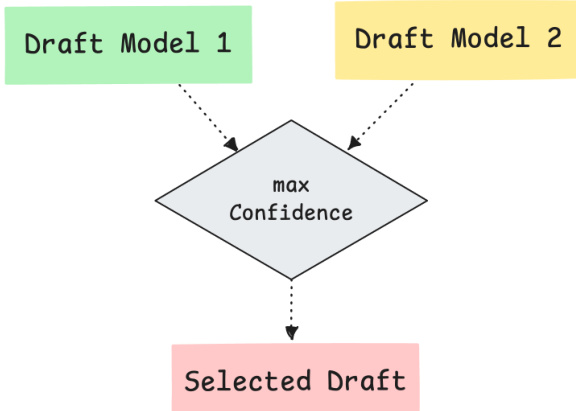
For inference-time selection, the authors propose confidence routing. This method generates separate draft trees from different checkpoints and selects the tree with the higher mean node confidence before verification, as shown in the routing diagram where the max confidence path is chosen.
A more comprehensive strategy is merged-tree verification. Instead of selecting a single tree, the method packs multiple draft trees under a shared root. This allows the verifier to evaluate candidates from all specialists in a single parallel pass. The flattened merged-tree input preserves ancestry through tree attention masks and depth-based position ids, enabling the verifier to process both specialized subtrees without cross-subtree attention.
Experiment
- Single-domain training validates that drafters achieve significantly higher acceptance lengths when their training distribution matches the target workload, with mathematical models excelling on reasoning tasks and conversational models on dialogue benchmarks.
- Mixed-data training demonstrates that combining domains improves cross-domain robustness, though the optimal mixture ratio depends on the decoding temperature and does not guarantee uniform generalization.
- Inference-time composition strategies, specifically confidence-based routing and merged-tree verification, substantially outperform weight-space averaging, proving that keeping specialized models separate and combining them at runtime is more effective than merging parameters.
- Analysis of confidence, entropy, and speculative depth reveals that confidence is the superior signal for routing between specialists, while deeper speculative steps increasingly favor task-matched experts over broad-coverage models.
- The overall conclusion establishes that proposal quality in speculative decoding is a function of both architecture and training distribution, necessitating task-aware drafting and dynamic composition rather than static, averaged checkpoints.